Scala for the Impatient要点记录 - Part 1
Caution
在事实上解读Scala规范(Scala Language Reference 2.11.x)之前,这里不保证内容的正确性。
Content
- 1 基础
- 2 控制结构和函数
- 3 数组相关操作
- 4 映射和元组
- 5 类
- 6 对象
- 7 包和引入
- 8 继承
- 9 文件和正则表达式
- 10 特质
1 基础
要点
- 使用Scala解释器
- 用var和val定义变量
- 数字类型
- 使用操作符和函数
- 浏览Scaladoc
1.1 Scala解释器
用Scala IDE吧。
1.2 声明值和变量
以val定义的值实际上是一个常量。
以var定义的变量,其值可变。
普通的变量声明时必须做初始化,可以借助类型推断而不指定其类型。
声明变量时可以指定其类型:
val greeting: String = "hello"多个变量一起赋值:
val x, y = 100 // x == 100 and y == 1001.3 常见类型
Scala常见的类型:
// classes
Byte Char Short Int Long Float Double BooleanScala不刻意区分基本类型和引用类型,不需要类Java中的包装类型。
在Scala中使用方法,而不是类型转换来做数值类型之间的转换。
1.4 算术和操作符重载
Scala中一些操作符实际上是方法。
Scala没有提供++和--操作符。
1.5 调用函数和方法
除方法外,Scala还支持函数,例:
import scala.math._
sqrt(2)Scala没有静态方法,其对应的类似特性为单例对象(singleton object)。
Scala的类可以有个伴生对象(companion object),该对象中方法类似与Java中的静态方法。
不带参数的Scala方法可以省略圆括号。
1.6 apply方法
在Scala中随处可见类似于函数调用的语法。
字符串中字符访问:
val hello = "hello"
hello(4) // 'o'
// equals to
hello.apply(4)在Scala中,使用伴生对象的apply方法创建对象很常见,例:
val num = BigInt("12345")
BigInt.apply("12345")1.7 Scaladoc
READ THE FUCKING SPECIFICATION AND DOCUMENT.
2 控制结构和函数
要点
- if表达式有值
- 块(block)也有值,是它最后一个表达式的值
- Scala的for循环
- 分号(;)在绝大多数下不是必需的
- void类型是
scala.Unit - 避免在函数中使用return
- 注意别在函数定义中遗漏=
- Scala的异常工作方式与Java基本一致,在catch语句中用模式匹配
- Scala没有受检异常
2.1 条件表达式
在Scala中if/else表达式有值,即if或else后表达式的值。
val s = if (x > 0) 1 else -1在Scala中每个表达式都有一个类型。
// type: Any
val s2 = if (x > 0) "positive" else -1无else部分:
val s3 = if (x < 0) -1
// euqalivant to
val s4 = if (x > 0) 1 else ()()的类型是scala.Unit,表示无用的值。Java中void表示没有值,而Unit表示没有值的值。
多分支示例:
val s4 = if (x > 0) 1 else if (x == 0) 0 else -12.2 语句终止
与Java不同,Scala的语句行尾不需要分号。
在单行中填入多个语句时,需要以分号隔开:
if (n > 0) { r = r * n; n -= 1 }2.3 块表达式和赋值
在Scala中,{}块中可以包含一组表达式,块中最后一个表达式的值是块表达式的值。
val distance = { val dx = x - x0; val dy = y - y0; Math.sqrt(dx * dx + dy * dy) }注意:Scala中赋值语句的类型是Unit。x = y = 1,则x的值为()。
2.4 输入和输出
println(), C风格的printf。
与console交互:scala.io.StdIn.readLine、scala.io.StdIn.readInt等。
2.5 循环
Scala有while和do循环语法。
Scala没有for(init; check; update)循环语法,其for循环的语法是:for( variable <- expression)。
示例:
for (i <- 1 to n) { // [1, n]
r = r * i
}1 to n返回[1, n]的Range对象,循环变量i前没有val或var修饰符,其作用域在循环体中。
1 unitl n返回[1, n)的Range对象,即不包含n。
