Mahout源码MeanShiftCanopyDriver分析之三MeanShiftCanopyReducer数据逻辑流
首先贴上MeanShiftCanopyReducer的仿造代码,如下:
package mahout.fansy.meanshift;
import java.io.IOException;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.clustering.meanshift.MeanShiftCanopy;
import org.apache.mahout.clustering.meanshift.MeanShiftCanopyClusterer;
import org.apache.mahout.clustering.meanshift.MeanShiftCanopyConfigKeys;
import com.google.common.collect.Lists;
public class MeanShiftCanopyReducerFollow {
/**
* MeanShiftCanopyReducer仿造代码
* @author fansy
* @param args
*/
// private static int convergedClusters=0;
private static boolean allConverged = true;
public static void main(String[] args) {
// cleanup();// 调试cleanup函数
reduce(); // 调试reduce函数
}
/**
* 仿造reduce操作
*/
public static Map<Text,Collection<ClusterWritable>> reduce(){
Collection<MeanShiftCanopy> canopies = Lists.newArrayList();
// 获得map的输出
Collection<ClusterWritable >values =MeanShiftCanopyMapperFollow.cleanup().get(new Text("0"));
MeanShiftCanopyClusterer clusterer=setup();
Collection<ClusterWritable> v=Lists.newArrayList();
for (ClusterWritable clusterWritable : values) {
MeanShiftCanopy canopy = (MeanShiftCanopy)clusterWritable.getValue();
clusterer.mergeCanopy(canopy.shallowCopy(), canopies);
}
Map<Text,Collection<ClusterWritable>> map =new HashMap<Text,Collection<ClusterWritable>>();
for (MeanShiftCanopy canopy : canopies) {
boolean converged = clusterer.shiftToMean(canopy);
if (converged) {
// System.out.println("Clustering"+ " Converged Clusters"+convergedClusters++);
}
allConverged = converged && allConverged;
ClusterWritable clusterWritable = new ClusterWritable();
clusterWritable.setValue(canopy);
v.add(clusterWritable);
map.put(new Text(canopy.getIdentifier()), v);
// System.out.println("key:"+canopy.getIdentifier()+",value:"+clusterWritable.getValue().toString());
}
// map.put(new Text(canopy.getIdentifier()), v);
return map;
}
/**
* 仿造setup函数,直接调用MapperFollow的方法
* @return 返回经过设置值的MeanShiftCanopyClusterer
*/
public static MeanShiftCanopyClusterer setup(){
return MeanShiftCanopyMapperFollow.setup();
}
/**
* 仿造cleanup函数
* @throws IOException
*/
public static void cleanup() throws IOException{
// int numReducers=1; // 自己设定,这里为了方便直接设置为1
Configuration conf=getConf();
// 判断是否全部都满足准则阈值要求,满足,则新建文件;
if (allConverged) {
Path path = new Path(conf.get(MeanShiftCanopyConfigKeys.CONTROL_PATH_KEY));
FileSystem.get(path.toUri(), conf).createNewFile(path);
}
}
/**
* 获得配置过的configuration
* @return
*/
public static Configuration getConf(){
String measureClassName="org.apache.mahout.common.distance.EuclideanDistanceMeasure";
