以前用JavaScript主要是处理常规的数字、字符串、数组对象等数据,基本没有试过用JavaScript处理二进制数据块,最近的项目中涉及到这方面的东西,就花一段时间学了下这方面的API,在此总结一下。
为了方便处理二进制数据,nodejs特地封装了一个Buffer模块。文档地址:http://nodejs.cn/doc/node/buffer.html
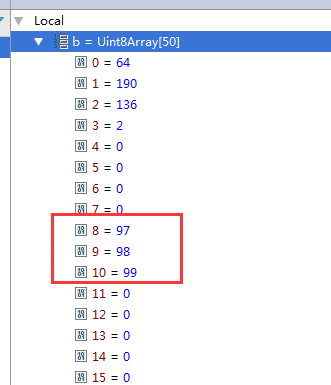
可以通过下面的方式来初始化一个Buffer对象,传入参数50,这样就在内存中申请了一个50byte,400bit的区域来备用,这块区域的大小一旦申请就不能改变,然后通过Buffer对象的fill方法来填充这块内存区域,。
可以看到,Buffer对象在debug工具中显示的是一个长度为50的Uint8Array数组,这个Uint8Array对象是啥后边会解释。
数组的每一位上都存储着一个无符号8位整数,也就是一个字节,0~255。
Buffer对象初始化方法还包括:
Buffer对象还有一些比较、拼接、复制、填充等方法,在上面的文档中都有
nodejs的fs模块
不光手动初始化可以获取一个Buffer对象,通过fs模块来读取文件,也可以获取一个buffer对象。
dnf.exe是一个存放于硬盘中的31733096字节的文件

通过fs模块的readFileSync方法读取此文件,可以得到一个Buffer对象,此Buffer对象
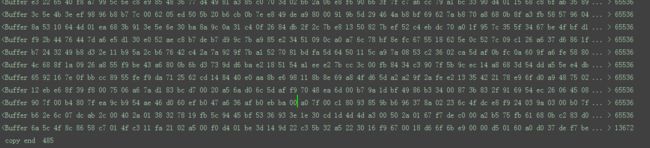
运行之后结果如下:
这样dnf.exe文件就被读取到了内存中,nodejs中有了一个Buffer对象,其占用的内存空间是31733096byte。
Buffer对象可以被写入本地文件系统,或者通过网络写入远程的机器中,或者转换为字符串来做更多的操作,或者不做任何处理。
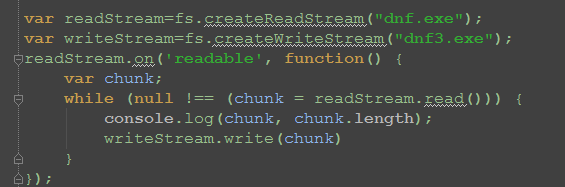
上面例子中的场景,我们可以在当前目录下用次buffer写入一个新的文件
运行完毕后:
这个例子可以行得通,然而事情不会一直这么简单。
我的电脑内存大小是8G,当我想用这段代码copy一个12G的文件时,会发生什么事情呢? 在第一步读取文件的时候,我们需要创建一个占用12G大小内存空间的Buffer对象,这样显然是行不通的,内存会爆掉。那怎么办呢?
