R语言学习笔记 五
10)求解线性方程组和逆矩阵
Solve函数求出a %*% x = b中的x向量值,即求解线性方程组,通常使用前2个参数,第一个是a,为系数矩阵 ,第二是b为常数项,当b缺失时,默认为单位矩阵。
ax=b=>ax=I=>a-1ax=a-1I=a-1 =>x=a-1
从上面推导可看出,不提供参数b就能求出a的逆。
求线性方程组的解
> b
[,1]
[1,] 8
[2,] 9
> a
[,1] [,2]
[1,] 1 3
[2,] 2 4
> solve(a,b)
[,1]
[1,] -2.5
[2,] 3.5
求矩阵的逆
> a
[,1] [,2]
[1,] 1 3
[2,] 2 4
> solve(a)
[,1] [,2]
[1,] -2 1.5
[2,] 1 -0.5
11)求矩阵的特征值
λ是A的特征值等价于说线性系统(A– λI) v = 0 (其中I是单位矩阵)有非零解v (一个特征向量),因此等价于说行列式:
![]()
函数:![]() 是一个关于λ的多项式,称为A的特征多项式。矩阵的特征值也就是其特征多项式的零点。求一个矩阵A的特征值可以通过求解方程
是一个关于λ的多项式,称为A的特征多项式。矩阵的特征值也就是其特征多项式的零点。求一个矩阵A的特征值可以通过求解方程![]() 来得到。
来得到。
Eigen函数可以求特征值,其调用格式如下:
eigen(x, symmetric, only.values = FALSE)
x为需要求特征值的矩阵;symmetric是逻辑型表示是否是对称矩阵。
对称矩阵是一个方形矩阵,其转置矩阵和自身相等。
对称矩阵中的右上至左下方向元素以主对角线(左上至右下)为轴进行对称。
only.values 如果为TRUE,则只返回特征值,否则返回特征值和特征向量。
> a<-array(c(1:16),dim=c(4,4))
> eigen(a)
$values
[1] 3.620937e+01 -2.209373e+00 1.599839e-15 7.166935e-16
$vectors
[,1] [,2] [,3] [,4]
[1,] 0.4140028 0.82289268 -0.5477226 0.1125155
[2,] 0.4688206 0.42193991 0.7302967 0.2495210
[3,] 0.5236384 0.02098714 0.1825742 -0.8365883
[4,] 0.5784562 -0.37996563 -0.3651484 0.4745519
> eigen(a,only.values=FALSE)
$values
[1] 5.3722813 -0.3722813
$vectors
[,1] [,2]
[1,] -0.5657675 -0.9093767
[2,] -0.8245648 0.4159736
12)求矩阵的行列式值
> a<-array(c(1:4),dim=c(2,2))
> det(x)
[1] -2
13)奇异分解
M的奇异值分解 :M=UDV',其中U'U=V'V=I。
V的列(columns)组成一套对的正交"输入"或"分析"的基向量,是x的左奇异矩阵。U的列(columns)组成一套对的正交"输出"的基向量,是x的右奇异矩阵。D返回一个向量,向量的元素是对角线上的元素。Svd函数完成奇异分解
> array(c(1:16),dim=c(4,4))->a
> a
[,1] [,2] [,3] [,4]
[1,] 1 5 9 13
[2,] 2 6 10 14
[3,] 3 7 11 15
[4,] 4 8 12 16
> svd(a)
$d
[1] 3.862266e+01 2.071323e+00 1.291897e-15 6.318048e-16
$u
[,1] [,2] [,3] [,4]
[1,] -0.4284124 -0.7186535 0.5462756 -0.0397869
[2,] -0.4743725 -0.2738078 -0.6987120 0.4602190
[3,] -0.5203326 0.1710379 -0.2414027 -0.8010772
[4,] -0.5662928 0.6158835 0.3938391 0.3806452
$v
[,1] [,2] [,3] [,4]
[1,] -0.1347221 0.82574206 -0.4654637 -0.2886928
[2,] -0.3407577 0.42881720 0.4054394 0.7318599
[3,] -0.5467933 0.03189234 0.5855124 -0.5976414
[4,] -0.7528288 -0.36503251 -0.5254881 0.1544743
14)构造矩阵
使用matrix函数构造矩阵,主要参数为:Data表示构造所需数据,nrow为行数,ncol为列数,byrow表示是否按行顺序分配元素(默认为FALSE)。
> matrix(c(1:10),2,5,TRUE)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 2 3 4 5