Scala没有直接提供break或continue来退出循环。一种mock:
import scala.util.control.Breaks._
breakable {
for (i <- 1 to n) {
print(i + " ")
if (i == 5) break;
}
}2.6 高级for循环和for推导式
使用 variable <- expression的形式提供生成器,多个生成器之间用分号隔开。
for (i <- 1 to 3; j <- 1 to 3) print((10 * i + j) + " ")每个生成器可以带有一个护卫,其是if开头的布尔表达式。
for (i <- 1 to 3; j <- 1 to 3 if i != j) print((10 * i + j) + " ")如果for中循环体以yield开始,则构造出一个集合,这种循环称为for推导式。
val resultOfYield = for (i <- 1 to 3) yield i % 3for推导式生成集合的类型与第一个生成器的类型是兼容的。
println(for (c <- "Hello"; i <- 0 to 1) yield (c.toInt + i).toChar)
println(for (i <- 0 to 1; c <- "Hello") yield (c.toInt + i).toChar)2.7 函数
方法对对象进行操作,而函数不是。在Java中只能用静态方法模拟。
def abs(x : Double) = if (x >= 0) x else -x
def factor(x : Int) = {
var r = 1
for (i <- 1 to x) r = r * i
r
}
def factor2(x : Int) : Int = if (x <= 0) 1 else x * factor2(x - 1)必须指定函数参数的类型。只要函数不是递归的,就不需要指定函数的返回类型。
一定不能遗漏=。
2.8 默认参数和带名参数
函数定义中可以指定参数的默认值。
调用函数时也可以指定参数名,带名参数调用不需要与函数定义中参数列表顺序相同。
混合使用未命名参数和命名参数调用函数时,需要保证未命名参数排在前面。
def decorate(str : String, left : String = "[", right : String = "]") = left + str + right
println(decorate("Hello"))
println(decorate("Hello", "<<<", ">>>"))
println(decorate("Hello", right = "]<<<"))2.9 变长参数
def sum(args : Int*) = {
var result = 0
for (arg <- args) result += arg
result
}函数参数args的类型是Seq,可以使用任意数量的参数值调用:
val s = sum(1, 2, 3, 4, 5)以Range类型值调用时,需要转换(_*):
sum(1 to 5 : _*)2.10 过程
过程(procedure)是没有=的函数,其返回类型是Unit。
为保持与函数语法的一致,也可以显式将过程以函数语法定义:
def p(s: String) {}
def p(s: String): Unit = {}2.11 懒值
将val变量声明为lazy时,该变量的初始化将被延迟,直到首次对其取值时。
可以将lazy视为介于val和def的中间状态:
// 定义时立即求值
val words = scala.io.Source.fromFile("file.txt", "utf-8").mkString
// 首次使用时求值
lazy val words2 = scala.io.Source.fromFile("file.txt", "utf-8").mkString
// 每一次使用时求值
def words3 = scala.io.Source.fromFile("file.txt", "utf-8").mkString2.12 异常
Scala抛出异常方式与Java一样:throw new Exception("wrong"),抛出的对象必须是java.lang.Throwable的子类。
Scala没有受检异常概念:不用声明函数或方法可能会抛出的异常。
Scala的throw表达式的类型是Nothing。在if/else表达式中,如果一个分支的类型是Nothing,则整个表达式的类型是另一个分支的类型。
Scala异常捕获语法使用模式匹配:
var stream : InputStream = null
try {
stream = new URL("http2://www.google.com").openStream()
} catch {
case _ : MalformedURLException => println("Bad URL!")