Nodejs中的 Stream
什么是Stream,为什么要有Stream
上一小节的例子中,我们遇到了内存不够用的情况,显然我们就需要
把数据分成一小块一小块,一块一块的放到内存中去处理,这样内存就不会爆掉了~
在这里我想比喻一下,方便理解:
CPU相当于一个
工人
工人需要操作工具加热水(CPU需要运行代码执行计算)
硬盘相当于一个
水池
水池里边可以蓄水,容量很大,但是不能在水池里边直接加热水,需要把水放进锅中(硬盘可以存放数据,容量很大,但是不能直接在硬盘中利用数据执行计算,需要把数据读进内存中)
内存相当于一口
锅
锅可以盛水并加热,但是容量不大(内存中可以存放数据用于计算,但是容量不大)
加热-导入水(计算-导入数据)
那么上面小节中我们遇到的问题就是:池子中的水太多,一次倒锅里去就溢出来了,加热不了了。于是我们采取一种措施:
从水池中连接一个管道到锅中,这根
管道(stream.Readable类)可以把水从池子中导入锅中
管子一开始是封闭的,我们可以把开关打开(绑定 Event: 'data',此事件绑定之后即刻触发)
也可以暂停导入(readable.pause())
可以恢复导入(readable.resume())
还可以手动导入(readable.read())
加热完毕—导出水(计算完毕-导出数据)
当导入的一锅水烧好以后,需要把这一锅水倒出去才能处理下一锅,于是
从锅中连接一根
管道(stream.Writable类)到另外的容器中(可能是硬盘中的另外一块区域,也可能是远程的另外一台机器)
和上面的readStream一样,
管子可以向另外一个地方导出水(writable.write)
不计算只中转
当锅只是起一个中转的作用时,可以把导入管接到导出管上去(readable.pipe(destination[, options]))
过程中也可以把他们分开(readable.unpipe([destination]))
既可以导出也可以导入的Stream
有的管道既可以导入,也可以导出(stream.Transform)
Stream模块基本用法
基础API当然还是官方文档: http://nodejs.cn/doc/node/stream.html
把前边的例子改写:
、
或者更简单的
或者
readstream中的内容默认是Buffer对象,在读取之前设置字符编码,读取的时候即可获取字符串。
Stream的应用场景
用到Stream的地方有
刚才说的file system
http模块的request对象和response对象
net模块的数据传输
当我们需要持续的向一个地址写入二进制数据or从一个地址读出二进制数据时,我们也可以根据nodejs官方提供的API实现我们自己的读写stream
当我们用nodejs做http代理的时候,对于客户端,nodejs是服务器,response对象是一个writeStream;对于目标服务器,nodejs是客户端,res对象是一个readStream,
因此直接res.pipe(response)就把目标服务器的数据转发给客户端了。
http服务端向客户端写入文件的时候,也可以直接把文件的readStream对接到response上
浏览器中的 ArrayBuffer
上面nodejs中的Buffer对象在ws控制台中显示出来的是Uint8Array,对于这一点我查了下,发现es5其实是有二进制处理的API的,只是在浏览器端用的实在不多,所以之前并没有关注到。
下面是msdn文档里边对ArrayBuffer的解释:
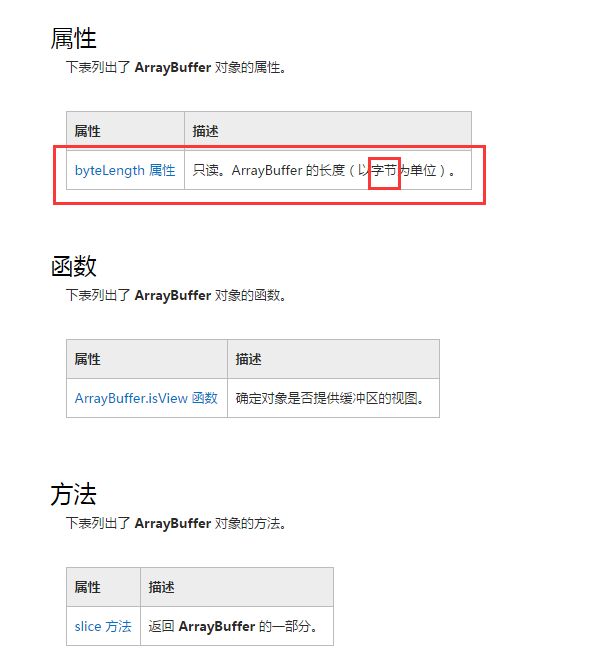
ArrayBuffer 对象表示用于存储不同类型化数组的数据的原始数据缓冲区。无法直接读取或写入 ArrayBuffer,但可以将它传递给类型化数组或 DataView 对象 来解释原始缓冲区。可以使用 ArrayBuffer 来存储任何类型的数据(或混合类型的数据)。
、
存储二进制数据,定义时length以byte来计数,看起来是不是和nodejs环境下的Buffer很像?
但是看API这东西并不能直接写入和读取数据,所以,接着往下看吧!
