图解Hadoop1.2.1容量调度器的配置
资源调度器是Hadoop集群中一个比较重要的模块,最初的hadoop资源调度器是基于队列形式的FIFO调度的,这种模式在大规模集群的时候,资源分配并不是很合理,比如一个后提交的任务,但想要它先执行怎么办,而在FIFO模式下,只能等到前面所有的JOB执行完后,才能执行这个作业。所以如何进行资源的合理管理和分配,就成了一个急待解决的需求,由此就产生了后来的二个非常优秀的调度器分别是Yahoo!开源的CapacityScheduler(容量调度器)和Facebook开源的FairScheduler(公平调度器),在Hadoop2.x中,基于YARN平台的资源调度又对这三种调度器进行了整合,封装和重写,由此来统一YARN平台的资源调度和分配,大大简化了管理员对资源调度的操作和控制。
下面给出一个资料图看下这三个调度器之间的异同点
总结如下:
FifoScheduler:最简单的调度器,按照先进先出的方式处理应用。只有一个队列可提交应用,所有用户提交到这个队列。可以针对这个队列设置ACL。没有应用优先级可以配置。
CapacityScheduler:可以看作是FifoScheduler的多队列版本。每个队列可以限制资源使用量。但是,队列间的资源分配以使用量作排列依据,使得容量小的队列有竞争优势。集群整体吞吐较大。延迟调度机制使得应用可以放弃,夸机器或者夸机架的调度机会,争取本地调度。
FairScheduler:多队列,多用户共享资源。特有的客户端创建队列的特性,使得权限控制不太完美。根据队列设定的最小共享量或者权重等参数,按比例共享资源。延迟调度机制跟CapacityScheduler的目的类似,但是实现方式稍有不同。资源抢占特性,是指调度器能够依据公平资源共享算法,计算每个队列应得的资源,将超额资源的队列的部分容器释放掉的特性。
下面进入正题,散仙配置的是CapacityScheduler也就是容量调度器,环境是Centos6.4,hadoop1.2的版本,关于集群的搭建,在这里就不多涉及了,有兴趣的朋友,可以参考散仙的前几篇博客。
配置容量调度器,总结一下,有这么几步需要配置
1,在Master节点上的mapred-site.xml里面引用调度类,并配置队列名字
2,在Master节点上的capacity-scheduler.xml里面配置资源分配的大小
3,如果是在集群模式下,使用scp -r命令拷贝这个文件同步到所有的slave节点上
4,开启动态更新命令,bin/hadoop dfsadmin -refreshQueues,这样就可以动态修改集群的队列及其容量配置,不需要重启整个集群。
下面给出配置截图,散仙配置的是4个队列,命名依次为a,b,c,d
mapred-site.xml里面的配置
capacity-scheduler.xml里面的核心配置,截图如下
配置完成之后,同步到整个集群,然后开启动态更新命令,就可以启动集群,访问50030端口在web监控页面上看到队列的资源分配情况。
截图如下:

至此,容量调度器已经成功配置,在使用的时候,就可以根据作业的优先级对应提交到不用的队列上来合理的获取系统资源。
最后,散仙在总结一下,配置过程中遇到的一个问题。散仙原来的集群使用的是hadoop默认的tmp的路径,结果在集群启动时,有时会出现datanode无法启动的BUG,查看log日志,报了如下的异常信息:
注意如下一段异常
这个异常的产生,很大的关系跟tmp目录有联系,所以散仙建议,还是在hadoop目录下,新建一个tmp专门存放hadoop的格式信息,如果是已经在hadoop目录下有的tmp目录,还出现datanode无法正常启动的情况,需要我们关闭集群服务,进入tmp文件夹下,执行命令,rm -rf * 删除所有的文件,在重新格式化namenode,并重启集群就可以了。
下面给出一个资料图看下这三个调度器之间的异同点
| 对比选项 | FifoScheduler | CapacityScheduler | FairScheduler |
| 设计目的 | 最简单的调度器,易于理解和上手 | 多用户的情况下,最大化集群的吞吐和利用率 | 多用户的情况下,强调用户公平地贡献资源 |
| 队列组织方式 | 单队列 | 树状组织队列。无论父队列还是子队列都会有资源参数限制,子队列的资源限制计算是基于父队列的。应用提交到叶子队列。 | 树状组织队列。但是父队列和子队列没有参数继承关系。父队列的资源限制对子队列没有影响。应用提交到叶子队列。 |
| 资源限制 | 无 | 父子队列之间有容量关系。每个队列限制了资源使用量,全局最大资源使用量,最大活跃应用数量等。 | 每个叶子队列有最小共享量,最大资源量和最大活跃应用数量。用户有最大活跃应用数量的全局配置。 |
| 队列ACL限制 | 可以限制应用提交权限 | 可以限制应用提交权限和队列开关权限,父子队列间的ACL会继承。 | 可以限制应用提交权限,父子队列间的ACL会继承。但是由于支持客户端动态创建队列,需要限制默认队列的应用数量。目前,还看不到关闭动态创建队列的选项。 |
| 队列排序算法 | 无 | 按照队列的资源使用量最小的优先 | 根据公平排序算法排序 |
| 应用选择算法 | 先进先出 | 先进先出 | 先进先出或者公平排序算法 |
| 本地优先分配 | 支持 | 支持 | 支持 |
| 延迟调度 | 不支持 | 不支持 | 支持 |
| 资源抢占 | 不支持 | 不支持 | 支持 |
总结如下:
FifoScheduler:最简单的调度器,按照先进先出的方式处理应用。只有一个队列可提交应用,所有用户提交到这个队列。可以针对这个队列设置ACL。没有应用优先级可以配置。
CapacityScheduler:可以看作是FifoScheduler的多队列版本。每个队列可以限制资源使用量。但是,队列间的资源分配以使用量作排列依据,使得容量小的队列有竞争优势。集群整体吞吐较大。延迟调度机制使得应用可以放弃,夸机器或者夸机架的调度机会,争取本地调度。
