HBase的工作原理和相关操作
学习一个开源软件的基本思路都是(1)安装和配置(2)理解工作原理(3)命令操作(4)代码操作(5)研究源码(6)根据论文或需求进行二次开发。同样,学习HBase也不例外,但我省去了HBase集群(4台)的安装和配置,主要总结HBase的工作原理,Shell命令操作,Java代码操作相关内容。
一. HBase存储结构

1. Client
解析:
对于管理类的操作,Client与HMaster进行RPC,对于数据读写类的操作,Client与HRegionServer进行RPC。
2. ZooKeeper
解析:
ZooKeeper作为协同服务,可以看成是Google的Chubby的开源实现,主要的目的是为了避免HMaster的单点问题。
3. HMaster
解析:
HMaster主要负责Table和Region的管理工作。具体功能如下所示:
- 管理用户对Table的增、删、改、查操作;
- 管理HRegionServer的负载均衡,调整Region分布;
- 在Region Split后,负责新Region的分配;
- 在HRegionServer停机后,负责失效HRegionServer上的Region迁移。
4. HRegionServer
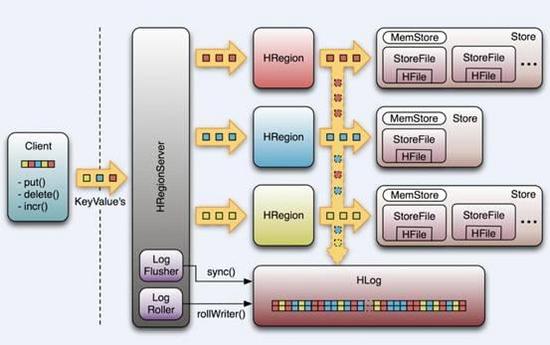
HRegionServer主要负责响应用户I/O请求,向HDFS中读写数据,是HBase中最核心的模块。总体的关系是HRegionServer包含多个HRegion,HRegion包含多个HStore,每个HStore对应Table中的一个Column Family的存储。HStore包含MemStore和StoreFile两个部分。MemStore是Sorted Memory Buffer,用户写入的数据首先放入MemStore,当MemStore满了以后会执行Flush操作变成一个StoreFile(底层实现是HFile),当StoreFile文件数量增长到一定阈值时,会触发Compact合并操作,将多个StoreFile合并到一个StoreFile,合并过程中会进行版本合并和数据删除。每个HRegionServer中都有一个HLog对象,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新的,并删除旧的文件(已持久化到StoreFile中的数据),主要用来做灾难恢复。
说明:
一个Table会被Split成为多个HRegion,不同的HRegion会被HMaster分配给相应的HRegionServer进行管理。
二. HBase框架结构及流程
三. HBase的Shell操作
学习HBase最好的资料就是help和官方手册,几乎所有的问题都可以从上面找到答案,如下所示:
hbase(main):001:0> help HBase Shell, version 1.1.2, rcc2b70cf03e3378800661ec5cab11eb43fafe0fc, Wed Aug 26 20:11:27 PDT 2015 Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command. Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group. COMMAND GROUPS: Group name: general Commands: status, table_help, version, whoami Group name: ddl Commands: alter, alter_async, alter_status, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, show_filters Group name: namespace Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables Group name: dml Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve Group name: tools Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, close_region, compact, compact_rs, flush, major_compact, merge_region, move, split, trace, unassign, wal_roll, zk_dump Group name: replication Commands: add_peer, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, list_peers, list_replicated_tables, remove_peer, remove_peer_tableCFs, set_peer_tableCFs, show_peer_tableCFs Group name: snapshots Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, list_snapshots, restore_snapshot, snapshot Group name: configuration Commands: update_all_config, update_config Group name: quotas Commands: list_quotas, set_quota Group name: security Commands: grant, revoke, user_permission Group name: visibility labels Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility SHELL USAGE: Quote all names in HBase Shell such as table and column names. Commas delimit command parameters. Type <RETURN> after entering a command to run it. Dictionaries of configuration used in the creation and alteration of tables are Ruby Hashes. They look like this: {'key1' => 'value1', 'key2' => 'value2', ...} and are opened and closed with curley-braces. Key/values are delimited by the '=>' character combination. Usually keys are predefined constants such as NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type 'Object.constants' to see a (messy) list of all constants in the environment. If you are using binary keys or values and need to enter them in the shell, use double-quote'd hexadecimal representation. For example: hbase> get 't1', "key\x03\x3f\xcd" hbase> get 't1', "key\003\023\011" hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40" The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added. For more on the HBase Shell, see http://hbase.apache.org/book.html