case t : Throwable => t.printStackTrace()
} finally {
if (stream != null) {
stream.close()
}
}3 数组相关操作
要点
- 若长度固定使用Array,若长度可能有变化则使用ArrayBuffer
- 提供初始值时不要使用new
- 用
()访问元素 - 用for(elem <- arr)遍历元素
- 用for(elem <- arr)... yield ...将原数组转型为新数组
- Scala数组和Java数组可以互操作;用ArrayBuffer,使用scala.collection.JavaConversions中的转换函数
3.1 定长数组
需要一个长度不变的数组时,使用scala的Array。
在JVM中,scala的Array以Java数组的方式实现。
val nums = new Array[Int](10)
val a = new Array[String](10)
// companion object's `apply`
val s = Array("Hello", "World")
// modify element
s(0) = "Greeting"3.2 变长数组:数组缓冲
变长数组在Scala中为ArrayBuffer。
一些常见的操作:
val b = ArrayBuffer[Int]()
b += 1
b += (1, 2, 3, 5)
b ++= Array(8, 13, 21)
b.trimEnd(5)在数组缓冲的尾部添加或删除元素是高效的操作。
在数组缓冲中任意位置插入或移除元素:
b.insert(2, 5)
b.insert(2, 7, 8, 9)
b.remove(2)
b.remove(2, 3)数组和数组缓冲之间的转换:
val ss : Buffer[String]= s.toBuffer
val bb : Array[Int] = b.toArray3.3 遍历数组和数组缓冲
用for循环遍历数组或数组缓冲:
val arr = Array(1, 2, 3, 4, 5, 6)
for (i <- 0 until arr.length) {
print(arr(i) + " ")
}每两个元素一跳,即存在步长:
for (i <- 0 until (arr.length, 2)) {
print(arr(i) + " ")
}反向遍历:
for (i <- (0 until arr.length).reverse) {
print(arr(i) + " ")
}不需要访问数组下标:
for (i <- arr) {
print(i + " ")
}3.4 数组转换
使用for推导式,不修改原始数组,产生全新的数组。
val arr = Array(1, 2, 3, 4, 5, 6)
// yield
val arr2 = for (e <- arr) yield 2 * e
// yield with guard
val arr3 = for (e <- arr if e % 2 == 0) yield 2 * e3.5 常用算法
数值数组/数组缓冲求和:
Array(1, 2, 3).sum求最大和最小元素:
Array(1, 2, 3).min
ArrayBuffer("Mary", "Had", "a", "little", "lamb").max排序:
val b = ArrayBuffer(1, 7, 2, 8)
val bSorted = b.sorted指定比较函数排序:
val bDescending = b.sortWith(_ > _)数组原位替换排序:
val arr = Array(1, 7, 2, 8)
scala.util.Sorting.quickSort(arr)输出内容:
arr.mkString(" and ")
arr.mkString("<", ",", ">")3.6 解读scaladoc
AGAIN, READ THE FUCKING DOCUMENT.
3.7 多维数组
Scala的多维数组与Java一样,是通过数组的数组来实现的。
// 3 rows, 4 columns
val matrix : Array[Array[Double]] = Array.ofDim[Double](3, 4)
// access
matrix(1)(2) = 42
for (row <- matrix) {
for (col <- row) {
print(col + " ")
}
println
}创建不规则的数组(非矩阵):
val triangle = new Array[Array[Int]](10)
for (i <- 0 until triangle.length) {
triangle(i) = new Array[Int](i + 1)
}3.8 与Java的互相操作
引入scala.collection.JavaConversions中的隐式转换方法。
Scala to Java
import scala.collection.JavaConversions.bufferAsJavaList
val command = ArrayBuffer("ls", "-al", "/home")
// java.lang.ProcessBuilder(List<String>)
val pb : ProcessBuilder = new ProcessBuilder(command)Java to Scala
import scala.collection.JavaConversions.asScalaBuffer
val cmd : Buffer[String] = pb.command()
println(cmd.asInstanceOf[ArrayBuffer[String]])
// they are the same
println(cmd == command)4 映射和元组
要点
- Scala支持易用的语法来创建、查询和遍历映射
- 需要从可变映射和不可变映射中作出选择
- 默认情况下是使用哈希映射,可以指定树形映射
- Scala支持在Scala映射与Java映射之间的转换
- 元组用来收集值
4.1 构造映射
创建不可变映射:
val scores = Map("Alice" -> 10, "Bob" -> 3, "Cartman" -> 8)
// or
val scores_ = Map(("Alice" -> 10), ("Bob" -> 3), ("Cartman" -> 8))在Scala中,->操作符用来创建对偶:"Alice" -> 10产生("Alice" -> 10)。
创建可变映射:
val scores_mutable = scala.collection.mutable.Map(("Alice" -> 10), ("Bob" -> 3), ("Cartman" -> 8))创建指定类型的空映射:
val scores_empty = scala.collection.mutable.HashMap[String, Int]4.2 获取映射中的值
使用()记法获取映射中的值,如果映射中不包含指定的键则抛出异常。
val bobScore = scores("Bob") 使用contains检查键值是否存在:
val bobScore2 = if (scores.contains("Bob_")) scores("Bob_") else 0
