机器学习(一)
序言
最近在Coursera 上学习斯坦福大学的机器学习。根据费曼学习法的理论,教是最好最快最有效果的学习方法。因此,我将会开一系列机器学习相关的文章,同步我的学习进度,并用我自己的理解和语言将我学到的内容写出来。
为了防止拖延症的发作,我将会严格制定时间表,尽最大可能保证每周一篇文章。
希望这一系列文章能让我更好的理解机器学习,也希望同时能为大家提供学习机器学习的入门参考。
第一周
机器学习定义
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E. ——Mitchell provides
定义说的那么复杂,简单的说,机器学习就是:一个程序,这个程序可以通过一些已知的现象和结果来推测一些未知的现象应该有的结果。
监督学习和非监督学习
监督学习: 有答案的学习过程。
非监督学习: 没有答案的学习过程。
我们回想一下自己小学时候,做作业,老师站在旁边,我做完一道题,老师看了以后说,答案是正确的。这就是监督学习的过程。
我们再想想现在,大家在大学或者工作以后,接触到的东西,有时候是没有标准答案的,我们只能凭自己认为是正确的方向去做。做完以后也没有办法知道这样的做法是正确的还是错误的。这就是非监督学习的过程。
当然,上面两个例子里面,我举例用的“学习”,仅仅是监督学习的“学习”的一小部分。监督学习的“学习”还包含很多内容,包括发现,探索等等。
回归和分类
回归和分类属于监督学习。
回归:回归就是根据输入的数据得到连续输出的过程。
分类:分类就是根据输入的数据得到离散输出的过程。
所以回归和分类,本质上是一个过程,或者说算法。也就是我们常说的分类算法或者回归算法。
这里用来区分回归和分类,主要的指标就是看输出是否连续。对于输入是没有特别的要求的。输入可以是连续的,也可以是离散的,决定这个算法是分类还是回归,由输出来决定。
我们用房价来举例子,你有一套房子,占地100平米,可以卖多少钱?我告诉你可以卖1000万。你朋友问我他的房子120平米,可以卖多少钱,我告诉他,可以卖1200万。这样你告诉我一个大小,我告诉你可以卖多少钱,这就叫做回归。你给我不同的大小,我就给你不同的价格。
同一个例子,什么是分类呢?你有一套房子,占地100平米,准备1000万出售,能不能卖出去,我告诉你,不能。你朋友的房子120平米,1200万出售,能不能卖出去,我说可以。这里的结果只有两个,“能卖出去”和不能卖出去,所以这个结果是离散的。
集群和关联
集群和关联属于非监督学习。
集群:根据一些特征来对一大群数据分组。
关联:已知一些已有的现象和结论,又来了一个类似的现象,把它和某个已知的结论联系起来。
集群很类似于分类,不同在于是否知道正确的答案。分类是知道答案的,集群是不知道答案的。
关联和有标准答案的基于规则的联系不同。关联里面,那些已知的现象和结论,都是评估出来的,并不一定正确。比如,看到流鼻涕和感冒,这就属于一种关联,但是流鼻涕并不一定都是感冒。
一元线性规划
一元线性规划属于监督学习。
对于有些事件,导致结果的因素只有一个,于是就可以用一元线性规划来估算出一个一次函数,通过这个函数来确定对于新的输入,应该有什么输出。
对于学习过初中物理的同学来说,应该记得在处理实验数据的时候,老师说过这样一句话:
作一条线尽量多的穿过数据点,并让不在线上的点均匀分布在线的两侧。——物理老师。
如图:

所谓的一元线性规划,就是做这一条线,或者准确的说,是确定这个一次函数的过程。
举个例子,按时间计费的宽带上网,上网的费用仅仅由上网的时间决定,上的多就多缴费,上得少就少缴费。知道了上网的时间,就知道了上网的费用。这就是一个一元线性规划的问题。并且可以准确的确定一个一次函数,输入时间,输出的费用就一定是上网的实际花费。
当然,有一些情况下,这个一次函数只是近似情况,只能保证大多数情况在误差范围内符合。
写成数学公式,我们用
![]()
来表示,其中θ0和θ1都是参数,输入是x, 输出是y或者hθ(x).
代价函数
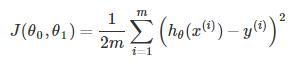
看起来很复杂的样子,但是大家注意,其实这就是一个方差。只不过多除以了一个2.代价函数就是实际测量值和预测值的误差的方差除以2。
代价函数是由θ0和θ1为变量的函数,通过计算代价函数求θ0和θ1,并且需要保证求出来的θ0和θ1使得由他们确定的一次函数,在误差范围内,尽可能好的符合已知情况。
而一元线性规划的过程,就是求代价函数的极小值。这里我说的是极小值而不是最小值,因为极值和最值是不一样的。
但是值得庆幸的是,对于一元线性规划的代价函数来说,极小值就是最小值,这在数学上是可以证明的。
梯度下降
梯度下降是一种计算θ0和θ1的算法。
大家设想,现在用直升机把你放在了半山腰,然后蒙着你的眼睛,让你下到山谷去,虽然这个任务很困难,但是还是可以做到的。利用脚去感知,发现往左是坡度向上,往右坡度向下,于是你就往右慢慢挪动一小步,然后再重复刚才的动作,发现现在右前方坡度是向下的,于是你又慢慢往右挪动一小步,这样一步一步的移动,最终你会移动到某个山谷里面去。
梯度下降也是同样的原理,这里的梯度就可以理解成你走的一小步,每一小步就像是下要给台阶。
但是这一小步你要走多长呢?这个就是一个系数,叫做学习率。如果这个系数设定小了,那走的很慢,但是如果设定大了,比如一步垮了一光年那么远,就会导致丢失目标,甚至是结果发散。
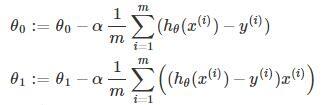
这就是梯度下降的算法描述了,大家可以根据代价函数的公式,自己确定一下梯度下降的具体算法。
总结
这一周讲了机器学习的基本概念以及一元线性规划,同时讲了求解一元线性规划代价函数的梯度下降算法。