SequoiaDB的优势特性探秘
去年,项目中引入了MongoDB,它给我带来了巨大的便利,之前从没听说过SequoiaDB。直到上个月(2015/01)OSC在长沙搞活动,@OSC永和问我知不知道巨杉数据库,说是国产的NoSQL数据库,可以看成是一个更好的MongoDB,我的第一反应是MongoDB的定制分支?遂被告知,完全是国人团队自己编写的内核,有些佩服,不过也有一个疑问,到底比MongoDB好在哪里?回来之后,在官网上浏览了一周,找到了下面这张图。
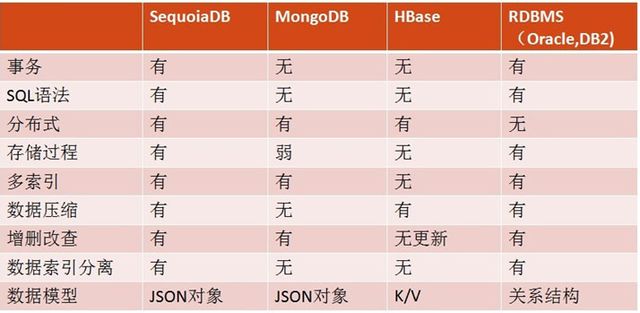
不过文档的详细程度无法和MongoDB相比,看完之后无法像MongoDB那样了解到除使用之外更多的东西。不过对于这个号称比MongoDB领先一到两年的国产数据库,应该会很值得花时间去翻看一下源码,看看这些相比MongoDB的优势特性到底是如何实现的。
代码里面注释很少,所以刚刚开始阅读有点困难,但是代码按照模块,分层的原则进行设计,所以熟悉风格之后还是比较好懂的,需要记住的几个核心概念,包括EDU(Engine Dispatchable Unit),CB(ControlBlock),Msg(Message)。pmdMain.cpp为数据库服务的总入口,pmdController.cpp中有处理启动过程的主要实现逻辑;pmdProcessor.cpp在运行时提供处理各种事件(消息)的代码,主要入口在processMsg方法中,在SequoiaDB中,每一种操作都可看成一种消息发给内核进行处理,都有具体的消息结构进行描述,pmdProcessor中的那些OnXXX的处理代码就是实现各种功能的入口之处,抓住这个点,代码的脉络就清晰起来了。
一, 对事务的支持
定义了四种事务处理相关的消息:MsgOpTransBegin, MsgOpTransCommit, MsgOpTransCommitPre, MsgOpTransRollback
在rtnTransaction.cpp中实现事务处理,类似的代码如下:
INT32 rtnTransBegin( _pmdEDUCB * cb )
{
PD_TRACE_ENTRY ( SDB_RTNTRANSBEGIN ) ;
SDB_ASSERT( cb, "cb can't be null" ) ;
INT32 rc = SDB_OK ;
if ( !sdbGetTransCB()->isTransOn() )
{
rc = SDB_DPS_TRANS_DIABLED ;
goto error;
}
if ( cb->getTransID() == DPS_INVALID_TRANS_ID )
{
cb->setTransID( sdbGetTransCB()->allocTransID() ) ;
cb->setCurTransLsn( DPS_INVALID_LSN_OFFSET ) ;
sdbGetTransCB()->addTransCB( cb->getTransID(), cb ) ;
}
PD_LOG( PDEVENT, "Begin transaction operations(transID=%llu)",
cb->getTransID() ) ;
PD_TRACE_EXIT ( SDB_RTNTRANSBEGIN ) ;
done:
return rc;
error:
goto done ;
}
无论是Begin,Commit,Rollback,最终都由dpsTransCB用来具体处理事务,见dpsTransCB.cpp
// PD_TRACE_DECLARE_FUNCTION ( SDB_DPSTRANSCB_ADDTRANSCB, "dpsTransCB::addTransCB" )
void dpsTransCB::addTransCB( DPS_TRANS_ID transID, _pmdEDUCB *eduCB )
{
{
transID = getTransID( transID );
ossScopedLock _lock( &_CBMapMutex );