// a shortcut
val bobScore3 = scores.getOrElse("Bob", 0)map.get(key)返回的是Option对象。
4.3 更新映射中的值
只能对可变映射执行更新、添加和删除操作:
val scores_ = scala.collection.mutable.Map(("Alice" -> 10), ("Bob" -> 3), ("Cartman" -> 8))
// update
scores_("Alice") = 8
// add
scores_ += ("Frank" -> 5, "Green" -> 6)
// remove
scores_ -= "Green"对不可变映射执行操作:
(1) val immutableMap
val scores = Map("Alice" -> 10, "Bob" -> 3, "Cartman" -> 8)
// new map
val newScores = scores + ("Frank" -> 5, "Green" -> 6)(2) var immutableMap
var map = Map("Alice" -> 10, "Bob" -> 3, "Cartman" -> 8)
map = map + ("Frank" -> 5, "Green" -> 6)注意:可变/不变的对象引用和可变/不可变的对象。
4.4 迭代映射
遍历:
val scores = Map("Alice" -> 10, "Bob" -> 3, "Cartman" -> 8)
for ((key, value) <- scores) {
println(key + ": " + value)
}访问键或者值:
scores.keySet // Set[String]
scores.values // Iterable生成新的映射:
val scores2 = Map("Alice" -> 10, "Bob" -> 3, "Cartman" -> 3)
val scores_ = for ((key, value) <- scores2) yield (value, key)4.5 已排序映射
Scala的不可变树形映射:
val scores = scala.collection.immutable.SortedMap("Alice" -> 10, "Doug" -> 2, "Bob" -> 3, "Cartman" -> 8)4.6 与Java的互操作
还是使用scala.collection.JavaConversions中便捷的隐式转换方法。
//1 java to scala
import scala.collection.JavaConversions.mapAsScalaMap
val scores : scala.collection.mutable.Map[String, Int] = new java.util.TreeMap[String, Int]
// 2 java properties to scala map
import scala.collection.JavaConversions.propertiesAsScalaMap
val props : scala.collection.mutable.Map[String, String] = System.getProperties
//3 scala to java
import scala.collection.JavaConversions.mapAsJavaMap
val scalaMap = Map("A" -> 1, "B" -> 2)
val javaMap : java.util.Map[_, _] = scalaMap4.7 元组
Scala中元组(tuple)是不同类型的值的聚集,映射中的项(即对偶)是元组的特例。
元组定义:
val tuple = (1, 3.14, "Alice")其类型解读为:Tuple3[Int, Double, java.lang.String]或者(Int, Double, java.lang.String)。
元组中元素(组元)访问:
println(tuple._1)
println(tuple._2)
println(tuple._3)以模式匹配方式获取组元:
val (first, second, third) = tuple
println(first)
println(second)
println(third)
val (first_, second_, _) = tuple
println(first_)
println(second_)4.8 zip操作
压缩生成对偶数组:
val symbols = Array("<", "-", ">")
val count = Array(2, 10, 2)
// an array of tuple
val pairs = symbols.zip(count)
for ((s, c) <- pairs) {
print(s * c)
}可以使用toMap将对偶的集合转换为映射:
val map = pairs.toMap5 类
要点
- 类中的字段自动带有getter/setter
- 统一访问原则
@BanProperty生成JavaBeans的getter/setter方法- 每个类都有一个主要的构造器,这个构造器与类定义在一起。它的参数直接成为类的字段。主构造器执行类体中的所有语句。
- 辅助构造器是可选的,叫做this
5.1 简单类和无参方法
在Scala中,类并不声明为public。Scala源文件中可以包含多个类,所有这些类具有public可见性。
class Counter {
// must initialize variable
private var value = 0
// default is `public`
def increment() { value += 1 }
// def current() = value
def current = value
}
object Counter extends App {
val myCounter = new Counter // or new Counter()
myCounter.increment() //setter
println(myCounter.current) //getter
}调用对象的无参方法时可以省去()。一种好的实践是对setter方法使用(),而getter方法不使用。
5.2 带getter和setter的属性
Scala对类中每个字段都提供了getter和setter方法。
class Person {
// public field
var publicAge = 0
// private fields
private var privateAge = 0
// val field: final
val valAge = 0
// Scala getter
def age = privateAge
// Scala setter
def age_=(newAge : Int) {
if (newAge > privateAge) privateAge = newAge
}
}
// 定义伴生对象为App是不好的实践,这里为了方便
object Person extends App {
val person = new Person