ArrayBuffer的查看和编辑视图——类型化数组和DataView
什么是类型化数组
刚刚说到的ArrayBuffer,看起来有点像nodejs中的Buffer对象,但是又没有Buffer对象的读写API,这个不太科学嘛,所以肯定需要一种办法来操作它。
实际上,ArrayBuffer对象就是一块静止的二进制数据存储区:
00000001 00000010 000000011 00000100
当需要写入或者操作这段内存区时,如果直接开几个API让你写入01010101这种数据,我想你的内心一定是崩溃的。
所以es5提供了一些视图来表示和操作这些二进制数据,比如,每8位二进制数转换成一个10进制的8位无符号整数,存入一个特殊数组中,就是
Uint8Array [1,2,3,4]
这种数组的原型并没有指向Array.prototype,它不具有JavaScript普通数组的那些操作方法,同时这种数组里边所有的元素一定是一个0~255的整数。
当我们操作 arr[3]=1之后,Uint8Array就变成了
[1,2,3,1]
而ArrayBuffer的内容就变成了
00000001 00000010 000000011 00000001
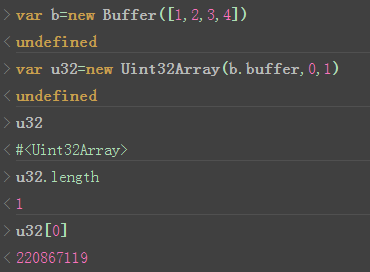
要注意的是,ArrayBuffer是原始数据,根据原始数据可以创建多份不同类型的数据视图,当任何一个视图改变了原始数据后,其他视图所看到的数据都会发生变化,下面会给出例子。
这个Uint8Array 是不是很眼熟呢? 看起来nodejs中的Buffer和浏览器环境下的Uint8Array有某种联系啊!
类型化数组类型
这种视图的类型有很多:
每种数组中的数据类型不同,看名字可以明白他们存放的数据类型,例如Float32Array,就是把每32个二进制数转换成一个无符号浮点数,存入这种类型化数组中。
类型化数组操作API
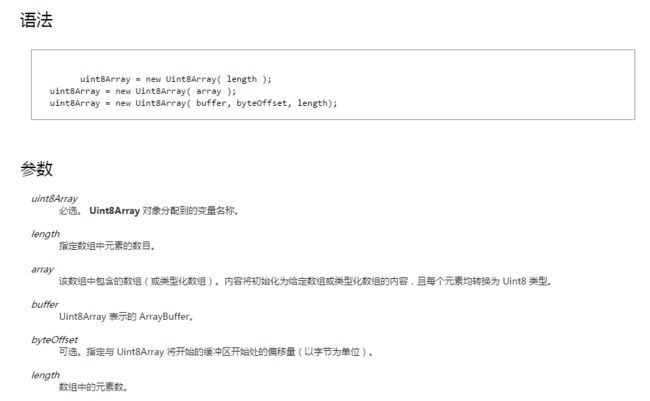
初始化方法:
属性解释:
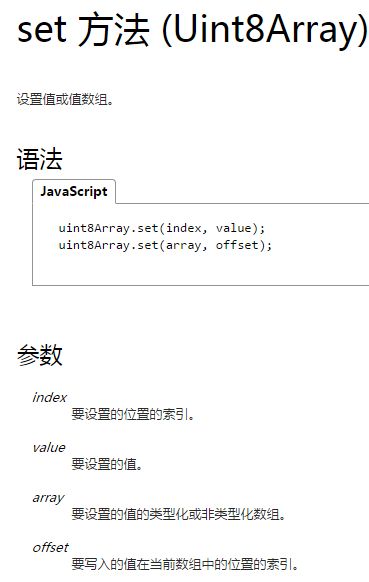
操作方法:
DataView
DataView是一个可以获取ArrayBuffer数据和编辑ArrayBuffer数据的对象,它取ArrayBuffer中的一个片段,提供一些方法来获取或编辑这些片段中的数据,不像类型化数组一样把数据放入一个数组结构中。
方法
下表列出了 DataView 对象的方法。
| 方法 |
描述 |
| getInt8 方法 |
在相对于视图开始处的指定字节偏移量位置处获取 Int8 值。 |
| getUint8 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Uint8 值。 |
| getInt16 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Int16 值。 |
| getUint16 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Uint16 值。 |
| getInt32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Int32 值。 |
| getUint32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Uint32 值。 |
| getFloat32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Float32 值。 |
| getFloat64 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处获取 Float64 值。 |
| setInt8 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Int8 值。 |
| setUint8 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Uint8 值。 |
| setInt16 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Int16 值。 |