_cbMap[ transID ] = eduCB;
}
PD_TRACE_EXIT ( SDB_DPSTRANSCB_ADDTRANSCB );
}
// PD_TRACE_DECLARE_FUNCTION ( SDB_DPSTRANSCB_DELTRANSCB, "dpsTransCB::delTransCB" )
void dpsTransCB::delTransCB( DPS_TRANS_ID transID )
{
{
transID = getTransID( transID );
ossScopedLock _lock( &_CBMapMutex ) ;
_cbMap.erase( transID );
}
PD_TRACE_EXIT ( SDB_DPSTRANSCB_DELTRANSCB );
}
在MongoDB中对单个文档的处理是原子的,不支持对多个文档的事务,如果需要支持,只能利用单文档的这种原子特性,在一个集合中记录下交易的细节信息,自己模拟实现两阶段提交的事务处理。但是在SequoiaDB中,在内部就实现了事务处理,看代码实现的情况,也是两阶段提交的情形,如果回滚的话,就从日志中进行回放进行恢复。有些同学争论说NoSQL数据库无需事务支持,但是对于MongoDB和Sequoia这种文档型的旨在和传统关系数据库直面竞争的NoSQL数据库,支持事务,可以免掉在应用开发中很多的工作,毕竟第一,在应用中不太可能把所有的集合之间的关联关系消除掉,有很多场合需要事务支持;第二,不是每个开发团队都对两阶段提交这样的原理和过程理解明白,这些工作应该放在数据库来做。也许,支持事务,是SequoiaDB宣传“企业级NoSQL数据库”的最大卖点吧。
二, SQL语法支持
SequoiaDB可以和PostgreSQL进行连接;在前面有一篇《SequoiaDB笔记》说SequoiaDB的SQL支持是通过PostgreSQL实现的,这种说法,有一点误导性。而实际的情况是,通过sdb_fdw.so这个模块,可以扩展PostgreSQL,可以让其通过外部表的形式使用SequoiaDB中的数据,可以理解为把Postgres当作前端,而后端的数据存储可以在SequoiaDB中,而这个后端也可以在MySQL,Oracle中,甚至在其他的等各种你能写得出合适的适配器的数据源中,这实际上是PostgreSQL带给我们的便利特性。SequoiaDB提供这个适配器,只是为传统企业迅速使用其特性提供了一种解决方案:即利用PostgreSQL做前端,利用SequoiaDB来扩展大数据的存储和处理能力。而实际的情况是,SequoiaDB对SQL语法的支持,是在查询操作时可以直接接受SQL语句另外,而支持SQL语法也更加方便从传统关系型数据库中迁移过来。例如:db.foo.exec(“select * from bar”)这种。我一度以为是否SequoiaDB使用了Postgres的某些组件实现了对SQL语法的支持,翻看了一下代码,其实不是。
有一个消息名为MsgOpSQL,用来封装查询发过来的SQL语句,有一个SQLCB,专门用于SQL查询的处理。
SQL_PARSE负责对sql进行解析,来自sqlGrammar.hpp,利用boost的spirit库把sql语句解析为ast,然后根据ast构建plan(具体执行计划)。
qgm这个文件夹中包含具体的执行动作实现比如qgmPlInsert.cpp用于插入;qgmPlDelete.cpp用于删除。
对于NoSQL数据库是否需要支持SQL查询,见仁见智了。我觉得应用程序接口中,如果使用类似Python这种直接在语法中就支持字典和列表的语言,查询语句用JSON反而好于SQL,从前台获取的查询条件,无需考虑转换为SQL语句,甚至还可以避免SQL注入攻击。然而用Java语言等,组织个查询条件要初始化一堆嵌套的对象的话,还不如SQL语句来得直接,另外就是直接执行SQL做数据维护的时候,写SQL比写一堆嵌套的大括号,方括号要好太多了。
三, 数据压缩
