如何基于新API使用Hadoop的Reduce Side Join
上篇,散仙介绍了基于Hadoop的旧版API结合DataJoin工具类和MapReduce实现的侧连接,那么本次,散仙就来看下,如何在新版API(散仙的Hadoop是1.2版本,在2.x的hadoop版本里实现代码一样)中实现一个Reduce Side Join,在这之前,我们还是先来温故下Reduce侧连接的实现原理:
在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下:
Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
reduce端的主要工作:在reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
测试数据,依旧是上次使用的数据:
代码如下:
运行日志如下:
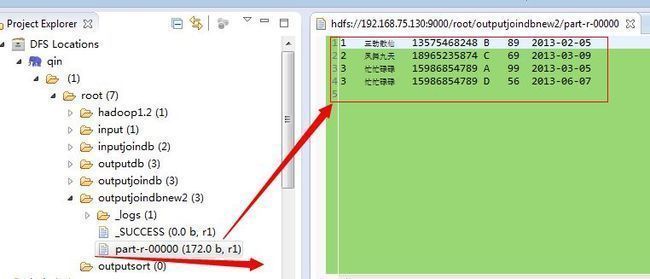
运行完的数据截图如下:
至此,我们在新版API中也准确,实现了Reduce的侧连接,需要注意的是Reduce侧连接的不足之处:
之所以会存在reduce join这种方式,我们可以很明显的看出原:因为整体数据被分割了,每个map task只处理一部分数据而不能够获取到所有需要的join字段,因此我们需要在讲join key作为reduce端的分组将所有join key相同的记录集中起来进行处理,所以reduce join这种方式就出现了。这种方式的缺点很明显就是会造成map和reduce端也就是shuffle阶段出现大量的数据传输,效率很低。
另外一点需要注意的是,散仙在eclipse里进行调试,Local模式下会报异常,建议提交到hadoop的测试集群上进行测试。
在Reudce端进行连接是MapReduce框架进行表之间join操作最为常见的模式,其具体的实现原理如下:
Map端的主要工作:为来自不同表(文件)的key/value对打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。
reduce端的主要工作:在reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行笛卡尔只就ok了。
测试数据,依旧是上次使用的数据:
a文件的数据 1,三劫散仙,13575468248 2,凤舞九天,18965235874 3,忙忙碌碌,15986854789 4,少林寺方丈,15698745862
b文件的数据 3,A,99,2013-03-05 1,B,89,2013-02-05 2,C,69,2013-03-09 3,D,56,2013-06-07
代码如下:
package com.qin.reducejoin;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/***
*
* Hadoop1.2的版本,新版本API实现的Reduce侧连接
*
* @author qindongliang
*
* 大数据交流群:376932160
* 搜索技术交流群:324714439
*
*
*
* **/
public class NewReduceJoin2 {
/**
*
*
* 自定义一个输出实体
*
* **/
private static class CombineEntity implements WritableComparable<CombineEntity>{
private Text joinKey;//连接key
private Text flag;//文件来源标志
private Text secondPart;//除了键外的其他部分的数据
public CombineEntity() {
// TODO Auto-generated constructor stub
this.joinKey=new Text();
this.flag=new Text();
this.secondPart=new Text();
}
public Text getJoinKey() {
return joinKey;
}
public void setJoinKey(Text joinKey) {
this.joinKey = joinKey;
}
public Text getFlag() {
return flag;
}
public void setFlag(Text flag) {
this.flag = flag;
}
public Text getSecondPart() {
return secondPart;
}
public void setSecondPart(Text secondPart) {
this.secondPart = secondPart;
}
@Override
public void readFields(DataInput in) throws IOException {
this.joinKey.readFields(in);
this.flag.readFields(in);
this.secondPart.readFields(in);
}
@Override
public void write(DataOutput out) throws IOException {
this.joinKey.write(out);
this.flag.write(out);
this.secondPart.write(out);
}
@Override
public int compareTo(CombineEntity o) {
// TODO Auto-generated method stub
return this.joinKey.compareTo(o.joinKey);
}
}
private static class JMapper extends Mapper<LongWritable, Text, Text, CombineEntity>{
private CombineEntity combine=new CombineEntity();
private Text flag=new Text();
private Text joinKey=new Text();
private Text secondPart=new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
//获得文件输入路径
String pathName = ((FileSplit) context.getInputSplit()).getPath().toString();
if(pathName.endsWith("a.txt")){
String valueItems[]=value.toString().split(",");
//设置标志位
flag.set("0");
//设置链接键
joinKey.set(valueItems[0]);
//设置第二部分
secondPart.set(valueItems[1]+"\t"+valueItems[2]);
//封装实体
combine.setFlag(flag);//标志位
combine.setJoinKey(joinKey);//链接键
combine.setSecondPart(secondPart);//其他部分
//写出
context.write(combine.getJoinKey(), combine);
}else if(pathName.endsWith("b.txt")){
String valueItems[]=value.toString().split(",");
//设置标志位
flag.set("1");
//设置链接键
joinKey.set(valueItems[0]);
//设置第二部分注意不同的文件的列数不一样
secondPart.set(valueItems[1]+"\t"+valueItems[2]+"\t"+valueItems[3]);
//封装实体
combine.setFlag(flag);//标志位
combine.setJoinKey(joinKey);//链接键
combine.setSecondPart(secondPart);//其他部分
//写出
context.write(combine.getJoinKey(), combine);
}
}
}
private static class JReduce extends Reducer<Text, CombineEntity, Text, Text>{
//存储一个分组中左表信息
private List<Text> leftTable=new ArrayList<Text>();
//存储一个分组中右表信息
private List<Text> rightTable=new ArrayList<Text>();
private Text secondPart=null;
private Text output=new Text();
//一个分组调用一次
@Override
protected void reduce(Text key, Iterable<CombineEntity> values,Context context)
throws IOException, InterruptedException {
leftTable.clear();//清空分组数据
rightTable.clear();//清空分组数据
/**
* 将不同文件的数据,分别放在不同的集合
* 中,注意数据量过大时,会出现
* OOM的异常
*
* **/
for(CombineEntity ce:values){
this.secondPart=new Text(ce.getSecondPart().toString());
//左表