[2,] 6 7 8 9 10
> matrix(c(1:10),2,5)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
15)最小二乘法拟合
最小二乘法(generalized least squares)是一种数学优化技术,它通过最小化误差的平方和找到一组数据的最佳函数匹配。
设存在(x,y)这2个变量,对于一系列的x变量值,有一系列的y值与其对应,可以找到这2个变量之间的相互关系。我们以一次函数为例,通过将这些(x,y)值标注在直角坐标系统,可以得到一条直线,让这些点在这条直线附近,设直线方程为
y=kx+b
其中:k、b 是任意实数
目标是这些点到这条直线的距离的平方和最小,可运用最小二乘法,最小二乘法拟合的过程就是回归,这条直线就是回归线。
Lsfit()函数完成最小二乘法拟合,其主要参数为:
X:一个矩阵的行对应的情况和其列对应为变量。
Y:结果,可以是一个矩阵,如果你想,以适应多种左手侧。
Wt:可选参数,加权最小二乘法的执行权重向量。
Intercept:是否应使用截距项。
Tolerance:公差将用于在矩阵分解
Yname:用于响应变量的名称。
我们以x=(1,2,3,4),y=(2,4,6,8),可得到回归线方程为Y=2x
> y<-c(2,4,6,8)
> x<-c(1,2,3,4)
> lsfit(x,y)
$coefficients
Intercept X
0 2
上述结果中,Intercept项表示截距,x项表示方程的x的常数项。我们先假设回归线为Y=2x+3,然后,根据回归线构造x和y值。
> y<-c(5,7,9,11)
> x<-c(1,2,3,4)
执行lsfit()函数
> lsfit(x,y)
$coefficients
Intercept X
3 2
要正确得出方程的截距为3,x的常数项为2。现实生活中,很难有如此精确的模型,我们再多构造一些点:
> y<-c(5,7,9,11,16,20)
> x<-c(1,2,3,4,7,9)
> lsfit(x,y)
> x<-c(1,2,3,4,7,9)
> y<-c(5,7,9,11,16,20)
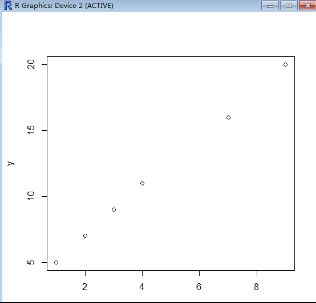
我们通过plot(x,y)来绘制这些点在直角坐标系中的位置,这个图也被称为散点图。
> plot(x,y)
> lsfit(x,y)
$coefficients
Intercept X
3.338028 1.845070
$residuals
[1] -0.18309859 -0.02816901 0.12676056 0.28169014 -0.25352113 0.05633803
Coefficients为系数,包括截距和x的系数,residuals表示残差,残差分别反应了这些点与直线的差异,残差越小越好,我们将回归线也画上
> abline(lsfit(x,y))
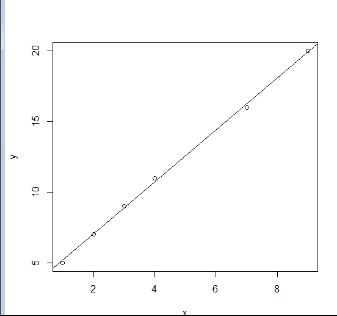
可以看到拟合效果还是不错的,我们也可以使用lm()函数,来建立线性模型进行回归分析:
画x,y的散点图: plot(x,y)
做相关回归分析,结果存放在xy中: lm(y~x)->xy
显示xy的相关回归分析结果:summary(xy)
画回归线:> abline( lm(y~x))
16)矩阵与向量连接
对于向量,Cbind将行转变为列进行连接,而rbind将列转变为行进行连接。
> x2<-c(101:105)
> x1<-c(1:10)
> cbind(x1,x2)
x1 x2
[1,] 1 101
[2,] 2 102
[3,] 3 103
[4,] 4 104
[5,] 5 105
[6,] 6 101
[7,] 7 102
[8,] 8 103
[9,] 9 104
[10,] 10 105
> rbind(x1,x2)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
x1 1 2 3 4 5 6 7 8 9 10
x2 101 102 103 104 105 101 102 103 104 105
对于矩阵,cbind完成横向拼接,rbind完成纵向拼接,下面是关于矩阵的操作
> x3<-matrix(c(1:10),2,5)
> x4<-matrix(c(101:105),2,5)
> x3
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> x4
[,1] [,2] [,3] [,4] [,5]
[1,] 101 103 105 102 104
[2,] 102 104 101 103 105
> cbind(x3,x4)
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
[1,] 1 3 5 7 9 101 103 105 102 104
[2,] 2 4 6 8 10 102 104 101 103 105
> rbind(x3,x4)
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