1. DDL操作
1)创建一个member
hbase(main):011:0> create 'member','member_id','address','info' 0 row(s) in 1.2340 seconds => Hbase::Table - member
说明:这里的member_id就是Row Key,然后address和info就是定义的2个Column Family。查看所有的表可以使用list命令。
2)查看表结构
hbase(main):012:0> describe 'member' Table member is ENABLED member COLUMN FAMILIES DESCRIPTION {NAME => 'address', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALS E', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} {NAME => 'info', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FALSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} {NAME => 'member_id', DATA_BLOCK_ENCODING => 'NONE', BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0', VERSIONS => '1', COMPRESSION => 'NONE', MIN_VERSIONS => '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'FA LSE', BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'} 3 row(s) in 0.0240 seconds
说明:可以看到对于表中的每个字段(member_id,info和address)都通过=>进行了详细的描述。
3)删除一个列簇
删除列簇分为2步,首先disable表,最后enable表。比如我们删除member_id列,如下所示:
hbase(main):013:0> disable 'member' 0 row(s) in 2.2540 seconds hbase(main):018:0> alter 'member',{NAME=>'member_id',METHOD=>'delete'} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 2.2110 seconds hbase(main):019:0> enable 'member' 0 row(s) in 1.2610 seconds
说明:
如果要删除一个表,那么先disable再drop,否则报错。
4)查询表是否存在
hbase(main):024:0> exists 'member' Table member does exist 0 row(s) in 0.0130 seconds
说明:奇怪的是,member明明是存在的,不知道为什么exists的返回值说其不存在。
5)判断表是否enable
hbase(main):025:0> is_enabled 'member' true 0 row(s) in 0.0100 seconds
说明:同样的方式,我们也可以判断表是否disable。
2. DML操作
1)向表member中插入几条记录
hbase(main):026:0> put 'member','ssw','info:age','27' hbase(main):027:0> put 'member','ssw','info:birthday','1986-08-23' hbase(main):028:0> put 'member','ssw','info:company','autonavi' hbase(main):029:0> put 'member','ssw','address:contry','china' hbase(main):030:0> put 'member','ssw','address:province','beijing' hbase(main):031:0> put 'member','ssw','address:city','beijing'
2)获取一条数据
获取一个Row Key的所有数据,如下所示:
COLUMN CELL address:city timestamp=1450871344151, value=beijing address:contry timestamp=1450871285668, value=china address:province timestamp=1450871317111, value=beijing info:age timestamp=1450871154450, value=27 info:birthday timestamp=1450871213694, value=1986-08-23 info:company timestamp=1450871250287, value=autonavi 6 row(s) in 0.0200 seconds
说明:同样的方式,我们可以使用get 'member','ssw','info'获取一个Row Key,一个Column Family中的所有数据。我们可以使用get 'member','ssw','info:age'获取一个Row Key,一个Column Family中一个列的所有数据。
3)更新一条记录
将ssw的年龄改成120,如下所示:
hbase(main):034:0> put 'member','ssw','info:age','120' 0 row(s) in 0.0120 seconds hbase(main):035:0> get 'member','ssw','info:age' COLUMN CELL info:age timestamp=1450872186950, value=120 1 row(s) in 0.0140 seconds
4)通过timestamp获取2个版本的数据
hbase(main):038:0> get 'member','ssw',{COLUMN=>'info:age',TIMESTAMP=>1450871154450} COLUMN CELL info:age timestamp=1450871154450, value=27 1 row(s) in 0.0090 seconds hbase(main):044:0>get 'member','ssw',{COLUMN=>'info:age',TIMESTAMP=>1450872186950} COLUMN CELL info:age timestamp=1450872186950, value=120 1 row(s) in 0.0150 seconds
5)全表扫描