if(ce.getFlag().toString().trim().equals("0")){
leftTable.add(secondPart);
}else if(ce.getFlag().toString().trim().equals("1")){
rightTable.add(secondPart);
}
}
//=====================
for(Text left:leftTable){
for(Text right:rightTable){
output.set(left+"\t"+right);//连接左右数据
context.write(key, output);//输出
}
}
}
}
public static void main(String[] args)throws Exception {
//Job job=new Job(conf,"myjoin");
JobConf conf=new JobConf(NewReduceJoin2.class);
conf.set("mapred.job.tracker","192.168.75.130:9001");
conf.setJar("tt.jar");
Job job=new Job(conf, "2222222");
job.setJarByClass(NewReduceJoin2.class);
System.out.println("模式: "+conf.get("mapred.job.tracker"));;
//设置Map和Reduce自定义类
job.setMapperClass(JMapper.class);
job.setReducerClass(JReduce.class);
//设置Map端输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CombineEntity.class);
//设置Reduce端的输出
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileSystem fs=FileSystem.get(conf);
Path op=new Path("hdfs://192.168.75.130:9000/root/outputjoindbnew2");
if(fs.exists(op)){
fs.delete(op, true);
System.out.println("存在此输出路径,已删除!!!");
}
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.75.130:9000/root/inputjoindb"));
FileOutputFormat.setOutputPath(job, op);
System.exit(job.waitForCompletion(true)?0:1);
}
}
运行日志如下:
模式: 192.168.75.130:9001 存在此输出路径,已删除!!! WARN - JobClient.copyAndConfigureFiles(746) | Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. INFO - FileInputFormat.listStatus(237) | Total input paths to process : 2 INFO - NativeCodeLoader.<clinit>(43) | Loaded the native-hadoop library WARN - LoadSnappy.<clinit>(46) | Snappy native library not loaded INFO - JobClient.monitorAndPrintJob(1380) | Running job: job_201404222310_0026 INFO - JobClient.monitorAndPrintJob(1393) | map 0% reduce 0% INFO - JobClient.monitorAndPrintJob(1393) | map 50% reduce 0% INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 0% INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 33% INFO - JobClient.monitorAndPrintJob(1393) | map 100% reduce 100% INFO - JobClient.monitorAndPrintJob(1448) | Job complete: job_201404222310_0026 INFO - Counters.log(585) | Counters: 29 INFO - Counters.log(587) | Job Counters INFO - Counters.log(589) | Launched reduce tasks=1 INFO - Counters.log(589) | SLOTS_MILLIS_MAPS=10742 INFO - Counters.log(589) | Total time spent by all reduces waiting after reserving slots (ms)=0 INFO - Counters.log(589) | Total time spent by all maps waiting after reserving slots (ms)=0 INFO - Counters.log(589) | Launched map tasks=2 INFO - Counters.log(589) | Data-local map tasks=2 INFO - Counters.log(589) | SLOTS_MILLIS_REDUCES=9738 INFO - Counters.log(587) | File Output Format Counters INFO - Counters.log(589) | Bytes Written=172 INFO - Counters.log(587) | FileSystemCounters INFO - Counters.log(589) | FILE_BYTES_READ=237 INFO - Counters.log(589) | HDFS_BYTES_READ=415 INFO - Counters.log(589) | FILE_BYTES_WRITTEN=166329 INFO - Counters.log(589) | HDFS_BYTES_WRITTEN=172 INFO - Counters.log(587) | File Input Format Counters INFO - Counters.log(589) | Bytes Read=187 INFO - Counters.log(587) | Map-Reduce Framework INFO - Counters.log(589) | Map output materialized bytes=243 INFO - Counters.log(589) | Map input records=8 INFO - Counters.log(589) | Reduce shuffle bytes=243 INFO - Counters.log(589) | Spilled Records=16 INFO - Counters.log(589) | Map output bytes=215 INFO - Counters.log(589) | Total committed heap usage (bytes)=336338944 INFO - Counters.log(589) | CPU time spent (ms)=1520 INFO - Counters.log(589) | Combine input records=0 INFO - Counters.log(589) | SPLIT_RAW_BYTES=228 INFO - Counters.log(589) | Reduce input records=8 INFO - Counters.log(589) | Reduce input groups=4 INFO - Counters.log(589) | Combine output records=0 INFO - Counters.log(589) | Physical memory (bytes) snapshot=441524224 INFO - Counters.log(589) | Reduce output records=4 INFO - Counters.log(589) | Virtual memory (bytes) snapshot=2184306688 INFO - Counters.log(589) | Map output records=8
运行完的数据截图如下:
至此,我们在新版API中也准确,实现了Reduce的侧连接,需要注意的是Reduce侧连接的不足之处:
之所以会存在reduce join这种方式,我们可以很明显的看出原:因为整体数据被分割了,每个map task只处理一部分数据而不能够获取到所有需要的join字段,因此我们需要在讲join key作为reduce端的分组将所有join key相同的记录集中起来进行处理,所以reduce join这种方式就出现了。这种方式的缺点很明显就是会造成map和reduce端也就是shuffle阶段出现大量的数据传输,效率很低。
另外一点需要注意的是,散仙在eclipse里进行调试,Local模式下会报异常,建议提交到hadoop的测试集群上进行测试。