[3,] 101 103 105 102 104
[4,] 102 104 101 103 105
As.vector将数组转换为向量。
> x<-array(c(1:10),dim=c(2,5))
> x
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> as.vector(x)
[1] 1 2 3 4 5 6 7 8 9 10
交叉因子频率表
> y<-c(11,22,13,14,11,22,31,31,31,14)
> table(y)
y
11 13 14 22 31
2 1 2 2 3
cut把数值型对象分区间转换为因子table
> cut(c(1:10),5)
[1] (0.991,2.79] (0.991,2.79] (2.79,4.6] (2.79,4.6] (4.6,6.4]
[6] (4.6,6.4] (6.4,8.21] (6.4,8.21] (8.21,10] (8.21,10]
Levels: (0.991,2.79] (2.79,4.6] (4.6,6.4] (6.4,8.21] (8.21,10]
我们来看一个综合的例子,求出下面样本的数字在某区间内的分布数量,即求因子频率。下面是美国地震台网公布的全球2013年5月20日22点到24点的所有发生的地震的震级。
| 2013-05-20T23:57:12.000+00:00 |
1.6 |
| 2013-05-20T23:57:12.000+00:00 |
0.9 |
| 2013-05-20T23:52:59.000+00:00 |
2.1 |
| 2013-05-20T23:49:15.100+00:00 |
2.2 |
| 2013-05-20T23:46:36.000+00:00 |
2.3 |
| 2013-05-20T23:44:07.000+00:00 |
1.7 |
| 2013-05-20T23:38:17.000+00:00 |
1.3 |
| 2013-05-20T23:34:12.400+00:00 |
1.6 |
| 2013-05-20T23:33:43.440+00:00 |
4.7 |
| 2013-05-20T23:25:20.500+00:00 |
1.2 |
| 2013-05-20T23:23:35.100+00:00 |
0.9 |
| 2013-05-20T23:07:34.960+00:00 |
4.7 |
| 2013-05-20T23:06:42.800+00:00 |
0.6 |
| 2013-05-20T23:01:25.480+00:00 |
5.3 |
| 2013-05-20T22:59:58.000+00:00 |
1.1 |
| 2013-05-20T22:51:47.120+00:00 |
4.8 |
| 2013-05-20T22:48:40.570+00:00 |
4 |
| 2013-05-20T22:48:18.350+00:00 |
4.2 |
| 2013-05-20T22:36:27.310+00:00 |
4.6 |
| 2013-05-20T22:13:36.000+00:00 |
1.3 |
| 2013-05-20T22:13:09.000+00:00 |
2.1 |
| 2013-05-20T22:10:47.000+00:00 |
1.5 |
| 2013-05-20T22:09:33.600+00:00 |
3 |
我们计算一下地震震级的区间频率分布:首先,将地震震级数据放入一个向量中。
> mag<-c(1.6,0.9,2.1,2.2,2.3,1.7,1.3,1.6,4.7,1.2,0.9,4.7,0.6,5.3,1.1,4.8,4,4.2,4.6,1.3,2.1,1.5,3)
> mag
[1] 1.6 0.9 2.1 2.2 2.3 1.7 1.3 1.6 4.7 1.2 0.9 4.7 0.6 5.3 1.1 4.8 4.0 4.2
[19] 4.6 1.3 2.1 1.5 3.0
然后,使用cut函数将震级分成5个区间,并建立因子
> factor(cut(mag,5))
[1] (1.54,2.48] (0.595,1.54] (1.54,2.48] (1.54,2.48] (1.54,2.48]
[6] (1.54,2.48] (0.595,1.54] (1.54,2.48] (4.36,5.3] (0.595,1.54]
[11] (0.595,1.54] (4.36,5.3] (0.595,1.54] (4.36,5.3] (0.595,1.54]
[16] (4.36,5.3] (3.42,4.36] (3.42,4.36] (4.36,5.3] (0.595,1.54]
[21] (1.54,2.48] (0.595,1.54] (2.48,3.42]
Levels: (0.595,1.54] (1.54,2.48] (2.48,3.42] (3.42,4.36] (4.36,5.3]
最后,统计因子频率
factor(cut(mag,5))->magfactor
> table(magfactor)