hbase(main):046:0> scan 'member' ROW COLUMN+CELL ssw column=address:city, timestamp=1450871344151, value=beijin g ssw column=address:contry, timestamp=1450871285668, value=chin a ssw column=address:province, timestamp=1450871317111, value=be ijing ssw column=info:age, timestamp=1450872186950, value=120 ssw column=info:birthday, timestamp=1450871213694, value=1986- 08-23 ssw column=info:company, timestamp=1450871250287, value=autona vi 1 row(s) in 0.0180 seconds
6)删除Row Key为"ssw"的值的"info:age"字段
hbase(main):047:0> delete 'member','ssw','info:age' 0 row(s) in 0.0240 seconds hbase(main):048:0> get 'member','ssw' COLUMN CELL address:city timestamp=1450871344151, value=beijing address:contry timestamp=1450871285668, value=china address:province timestamp=1450871317111, value=beijing info:birthday timestamp=1450871213694, value=1986-08-23 info:company timestamp=1450871250287, value=autonavi 5 row(s) in 0.0090 seconds
7)查询表中有多少行
hbase(main):049:0> count 'member' 1 row(s) in 0.0730 seconds => 1
8)给'ssw'这个ID增加'info:age'字段,并使用counter实现递增
hbase(main):083:0> incr 'member','ssw','info:age' COUNTER VALUE = 1 0 row(s) in 0.0100 seconds hbase(main):084:0> get 'member','ssw','info:age' COLUMN CELL info:age timestamp=1450874837307, value=\x00\x00\x00\x00\x00\x00\x00\x01 1 row(s) in 0.0040 seconds hbase(main):085:0> incr 'member','ssw','info:age' COUNTER VALUE = 2 0 row(s) in 0.0090 seconds hbase(main):086:0> get 'member','ssw','info:age' COLUMN CELL info:age timestamp=1450874885152, value=\x00\x00\x00\x00\x00\x00\x00\x02 1 row(s) in 0.0120 seconds
获取当前counter的值,如下所示:
hbase(main):087:0> get_counter 'member','ssw','info:age' COUNTER VALUE = 2
9)将整张表清空
hbase(main):089:0> truncate 'member' Truncating 'member' table (it may take a while): - Disabling table... - Truncating table... 0 row(s) in 3.7810 seconds
说明:单个操作比较麻烦,我们可以把所有的HBase Shell命令写入一个文件内,比如test.sh文件,执行命令hbase shell即可。
四. HBase的Java客户端代码操作
Java客户端也可以实现像Shell对HBase的操作一样,比如设置HBase配置文件,创建表,删除表,查询数据,插入数据,删除数据,切分表等。除了Java客户端外,HBase也提供了Avro(hbase-daemon start/stop avro)、REST(hbase-daemon start/stop rest)和Thrift(hbase-daemon start/stop thrift)接口,主要是为了在使用非Java编程语言和HBase交互时使用这些接口。自己使用过Thrift,主要目的是通过rhbase让R访问HBase数据库。
1. 通过MapReduce向HBase中写入数据
由于代码较长,所以放在了GitHub上面,地址链接:https://github.com/1000sprites/HBase_Program/tree/master/ReadHBase
(1)输入文件test.txt的内容
root@Master:~/Java_Program/out/artifacts/hbase_mapreduce_jar# hdfs dfs -cat /input/test.txt hello hadoop hadoop is easy
(2)执行程序的命令
root@Master:~/Java_Program/out/artifacts/hbase_mapreduce_jar# hadoop jar Java_Program.jar hdfs://Master:8020/input/test.txt
(3)查看HBase中数据库wordcount的内容
hbase(main):092:0> scan "wordcount" ROW COLUMN+CELL easy column=content:count, timestamp=1450953807034, value=1 hadoop column=content:count, timestamp=1450953807034, value=2 hellop column=content:count, timestamp=1450953807034, value=1 isllop column=content:count, timestamp=1450953807034, value=1 4 row(s) in 0.5030 seconds
2. 读取HBase中的数据
由于代码较长,所以放在了GitHub上面,地址链接:https://github.com/1000sprites/HBase_Program/tree/master/WriteHBase
(1)执行程序的命令
root@Master:~/Java_Program/out/artifacts/hbase_mapreduce_jar# hadoop jar Java_Program.jar hdfs://Master:8020/hbase/output
(2)查看hdfs://Master:8020/hbase/output目录下的内容
root@Master:~/Java_Program/out/artifacts/hbase_mapreduce_jar# hdfs dfs -cat /hbase/output/part-r-00000 easy count:1 hadoop count:2 hellop count:1 isllop count:1
说明:上述代码可能还有问题,因为输入的内容与输出的内容不太一致。另外,比较疑惑的一个问题是HBase的表wordcount的存储路径问题。