// 1 public var field
// auto generated getter/setter
println(person.publicAge)
person.publicAge = 10
println(person.publicAge)
// 2 public val field
// auto generated getter
println(person.valAge)
// 3 self defined getter/setter
person.age = 30 //call age_=(30)
person.age = 21
println(person.age) //call age()
} 解读:
(1) publicAge为公有字段,生成的JVM类中有一个私有字段publicAge和相应的getter/setter方法;
(2) privateAge为私有字段,生成的JVM类中getter/setter方法也是私有的;
(3) 对应于类中字段age,Scala的getter/setter方法分别写为age和age_=。总是可以重新定义getter和setter方法。
查看Scala生成的class文件
$ scalac xxx.scala
$ javap -private xxxScala对每个字段生成getter/setter解读
(1) 字段是私有的,则生成的getter/setter也是私有的
(2) val字段,只有getter生成
(3) 不需要任何getter/setter时,将字段声明为private[this]。
5.3 只带getter的属性
对应于类Person中字段valAge,Scala会生成一个私有的final字段和一个getter方法,但没有setter方法。
实现属性的选择:
(1) var foo: Scala自动生成getter/setter
(2) val foo: Scala自动生成getter
(3) 自定义foo和foo_=方法
(4) 自定义foo方法
在Scala中,不能实现只写属性,即只带setter不带getter的属性。
5.4 对象私有字段
一般,类中方法可以访问该类的所有对象的私有字段。
限定不可访问另一个对象的私有字段:
private[this] var instanceValue = -1对于对象私有的字段,Scala不生成getter/setter方法。
Scala允许将访问权限赋予指定的类:使用private[类名]修饰符。约束只有指定类的方法可以访问指定的字段。类名必须是当前定义的类,或包含该类的外部类。Scala会对此字段生成辅助的getter/setter方法。
class PrivateField {
// 1 private field
private var value = 0
// 2 private object field
private[this] var instanceValue = -1
//3 private class field
private[PrivateField] var classValue = -2
def increment() { value += 1 }
// can access other's private field
def isLess(other : PrivateField) = value < other.value
// cannot access private[this] field of another instance
// def isGreater(other : PrivateField) = instanceValue > other.instanceValue
def isGreater(other : PrivateField) = classValue > other.classValue
}
class CNestedClasses {
class InnerClass {
// TODO WTF???
//private[this] var innerField: Int
private[CNestedClasses] var innerField = -1
def compare(other : InnerClass) = {
innerField > other.innerField
}
}
def outerMethod() = {
val innerInstance = new InnerClass
val innerInstance2 = new InnerClass
innerInstance.compare(innerInstance2)
}
}
object PrivateField extends App {
val instance = new PrivateField
val instance2 = new PrivateField
// object field
println(instance.isLess(instance2))
// class field
println(instance.isGreater(instance2))
// nested class
val outerInstance = new CNestedClasses
println(outerInstance.outerMethod)
}5.5 Bean属性
将Scala字段标注为@BeanProperty时,会生成相应的Java属性。
class Person{
@BeanProperty var name: String =_
}将生成四个方法:
name: String
name_=(newValue: String): Unit
getName(): String
setName(newValue: String): Unit通常@BeanProperty也可以用在主构造器上:class Person(@BeanProperty var name: String)。
书中的总结:

5.6 辅助构造器
辅助构造器的名称为this。
每个辅助构造器必须以调用另一个辅助构造器或者主构造器开始。
class Person {
private var name = ""
private var age = 0
// 辅助构造器(auxiliary constructor)
def this(name : String) {
this() // call primary constructor
this.name = name
}
// another auxiliary constructor
def this(name : String, age : Int) {
// call another auxiliary constructor
this(name)
this.age = age
}
}5.7 主构造器
Scala的每个类都有主构造器。没有显式定义主构造器的类自动有一个无参的主构造器。
主构造器不以this方法定义,而与类的定义放在一起:
1 主构造器的参数直接放在类名之后;
2 主构造器会执行类定义中的所有语句。
class Person(val name : String, val age : Int) {
//
println("executing primary constructors")
def description = name + " is " + age + " years old."