magfactor
(0.595,1.54] (1.54,2.48] (2.48,3.42] (3.42,4.36] (4.36,5.3]
8 7 1 2 5
可以看出2013年5月20日22点到24点期间,全球发生的地震在(0.595,1.54]内有8起,在(1.54,2.48]有7起等。
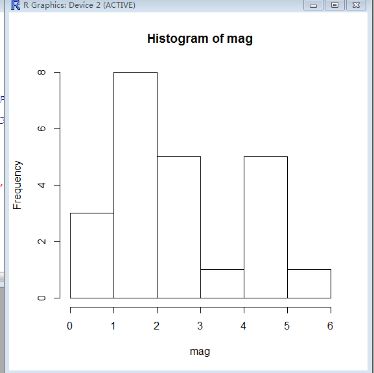
hist函数可用来绘制直方图
> hist(mag,breaks=5)
18)list函数生成一个对象,这个对象可拥有自定义的组件,组件也可拥有自定义的属性
> list(name="students",class="101",stdt.ages=c(22,25,20),stdt.name=c("zhangsang","lisi","wangwu"))->mystudents
> mystudents
$name
[1] "students"
$class
[1] "101"
$stdt.ages
[1] 22 25 20
$stdt.name
[1] "zhangsang" "lisi" "wangwu"
length返回组件的数量
> length(mystudents)
[1] 4
可以直接提取组件的内容完成计算
> c(mystudents$stdt.name,mystudents$stdt.ages)
[1] "zhangsang" "lisi" "wangwu" "22" "25" "20"
19)data.frame
data.frame是一个list类型,内部可以拥有很多组件,我们接着上例构造一个学生集的data.frame
> data.frame(name=mystudents$stdt.name,age=mystudents$stdt.ages)->mysts
> mysts
name age
1 zhangsang 22
2 lisi 25
3 wangwu 20
attach将data.frame内的组件复制一份后将变量放到搜索路径上 ,我们用分离出来的变量将每个人的年龄加2岁
> age+2->mysts$age
> mysts
name age
1 zhangsang 26
2 lisi 29
3 wangwu 24
> age
[1] 24 27 22
> name
[1] zhangsang lisi wangwu
Levels: lisi wangwu zhangsang
使用detach将组件从搜索路径上删除。
> detach(mysts)
> age
错误: 找不到对象'age'
> name
错误: 找不到对象'name'
可使用search函数显示当前搜索路径
> attach(mysts)
> search()
[1] ".GlobalEnv" "mysts" "package:stats"
[4] "package:graphics" "package:grDevices" "package:utils"
[7] "package:datasets" "package:methods" "Autoloads"
[10] "package:base"
使用ls()函数显示搜索路径上的组件
> ls(2)
[1] "age" "name"
> ls(3)
[1] "acf" "acf2AR" "add.scope"
[4] "add1" "addmargins" "aggregate"
[7] "aggregate.data.frame" "aggregate.default" "aggregate.ts"
[10] "AIC" "alias" "anova"
19)read.table和scan读取文件
read.table比scan更强大,在文件有文件头的情况下,指定header=TRUE可以将文件头做为变量名。
> read.table("h:/my_docs/eqweek.csv",header=TRUE,sep=",")->earthquake
> earthquake DateTime.Latitude.Longitude.Depth.Magnitude.MagType.NbStations.Gap.Distance.RMS.Source.EventID.Version
1 2013-05-20T23:57:12.000+00:00,63.45,-148.291,5.5,1.6,Ml,,,,0.8,ak,ak10720946,1.3691E+12
2 2013-05-20T23:52:59.000+00:00,61.337,-152.069,81.4,2.1,Ml,,,,1.15,ak,ak10720941,1.36909E+12
3 2013-05-20T23:49:15.100+00:00,19.99,-155.426,38.2,2.2,Md,,133,0.1,0.11,hv,hv60501711,1.3691E+12
4 2013-05-20T23:46:36.000+00:00,60.498,-142.974,4.2,2.3,Ml,,,,0.43,ak,ak10720934,1.36909E+12
..........................