String kernelProfileClassName="org.apache.mahout.common.kernel.TriangularKernelProfile";
double convergenceDelta=0.5;
double t1=47.6;
double t2=1;
boolean runClustering=true;
Configuration conf =new Configuration();
conf.set(MeanShiftCanopyConfigKeys.DISTANCE_MEASURE_KEY, measureClassName);
conf.set(MeanShiftCanopyConfigKeys.KERNEL_PROFILE_KEY,
kernelProfileClassName);
conf.set(MeanShiftCanopyConfigKeys.CLUSTER_CONVERGENCE_KEY, String
.valueOf(convergenceDelta));
conf.set(MeanShiftCanopyConfigKeys.T1_KEY, String.valueOf(t1));
conf.set(MeanShiftCanopyConfigKeys.T2_KEY, String.valueOf(t2));
conf.set(MeanShiftCanopyConfigKeys.CLUSTER_POINTS_KEY, String
.valueOf(runClustering));
return conf;
}
/**
* 获得map的输出数据,即canopies
* @return Map<Text, ClusterWritable> canpies
*/
public static Map<Text, Collection<ClusterWritable>> getMapData(){
return MeanShiftCanopyMapperFollow.cleanup();
}
}
这里的setup函数和之前mapper中的一样,这里不再分析。cleanup函数也只是当满足准则阈值时新建一个函数而已,这里也不再多说,主要分析reduce函数(其实主要代码和mapper中的map+cleanup函数差不多)。
map输出的前面3条记录如下:
MSC-0{n=100 c=[29.942, 30.443, 30.325, 30.018, 29.887, 29.777, 29.855, 29.883, 30.128, 29.984, 29.796, 29.845, 30.436, 29.729, 29.890, 29.518, 29.546, 30.052, 30.077, 30.001, 29.837, 29.928, 30.288, 30.347, 29.785, 29.799, 29.651, 30.008, 29.938, 30.104, 29.997, 29.684, 29.949, 29.754, 30.272, 30.106, 29.883, 30.221, 29.847, 29.848, 29.843, 30.577, 29.870, 29.785, 29.923, 29.864, 30.184, 29.977, 30.321, 30.068, 30.570, 30.224, 30.240, 29.969, 30.246, 30.544, 29.862, 30.099, 29.907, 30.169] r=[3.384, 3.383, 3.494, 3.523, 3.308, 3.605, 3.315, 3.518, 3.472, 3.519, 3.350, 3.444, 3.273, 3.274, 3.400, 3.443, 3.426, 3.499, 3.154, 3.506, 3.509, 3.436, 3.484, 3.475, 3.360, 3.164, 3.460, 3.491, 3.608, 3.484, 3.477, 3.748, 3.628, 3.378, 3.327, 3.600, 3.455, 3.562, 3.534, 3.566, 3.213, 3.645, 3.615, 3.274, 3.197, 3.373, 3.595, 3.452, 3.609, 3.518, 3.262, 3.477, 3.755, 3.830, 3.494, 3.676, 3.423, 3.491, 3.641, 3.374]}
MSC-1{n=101 c=[29.890, 30.422, 30.280, 30.046, 29.891, 29.805, 29.828, 29.875, 30.133, 30.035, 29.773, 29.900, 30.441, 29.751, 29.906, 29.490, 29.508, 30.013, 30.082, 30.049, 29.815, 29.934, 30.286, 30.294, 29.828, 29.831, 29.712, 30.005, 29.977, 30.128, 30.015, 29.675, 29.963, 29.766, 30.259, 30.095, 29.855, 30.139, 29.704, 29.797, 29.808, 30.530, 29.743, 29.745, 29.883, 29.741, 30.140, 29.935, 30.271, 29.934, 30.437, 30.184, 30.180, 29.823, 30.146, 30.494, 29.767, 30.061, 29.854, 30.130] r=[3.407, 3.373, 3.506, 3.517, 3.292, 3.598, 3.310, 3.502, 3.455, 3.538, 3.341, 3.471, 3.257, 3.265, 3.387, 3.437, 3.430, 3.504, 3.139, 3.522, 3.499, 3.419, 3.466, 3.497, 3.371, 3.165, 3.496, 3.474, 3.610, 3.475, 3.464, 3.730, 3.613, 3.363, 3.313, 3.584, 3.449, 3.639, 3.797, 3.585, 3.215, 3.658, 3.818, 3.282, 3.205, 3.573, 3.605, 3.460, 3.626, 3.748, 3.507, 3.482, 3.784, 4.079, 3.616, 3.692, 3.535, 3.495, 3.663, 3.380]}