}主构造器中参数与字段的总结:

私有的主构造器: class Person private(val id: Int) {}
5.8 嵌套类
Scala对内嵌的语法结构支持程度很高,可以在函数中定义函数,在类中定义类等。
class Network {
class Member(val name : String) {
// val contacts = new ArrayBuffer[Member]//1
// 类型投影, any Network's Member
val contacts = new ArrayBuffer[Network#Member] //2
}
private val members = new ArrayBuffer[Member]
def join(name : String) = {
val m = new Member(name) // inner class
members += m
m
}
}
object NetWork_App extends App {
val n1 = new Network
val n2 = new Network
val m1 = n1.join("m1")
val m2 = n1.join("m2")
m1.contacts += m2 // OK
val m3 = n2.join("m3")
// WRONG: m1.Member is different from m3.Member
//m1.contacts += m3 // 1 FAIL
m1.contacts += m3 // 2 OK
}在Scala中每个实例都有它自己的Member类,即n1.Member和n2.Member是两个不同的类。
在内嵌类中访问外部类的this,可以通过外部类.this,或者:
class Network2(val name : String) { outer => // replace of `this`
class Member(val name : String) {
def description = name + ", " + outer.name
def description2 = name + ", " + Network2.this.name
}
}6 对象
要点
- 用对象作为单例或存放工具方法
- 类可以拥有一个同名的伴生对象
- 对象可以扩展类或特质
- 对象的apply方法通常用来构造伴生类的新实例
- 如果不想显式定义main方法,可以用扩展App特质的对象
- 可以扩展Enumeration对象来实现枚举
6.1 单例对象
Scala中没有Java中静态方法或静态字段的对应物,替代物是用object这个语法结构定义对象。
对象定义了某个类的单个实例:
object Accounts {
private var lastNumber = 0
def newUniqueNumber = { lastNumber += 1; lastNumber }
}Scala中欧给你对象可以实现:
1 存放工具函数和常量的地方
2 共享单个不可变实例
3 实现单例
对象本质上可以拥有类的所有特性。
6.2 伴生对象
对应于Java中同时有实例方法和静态方法的类,Scala中可以使用伴生对象实现。
类和它的伴生对象可以相互访问私有特性,它们必须在同一个源文件中。
对于类来说,可以访问其伴生对象,但伴生对象并不在作用域中。
class Account {
//class and its companion object can access
// each other's private field
val id = Account.newUniqueNumber
private var balance = 0.0
def deposit(amount : Double) {
balance += amount
}
}
// companion object(伴生对象)
// class and its companion object must in the same source file
object Account {
private var lastNumber = 0
def newUniqueNumber = { lastNumber += 1; lastNumber }
}6.3 扩展类或特质的对象
一个object可以扩展类以及一个或多个特质,其结果是一个扩展了指定类和特质的类的对象、同时有在对象定义中给出的所有特性。
// class
abstract class UndoableAction(val description : String) {
def undo() : Unit
def redo() : Unit
}
// companion object as a default implementation
object DoNothingAction extends UndoableAction("Do nothing") {
override def undo() {}
override def redo() {}
}
object Action_app extends App {
val actions = Map("open" -> DoNothingAction, "save" -> DoNothingAction)
println(actions)
}6.4 apply方法
Object(param1, param2, ...)这个apply方法返回的是伴生类的对象。
class Account_ private (val id : Int, initBalance : Double) {
private var balance = initBalance
def currentBalance = balance
}
// companion object
object Account_ {
private var lastNumber = 0
// return companion class's object
def apply(initBalance : Double) = new Account_(newUniqueNumber, initBalance)
def newUniqueNumber = { lastNumber += 1; lastNumber }
}6.5 应用程序对象