然后我们提取震级数据,绘制直方图,看一下截止2013.5.20为止的最近一周全球地震震级的分布情况,从图中可以看出,大部分的震级都在1-2级以内,地球还是比较安全的~
> hist(earthquake$Magnitude,5)

Scan按更详细的设置读取文件,更加接近于底层。其调用格式为:
scan(file = "", what = double(), nmax = -1, n = -1, sep = "",
quote = if(identical(sep, "\n")) "" else "'\"", dec = ".",
skip = 0, nlines = 0, na.strings = "NA",
flush = FALSE, fill = FALSE, strip.white = FALSE,
quiet = FALSE, blank.lines.skip = TRUE, multi.line = TRUE,
comment.char = "", allowEscapes = FALSE,
fileEncoding = "", encoding = "unknown", text)
我们读取近一个星期的全球地震数据
> scan(file="h:/my_docs/eqweek.csv",skip=1,sep=",",what=list("",0,0,0,mag=0,"",0,0,0,0,"","",0))->eq
Read 1075 records
分5个区间统计分布频率
> table(factor(cut(eq$mag,5)))
(0.995,2.1] (2.1,3.2] (3.2,4.3] (4.3,5.4] (5.4,6.51]
693 200 46 126 10
可使用edit()函数编辑数据集后存为另一个数据集
t(eq)->eq2
19)分析数据集
继续以全球近一周地震数据为例。我们先将变量放到搜索路径上
> attach(earthquake)
先分析一下地震震深:
> summary(Depth)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.10 5.80 12.15 30.82 38.00 630.70 39
Min表示地震震深最小值,Max表示最大值,Median为中位数,Mean为平均值。
我们试着从下面的散点图中观察一下地震震深与震级的关系:
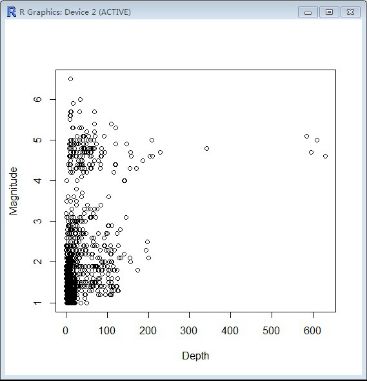
Depth是震深,Magnitude是震级,很有意思的是表面上看过去一周中Depth和Magnitude之间没有关系,仔细观察后这个图,发现一个有趣的结果:当震深超过300后,震级都接近5或在5以上,而在300以内时,震级并不确定。可以做关于震深的直方图
hist(Depth)
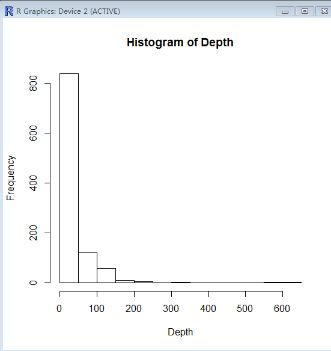
这些只是根据一个星期的数据分析的结果,不一定就代表真正的答案。
lines函数可完成画线
比如说我们绘制一个(10,40)、(20,50)、(30,60)的散点图,并将点连成线
> plot(c(10,20,30),c(40,50,60))
> lines(c(10,20,30),c(40,50,60))
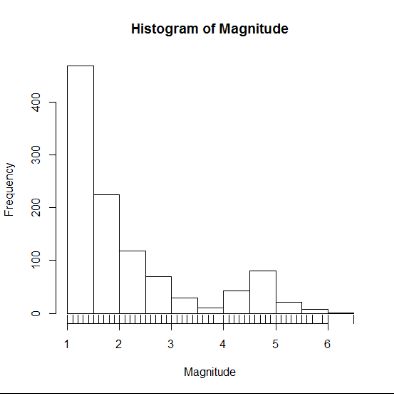
Fivenum函数返回以下数据:minimum, lower-hinge, median, upper-hinge, maximum
> fivenum(Magnitude)
[1] 1.0 1.3 1.7 2.5 6.5
表示震级最小为1.0,最大为6.5,中位数为1.3,通过1.3将一组数据分为上下两组,然后再计算上下两组的中位数1.3与2.5。
rug函数显示实际的数据点
> hist(Magnitude)
> rug(Magnitude)
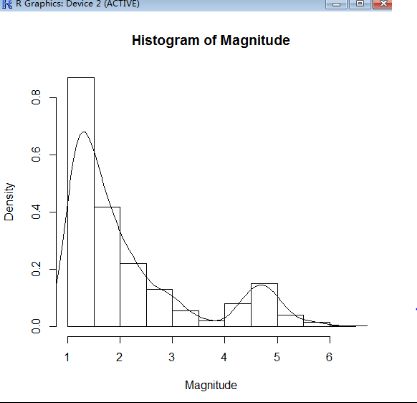
利用直方图估计密度函数存在密度函数是不平滑的,密度函数受子区间宽度影响很大、当数据维数超过2维时有局限性等问题,因此基于核密度估计的方法可解决这些问题。