FairScheduler:多队列,多用户共享资源。特有的客户端创建队列的特性,使得权限控制不太完美。根据队列设定的最小共享量或者权重等参数,按比例共享资源。延迟调度机制跟CapacityScheduler的目的类似,但是实现方式稍有不同。资源抢占特性,是指调度器能够依据公平资源共享算法,计算每个队列应得的资源,将超额资源的队列的部分容器释放掉的特性。
下面进入正题,散仙配置的是CapacityScheduler也就是容量调度器,环境是Centos6.4,hadoop1.2的版本,关于集群的搭建,在这里就不多涉及了,有兴趣的朋友,可以参考散仙的前几篇博客。
配置容量调度器,总结一下,有这么几步需要配置
1,在Master节点上的mapred-site.xml里面引用调度类,并配置队列名字
2,在Master节点上的capacity-scheduler.xml里面配置资源分配的大小
3,如果是在集群模式下,使用scp -r命令拷贝这个文件同步到所有的slave节点上
4,开启动态更新命令,bin/hadoop dfsadmin -refreshQueues,这样就可以动态修改集群的队列及其容量配置,不需要重启整个集群。
下面给出配置截图,散仙配置的是4个队列,命名依次为a,b,c,d
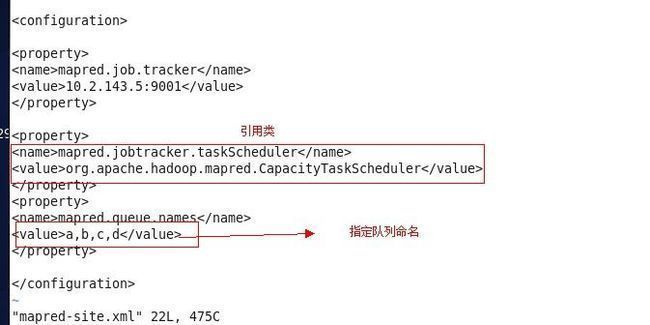
mapred-site.xml里面的配置
<configuration> <property> <name>mapred.job.tracker</name> <value>10.2.143.5:9001</value> </property> <property> <name>mapred.jobtracker.taskScheduler</name> <value>org.apache.hadoop.mapred.CapacityTaskScheduler</value> </property> <property> <name>mapred.queue.names</name> <value>a,b,c,d</value> </property> </configuration>
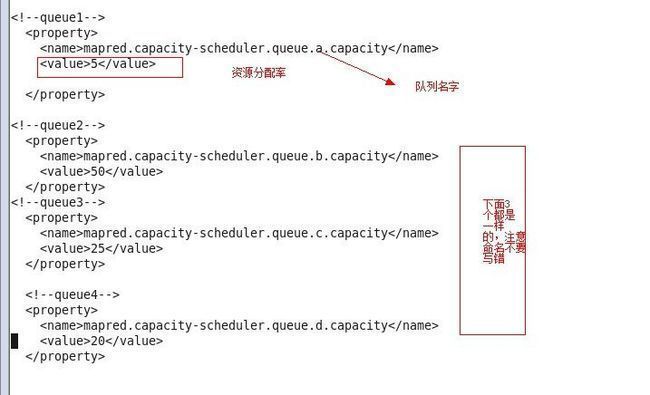
capacity-scheduler.xml里面的核心配置,截图如下
<!--queue1-->
<property>
<name>mapred.capacity-scheduler.queue.a.capacity</name>
<value>5</value>
</property>
<!--queue2-->
<property>
<name>mapred.capacity-scheduler.queue.b.capacity</name>
<value>50</value>
</property>
<!--queue3-->
<property>
<name>mapred.capacity-scheduler.queue.c.capacity</name>
<value>25</value>
</property>
<!--queue4-->
<property>
<name>mapred.capacity-scheduler.queue.d.capacity</name>
<value>20</value>
</property>
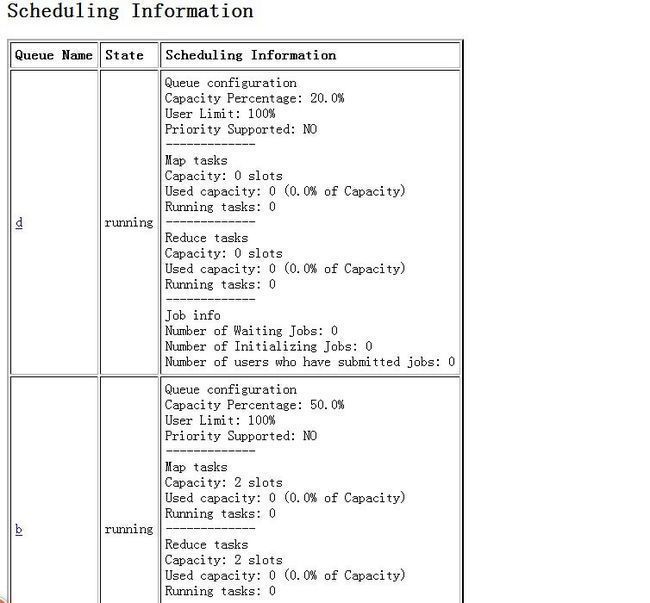
配置完成之后,同步到整个集群,然后开启动态更新命令,就可以启动集群,访问50030端口在web监控页面上看到队列的资源分配情况。
截图如下:
至此,容量调度器已经成功配置,在使用的时候,就可以根据作业的优先级对应提交到不用的队列上来合理的获取系统资源。
最后,散仙在总结一下,配置过程中遇到的一个问题。散仙原来的集群使用的是hadoop默认的tmp的路径,结果在集群启动时,有时会出现datanode无法启动的BUG,查看log日志,报了如下的异常信息:
2013-10-31 04:19:02,035 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/Slave2 2013-10-31 04:19:02,038 INFO org.apache.hadoop.mapred.JobTracker: Adding tracker tracker_Slave2:localhost/127.0.0.1:56885 to host Slave2 2013-10-31 04:19:02,477 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/Slave 2013-10-31 04:19:02,478 INFO org.apache.hadoop.mapred.JobTracker: Adding tracker tracker_Slave:localhost/127.0.0.1:51876 to host Slave 2013-10-31 04:19:02,931 WARN org.apache.hadoop.mapred.JobTracker: Retrying... 