MSC-2{n=100 c=[29.942, 30.443, 30.325, 30.018, 29.887, 29.777, 29.855, 29.883, 30.128, 29.984, 29.796, 29.845, 30.436, 29.729, 29.890, 29.518, 29.546, 30.052, 30.077, 30.001, 29.837, 29.928, 30.288, 30.347, 29.785, 29.799, 29.651, 30.008, 29.938, 30.104, 29.997, 29.684, 29.949, 29.754, 30.272, 30.106, 29.883, 30.221, 29.847, 29.848, 29.843, 30.577, 29.870, 29.785, 29.923, 29.864, 30.184, 29.977, 30.321, 30.068, 30.570, 30.224, 30.240, 29.969, 30.246, 30.544, 29.862, 30.099, 29.907, 30.169] r=[3.384, 3.383, 3.494, 3.523, 3.308, 3.605, 3.315, 3.518, 3.472, 3.519, 3.350, 3.444, 3.273, 3.274, 3.400, 3.443, 3.426, 3.499, 3.154, 3.506, 3.509, 3.436, 3.484, 3.475, 3.360, 3.164, 3.460, 3.491, 3.608, 3.484, 3.477, 3.748, 3.628, 3.378, 3.327, 3.600, 3.455, 3.562, 3.534, 3.566, 3.213, 3.645, 3.615, 3.274, 3.197, 3.373, 3.595, 3.452, 3.609, 3.518, 3.262, 3.477, 3.755, 3.830, 3.494, 3.676, 3.423, 3.491, 3.641, 3.374]}前面的准备工作做好后可以直接进入clusterer.mergeCanopy(canopy.shallowCopy(), canopies);方法来看,这里的分析和前面的mapper中的一样,第一行输入是一样的,但是第二行的输入却不同了,第二行的输入和canopies(1)的norm是0.44<t1 且0.44<t2,则要进入这里:
if (norm < t2 && (closestCoveringCanopy == null || norm < closestNorm)) {
closestNorm = norm;
closestCoveringCanopy = canopy;
}然后接下来就应该要进入else中了,而非if中,如下:
if (closestCoveringCanopy == null) {
canopies.add(aCanopy);
} else {
closestCoveringCanopy.merge(aCanopy, runClustering);
}这里的merge只是把相应的canopies(1)(这里的1可能是其他数字,针对前面几条数据,这里都是1)的boundPoints、mass的值,比如当canopies(1)中有三个值的时候,mass就为4,boundPoints为[0, 1, 2, 3]。这里的merge函数比较好理解点。
现在返回到前面的touch函数,我觉得这个函数不是很好理解;看到这个函数的详细代码如下:
void touch(MeanShiftCanopy canopy, double weight) {
canopy.observe(getCenter(), weight * mass);
observe(canopy.getCenter(), weight * canopy.mass);
}调用方式为:aCanopy.touch(canopy, weight);其中,aCanopy为输入的一条记录,canopy为canopies(i)中的一个;
针对上面代码中的两条操作其实都是设置s0、s1和s2的:第一句把canopy的s0+1,由于aCanopy的mass为始终为1,所以canopy的s1就是把当前的s1+aCanopy的center,(s2的计算有点复杂,暂时不关注,其实和s1差不多,只是计算复杂点);第二句把aCanopy(它的s0、s1、s2都是空的)的s1通过canopies(1)的center值*canopies(1)的mass值得到,s0的值设置为mass值;
其实针对上面的设置canopies(1)的s0、s1、s2我是理解的,因为在后面要使用到,但是为什么要设置aCanopy的s0、s1、s2呢?表示不理解,后面用到aCanopy的地方也只是merge函数而已,这个函数用到的也只是aCanopy的boundPoints和mass值而已并没有用到s0、s1和s2,所以这里不是很理解。额,好吧,好像在add方法中也用到了aCanopy,当closesCoveringCanopy为空的时候,即要新建一个canopies(i)的时候是有用的。
这样在reduce的输出中就可以输出479个值了,和第一篇博客中说第一次循环得到的reduce的输出个数是479是一样的,如下:
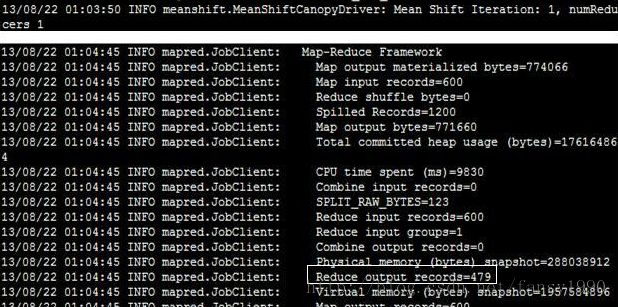
这样MeanShiftCanopyDriver的基本分析就ok了。
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990