老调重弹:车牌识别
最近一年来忙于研发任务,不得不放下Silverlight 3D的学习。研发中要求逐步解决车牌图像识别、重车桥数(主要用于进行超载检测)图像识别和部分矿种的图像识别。本次将介绍车牌的图像识别。
其实车牌图像识别从技术上已经比较成熟,从理论上来说无外乎就是如下几个步骤:
灰度化:实际就是对原始车牌图片进行预处理,把彩色图片转化为黑白图片,然后对不符合指定阙值范围的灰度值进行过滤。
车牌定位:这是技术难点之一,根据我的经验,定位车牌位置对于车牌的准确识别而言实际上就成功了60%。很多车牌识别的产品都对车牌的定位预留了很多配置参数,例如截取原始图片的位置参数、车牌的长宽比例、大小等等,这些都是为了提高车牌定位的准确率。
字符分割:车牌定位后是字符分割,本人使用的识别过程是:对定位的车牌位置进行降噪处理=>边界模糊=>从右向左找出前6个封闭的图形=>剩余的封闭图形综合为一个图形进行汉字的识别。
字符识别:就是根据字符模板进行模板匹配,因此需预先建立相应的字符模板。基于图像进行字符识别也可配置很多参数来大大提高字符的识别率。例如限定车牌头的字符,车牌各位字符的识别优先级等等。
以下通过大车黄牌号码为例,看看车牌识别的效果。
1、原始图片如下图所示:

2、限定车牌识别区域,本例中将裁剪掉上下左右各10%的区域:
gen_rectangle1 (Rectangle, Height * 0.1 , Width * 0.1 , Height * 0.9 , Width * 0.9 )
reduce_domain (FullImage, Rectangle, Image)
看看裁剪结果:

3、把选中的区域灰度化,方便后续处理:
trans_from_rgb (Red, Green, Blue, Hue, Saturation, Intensity, ' hsv ' )
灰度化后的效果图:

4、灰度阙值过滤,本例中只选中灰度值在100至255之间的区域,可根据实际情况进行相应的设置,然后进行降噪处理:
remove_noise_region (HighSaturation, OutputRegion, ' n_48 ' )
过滤降噪后的效果,和实际的位置很接近了吧!

5、根据预定义的车牌长宽比例等查找符合特定特征的区域:
closing_rectangle1 (ConnectedRegions1, RegionClosing1, 10 , 10 )
select_shape (RegionClosing1, ASelectedRegions, ' area ' , ' and ' , 3000 , 9000 )
select_shape (ASelectedRegions, HSelectedRegions, ' height ' , ' and ' , 30 , 90 )
select_shape (HSelectedRegions, SelectedRegions, ' width ' , ' and ' , 60 , 180 )
效果图如下,分割成了多个区域哈:

6、呈现出车牌区域的灰度化图像:
效果如下,是不是和实际位置一致啊!

7、对上述车牌的精确区域进行阙值过滤,主要是为了去掉车牌周围的黑色边框:
效果图如下:

8、填充有字符而没有在上述算法中被选中的内部区域:
填充后的相关效果图如下:

9、根据选中的上述区域,从原始图片中加载该区域:
效果图如下,车牌又出现了哈

10、确定识别区域字符的偏移角度,根据摄像机位置的不同其倾斜度也会有所不同(根据分割算法的不同,其实此步骤可以省略):
text_line_orientation (ConnectedReducedRegions, TruckTagImage, 30 , - 0.523599 , 0.523599 , OrientationAngle)
11、显示真实的车牌位置图像,主要是方便调试:
效果图如下:

12、进行字符分割,过滤掉非字符区域:
select_characters (RegionForeground, RegionCharacters, ' false ' , ' medium ' , 12 , 30 , ' false ' , ' false ' , ' variable_width ' , ' false ' , ' medium ' , ' false ' , 15 , ' completion ' )
closing_rectangle1 (RegionCharacters, RegionCharactersClosing, 1 , 2 )
效果图如下,是不是离真正的识别又跟进了一步哈!


13、根据各个分割的区域的左上角坐标排序(主要是方便从右向左依次进行字符识别):
sort_region (ConnectedRegionCharactersClosing, SortedRegions, ' first_point ' , ' false ' , ' column ' )
14、显示分割的字符区域的效果图,怎么样?字符分割成功了吧!:
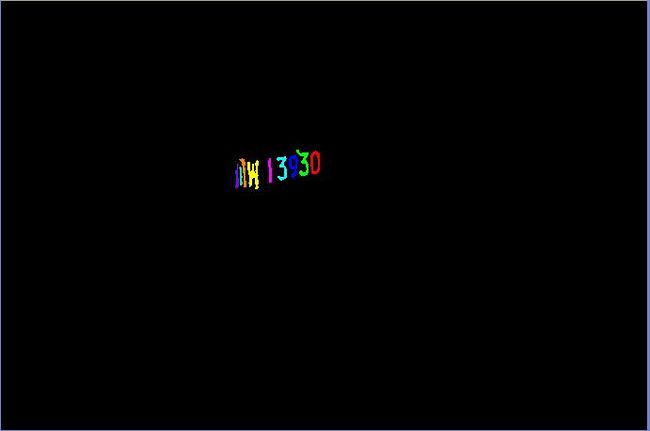
15、加载字符模板,从右向左依次进行字符识别,并把识别结果绘制到对应字符位置的上方: <./p>
for Index : = 1 to 5 by 1
if (Number >= Index)
SelectedSortedRegion : = SortedRegions[Index]
do_ocr_single_class_mlp (SelectedSortedRegion, Image, OCRHandle, 1 , Class, Confidence)
smallest_rectangle1 (SelectedSortedRegion, Row1, Column1, Row2, Column2)
set_tposition (WindowID, Row1 - 30 , (Column2 + Column1) * 0.5 - 5 )
write_string (WindowID, Class[ 0 ])
dev_display (SelectedSortedRegion)
endif
endfor
clear_ocr_class_mlp (OCRHandle)
if (Number > 5 )
read_ocr_class_mlp ( ' D:/MVTec/HALCON/ocr/Industrial_0-9A-Z.omc ' , OCRHandle)
SelectedSortedRegion : = SortedRegions[ 6 ]
do_ocr_single_class_mlp (SelectedSortedRegion, Image, OCRHandle, 1 , Class, Confidence)
smallest_rectangle1 (SelectedSortedRegion, Row1, Column1, Row2, Column2)
set_tposition (WindowID, Row1 - 30 , (Column2 + Column1) * 0.5 - 5 )
write_string (WindowID, Class[ 0 ])
clear_ocr_class_mlp (OCRHandle)
dev_display (SelectedSortedRegion)
endif
相关效果图如下,字符识别的准确度挺高嘛!