2013-10-31 04:19:02,959 WARN org.apache.hadoop.hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /root/hadoop-1.2.0/tmp/mapred/system/jobtracker.info could only be replicated to 0 nodes, instead of 1 at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getAdditionalBlock(FSNamesystem.java:1920) at org.apache.hadoop.hdfs.server.namenode.NameNode.addBlock(NameNode.java:783) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:597) at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:587) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1432) at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1428) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:396) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190) at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1426) at org.apache.hadoop.ipc.Client.call(Client.java:1107) at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:229) at com.sun.proxy.$Proxy7.addBlock(Unknown Source) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:39) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:25) at java.lang.reflect.Method.invoke(Method.java:597) at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:85) at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:62) at com.sun.proxy.$Proxy7.addBlock(Unknown Source) at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.locateFollowingBlock(DFSClient.java:3720) at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.nextBlockOutputStream(DFSClient.java:3580) at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream.access$2600(DFSClient.java:2783) at org.apache.hadoop.hdfs.DFSClient$DFSOutputStream$DataStreamer.run(DFSClient.java:3023) 2013-10-31 04:19:02,960 WARN org.apache.hadoop.hdfs.DFSClient: Error Recovery for null bad datanode[0] nodes == null 2013-10-31 04:19:02,960 WARN org.apache.hadoop.hdfs.DFSClient: Could not get block locations. Source file "/root/hadoop-1.2.0/tmp/mapred/system/jobtracker.info" - Aborting... 2013-10-31 04:19:02,960 WARN org.apache.hadoop.mapred.JobTracker: Writing to file hdfs://10.2.143.5:9090/root/hadoop-1.2.0/tmp/mapred/system/jobtracker.info failed! 2013-10-31 04:19:02,961 WARN org.apache.hadoop.mapred.JobTracker: FileSystem is not ready yet! 2013-10-31 04:19:02,965 WARN org.apache.hadoop.mapred.JobTracker: Failed to initialize recovery manager.
注意如下一段异常
2013-10-31 04:19:02,959 WARN org.apache.hadoop.hdfs.DFSClient: DataStreamer Exception: org.apache.hadoop.ipc.RemoteException: java.io.IOException: File /root/hadoop-1.2.0/tmp/mapred/system/jobtracker.info could only be replicated to 0 nodes, instead of 1
这个异常的产生,很大的关系跟tmp目录有联系,所以散仙建议,还是在hadoop目录下,新建一个tmp专门存放hadoop的格式信息,如果是已经在hadoop目录下有的tmp目录,还出现datanode无法正常启动的情况,需要我们关闭集群服务,进入tmp文件夹下,执行命令,rm -rf * 删除所有的文件,在重新格式化namenode,并重启集群就可以了。