| setUint16 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Uint16 值。 |
| setInt32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Int32 值。 |
| setUint32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Uint32 值。 |
| setFloat32 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Float32 值。 |
| setFloat64 方法 (DataView) |
在相对于视图开始处的指定字节偏移量位置处存储 Float64 值。 |
一种特殊的类型化数组
Uint8ClampedArray和Uint8Array类似,唯一不同的是,当插入数组的值不在0~255之间的时候,取值策略不同,Uint8Array是将输入的数字取模,而Uint8ClampedArray是大于255取255,小于0取0
Uint8ClampedArray在canvas的getImageData时用到,因为颜色值#ffffff,刚好用3个字节来表示,比较合适~
类型化数组理解时要注意的特点
初始化时字节取值范围
ArrayBuffer初始化时的length是以字节(byte)为单位的而不是位(bit),
通过缓冲区初始化类型化数组的时候,offerset代表的缓冲区中的偏移量,也
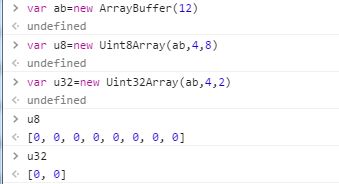
而类型化数组初始化时的length是类型化数组中的length代表的并不是此次初始化要使用的缓冲区中的字节长度,而是类型化数组中的元素个数。
Uint32Array = new Uint32Array ( buffer, byteOffset, length);
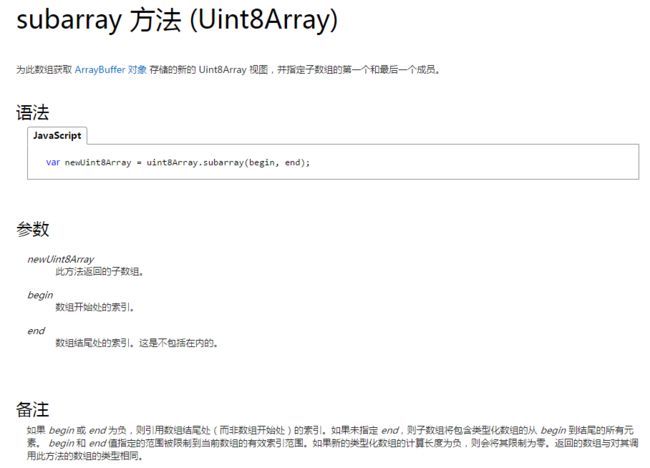
所以例如Uint32Array实际被使用的缓冲区中的字节应该是从第byteOffset个到第byteOffset+4*length个字节,而不是从第byteOffset个字节到byteOffset+length个字节
类型化数组只是视图,原始数据存在ArrayBuffer中,原始数据发生变化,所有视图都变化
浏览器中的使用实例
1.ajax接收ArrayBuffer数据
var req = new XMLHttpRequest();
req.open('GET', "http://www.example.com");
req.responseType = "arraybuffer";
req.send();
req.onreadystatechange = function () {
if (req.readyState === 4) {
var buffer = req.response;
var dataview = new DataView(buffer);
var ints = new Uint8Array(buffer.byteLength);
for (var i = 0; i < ints.length; i++) {
ints[i] = dataview.getUint8(i);
}
alert(ints[10]);
}
}
2.websocket也支持ArrayBuffer类型的数据接收
var websocket = new WebSocket(sUri);
websocket.binaryType = "arraybuffer" ;
3.用于在前端创建blob对象,file对象下载or上传
4.浏览器虽然无权限读取本地文件,但是有权限向本地写入文件,写入文件到本地时可能会用到
5.视频音频播放(写文件和播放视音频我没有验证)
后面我会学习这些使用形式,到时候再做总结~
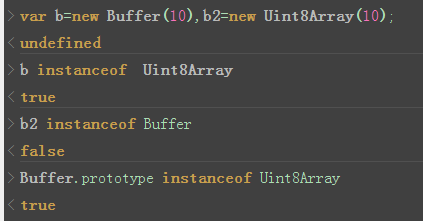
nodejs中的buffer和浏览器中的Uint8Array的关系
可见,nodejs中实现的Buffer实际上是Uint8Arr数组的一个子类,是nodejs为了进一步提升JavaScript的二进制数据处理能力而封装的一个类。