要看数据压缩部分的实现,主要从dmsCompress.cpp 开始看。SequoiaDB基于snappy来实现数据压缩。Snappy是Google发明的数据压缩算法,它不是追求高压缩率,而是追求快,是Google在内部广泛使用的,也在BigTable和HBase中使用,所以基于这个,数据压缩这块应该是很靠谱的,在不影响性能的情况下,如果能够大幅减少存储空间,当然求之不得。
在dmsStorageData.cpp实现了数据存储服务,如insertRecord实现数据的压缩存储。可以有上下文参数决定是否压缩。
if ( OSS_BIT_TEST ( context->mb()->_attributes,
DMS_MB_ATTR_COMPRESSED ) )
{
rc = dmsCompress( cb, record, ((CHAR*)(&oid)), oidLen,
&compressedData, &compressedDataSize ) ;
PD_RC_CHECK ( rc, PDERROR, "Failed to compress record[%s], rc: %d",
record.toString().c_str(), rc ) ;
dmsRecordSize = compressedDataSize + sizeof(INT32) ;
PD_TRACE2 ( SDB__DMSSTORAGEDATA_INSERTRECORD,
PD_PACK_STRING ( "size after compress" ),
PD_PACK_UINT ( dmsRecordSize ) ) ;
if ( dmsRecordSize > (UINT32)(record.objsize() + oidLen) )
{
dmsRecordSize = record.objsize() ;
}
else
{
addOID = FALSE ;
oidLen = 0 ;
isCompressed = TRUE ;
}
}
四, 数据索引分离
我想SequoiaDB之所以设计数据和索引分离,应该是看到MongoDB在这方面的局限性吧。在MongoDB中,数据和索引是存储在一块的,所以默认情况下,构建索引会阻塞集合上的其他所有操作,所以如果当数据集特别大的时候,建立索引要花很长的时间,这会让数据查询和写入操作陷入停顿。MongoDB在建立索引时,也可以选择后台建立索引的方式,并且在2.4版本以后允许同时建立多个后台索引。SequoiaDB直接把索引单独存放,这样的好处是不但能够破除对数据操作的影响,而且可以通过把索引存储在单独的物理磁盘之上,避免数据,索引和日志对磁盘IO的竞争,从而支持更大规模的数据集。因此,从这一点上,SequoiaDB的后发优势十分明显。
最后,谈一点在探索SequoiaDB的过程中和Mongodb的比较使用感受和期望吧。第一印象,MongoDB比SequoiaDB更容易上手,文档更齐全,社区更活跃。
MongoDB提供了Windows,Linux,Mac平台的可执行文件,并且几乎是开箱即用,根本没有学习难度。国内普通的开发人员用windows的居多,所以提供全平台的执行文件能够大大降低开发人员去尝试的门槛。居然在Mac上也没提供可执行文件,而且编译脚本也不支持Mac,所以我是在Linux服务器上在尝试使用SequoiaDB的。
MongoDB可以无需看文档,下载下来,运行就可以用了。而SequoiaDB我的确是探索了一番。举个例子,谁能想到sdbcmart居然是sdbcm_start的意思,我居然想到什么“艺术”之类的去了;另外sdbcmtop怎么能不让联想到sdbcm_top呢(查状态),而居然是sdbcm_stop!非得去看文档才搞清楚这几个执行文件的意思。
另外,MongoDB还提供了诸如Capped Collection,地理位置查询等一些贴心的小功能,我在自己的项目中用得很爽,因此我觉得这在讨取开发人员欢心方面是很奏效的。
总体而言,觉得在目前阶段MongoDB更Sexy,而SequoiaDB相对来说内秀一点,不过如果瞄准企业级市场,专注于这一块做出特色,而且在国家层面支持的软件国产化战略大局中,后势可期!