核密度估计又叫核函数估计(kernel density estimation),是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parzen窗(Parzen window)。Ruppert和Cline基于数据集密度函数聚类算法提出修订的核密度估计方法。
我们使用density函数进行核密度估计:
> hist(Magnitude,prob=TRUE)
> lines(density(Magnitude))
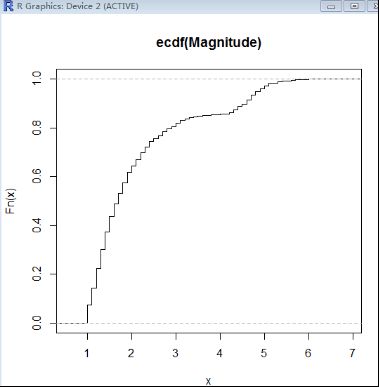
累积分布函数能完整描述一个实数随机变量X的概率分布,是概率密度函数的积分 ,与概率密度函数相对,定义为随机变量小于或者等于某个数值的概率P(X<=x),即:F(x) = P(X<=x)
Ecdf函数完成累积分布函数的计算,我们计算一下震级的累积分布
> plot(ecdf(Magnitude),do.points=FALSE,verticals=TRUE)
19)R条件、循环语句
可以使用for做为循环:
> z<-c()
> x<-(1:10)
> y<-(11:20)
> for (i in 1:length(x)){
+ z[i]=x[i]^2+y[i]^2
+ }
> z
[1] 122 148 178 212 250 292 338 388 442 500
使用while做为循环语句
> x<-c(1:10)
> i=1
> while (x[i]^2<10)
+ {
+ i=i+1
+ x[i]=x[i]^2
+ }
> x
[1] 1 4 3 4 5 6 7 8 9 10
使用if条件语句:
> z<-c()
> x<-(1:10)
> y<-(11:20)
> for (i in 1:length(x)){
+ if ((x[i]^3>y[i]^2))
+ z[i]=x[i]^3
+ else
+ z[i]=y[i]^2
+ }
> z
[1] 121 144 169 196 225 256 343 512 729 1000
19)定义函数与操作符
有限维空间中,已知向量的坐标,就可以知道它的模长。
我们定义一个求3维向量模长的函数:
> vector_length<-function(x1,x2,x3){
+ vlength<-sqrt (x1^2+x2^2+x3^2)
+ vlength
+ }
> vector_length(12,33,19)
[1] 39.92493
我们再定义一个n维的求向量模长的函数
> vectorn_length<-function(x){
+ temp<-0
+ for (i in 1:length(x)){
+ temp<-temp+x[i]^2
+ }
+ vlength<-sqrt(temp)
+ vlength
+ }
> vectorn_length(c(11,22,33,44,55))
[1] 81.57818
> vectorn_length(c(11,22,33,55))
[1] 68.69498
操作符的定义使用%符号%的方式定义,实际使用时%也属于操作符的一部分。我们定义一个操作符求欧氏距离。
欧氏距离(Euclid Distance)是在n维空间中两个点之间的真实距离,n维欧氏空间的每个点可以表示为 (x[1],x[2],…,x[n]) ,两个点 X = (x[1],x[2],…,x[n]) 和 Y= (y[1],y[2],…,y[n]) 之间的距离 d(X,Y) 定义为下面的公式:
d(X,Y) =sqrt (∑( ( x[i] - y[i] )^2 )) 其中 i = 1,2,…,n以%~%为操作符:
> "%~%"<-function(x1,x2){
+ temp<-0
+ for (i in 1:length(x1)){
+ temp<-temp+(x1[i]-x2[i])^2
+ }
+ edis<-sqrt(temp)
+ edis
+ }
> c(1,2,3) %~% c(5,6,7)
[1] 6.928203
指定参数的默认值,在函数调用时可以省略该参数,通过在function随后的参数表中直接指定
> vectorn_length<-function(x=c(1,1,1)){
+ temp<-0
+ for (i in 1:length(x)){
+ temp<-temp+x[i]^2
+ }
+ vlength<-sqrt(temp)
+ vlength
+ }
> vectorn_length()
[1] 1.732051
> vectorn_length(c(11,11,11))
[1] 19.05256
(3)不定数量的函数参数
> mycount<-function(...){
+ temp=0
+ for (i in c(...)){
+ temp=temp+1
+ }
+ temp
+ }
> mycount(11,22,33)
[1] 3
> mycount(11,22,33,66)
[1] 4
> mycount(11,22,66)
[1] 3
(4)内嵌函数
允许在函数内定义函数,使用方法和定义函数一样,只不过整个函数体要定义在另一个函数体内 。
5、统计模型基本应用
(1)分析数据分布情况
我们分析一下某老年常见病数据,下面是数据格式
| 年龄 |
疾病名称 |
急腹症 |
肿瘤 |
| 71 |
肺恶性肿瘤 |
0 |
1 |
| 75 |
直肠恶性肿瘤 |
0 |
1 |
| 75 |
肠梗阻 |
1 |
0 |
| 71 |
急性胆管炎 |
1 |
0 |
| 77 |
胆管恶性肿瘤 |
0 |
1 |
| ............ |
...................................... |
................ |
............. |
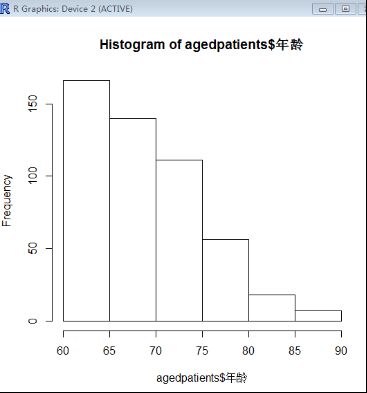
加载数据后,查看老年病的老人年龄分布情况及概率密度分布
> read.table("h:/my_docs/aged_patients.csv",header=TRUE,sep=",")->agedpatients
> hist(agedpatients$年龄)
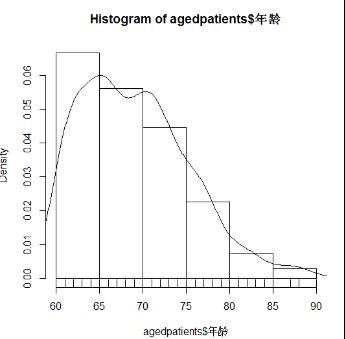
> hist(agedpatients$年龄,prob=TRUE)
> lines(density(agedpatients$年龄))
> rug(agedpatients$年龄)
> min(agedpatients$年龄)
[1] 60
> max(agedpatients$年龄)
[1] 90
> mean(agedpatients$年龄)
[1] 69.09839
> var(agedpatients$年龄)
[1] 38.60801
63~72这个阶段的老人注意坚持运动,保持健康,这个年龄段是这2类老年病的高发时间段, 发生概率较大。从60到90的老人都有可能患上这2类老年病,年纪的平均值是69岁,标准差为38.60801比较大,看来这2个老年病在老人中发生的比较普遍。
我们再按年龄分类汇总肿瘤和急腹症的数量
attach(agedpatients)
> tapply(肿瘤,年龄,sum)
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 87 88 90
19 26 26 28 21 35 37 22 21 23 29 26 31 16 19 12 13 19 8 5 4 3 7 2 1 1 0 3 1
> tapply(急腹症,年龄,sum)
60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 87 88 90
2 0 0 2 0 0 1 0 1 2 4 1 1 0 3 1 2 2 0 2 0 1 0 1 0 1 2 0 0
分年龄统计肿瘤患者的数量
> table(factor(cut(agedpatients$年龄[agedpatients$肿瘤==1],5)))
(60,66] (66,72] (72,78] (78,84] (84,90]
155 158 118 22 5
分年龄统计急腹症患者的数量
> table(factor(cut(agedpatients$年龄[agedpatients$急腹症==1],5)))
(60,65.4] (65.4,70.8] (70.8,76.2] (76.2,81.6] (81.6,87]
4 8 8 5 4