App特质扩展自特质DelayedInit,所有带有该特质的类,其初始化方法都会被挪到delayedInit方法中。
App特质的main方法捕获到命令行参数,调用delayedInit方法。
object Hello {
def main(args : Array[String]) {
println("Hello")
}
}
object HelloApp extends App {
// access command line arguments through the `args`
if (args.length > 0) {
println(args(0))
} else {
println("HelloApp")
}
}6.6 枚举
Scala没有枚举类型。可以借助Enumeration类定义一个对象,并以Value方法调用初始化枚举中的所有可选值。
object ColorEnum extends Enumeration {
val Red, Yellow, Green = Value
val Blue = Value(4, "Blue")
// default name is field's name
val White = Value(5)
val Black = Value("Black")
}
object _main extends App {
// the 'enum''s type is ColorEnum.Value not ColorEnum
println(ColorEnum.Red.isInstanceOf[ColorEnum.Value])
println
import ColorEnum._
println(Red)
println(Yellow)
println(Green)
println(Blue)
println(White)
println(Black)
println
// access all values of ColorEnum
for (c <- ColorEnum.values) println(c.id + ": " + c)
// access enum with id or name
println(ColorEnum(0))
println(ColorEnum.withName("Red"))
}7 包和引入
要点
- 包可以像内部类那样嵌套。
- 包路径不是绝对路径。
- 包声明链x.y.z并不自动将中间包x和x.y变成可见。
- 位于文件顶部的不带花括号的包证明在整个文件范围内有效。
- 包对象可以持有函数和变量。
- 引入语句可以引入包、类和对象。
- 引入语句可以出现在任何位置。
- 引入语句可以重命名和隐藏特定成员。
- java.lang、scala和Predef包总是被引入。
7.1 包
与对象或类的定义不同,同一个包可以定义在多个文件中。
可以在同一个文件中为多个包贡献内容。
7.2 作用区规则
Scala的包和其他作用域一样支持嵌套,可以访问上层作用域中的名称。
在Scala中,包名是相对的。
使用绝对包名,以_root_开始,例如:
val clients = new _root_.scala.collection.mutable.ArrayBuffer[Object]7.3 串联式包语句
包可以包含一个“串”,或者说路径区段。
package com.horstman.impatient {
// com和com.horstman中的成员在这里不可见
package people {
class Person {}
}
}7.4 文件顶部标记法
package com.horstman.impatient
package people
class Person_ { println("......") }7.5 包对象
包可以包含类、对象和特质,但不能包含函数或变量的定义。
每个包可以有一个包对象,在父包中定义它,其名称与子包一样。包对象中可以放置函数和变量。
对源文件使用相同的命名规则是好习惯,一般将包对象放到诸如com/spike/package.scala的文件中。
7.6 包可见性
package com.horstman.impatient
class UserInnerMethod {
// can be access because of private[impatient]
def _description = "Hello" + new people.Person_().upperDescription
// cannot be accessed
//def __description = "Hello" + new people.Person_().description
}
package people {
class Person_ {
// access package object's constant variable
var name = defaultName
// only seen in this package
private[people] def description = "description"
// can be seen in upper package
private[impatient] def upperDescription = "upperDescription"
}
}7.7 引入
import java.awt.Color
import java.awt._
def handler(evt: event.ActionEvent){} // access subpackages7.8 任何地方都可以引入声明
class Manager{
import scala.collection.mutable._
}7.9 重命名和隐藏方法
选择器(selector):
import java.awt.{Color, Font}重命名:
import java.util.{HashMap => JavaHashMap}隐藏:
// HashMap => _
import java.util.{HashMap => _, _} 7.10 隐式引入
import java.lang._
import scala._
import Predef._以scala开头的包可以省略scala.,如collection.mutable.HashMap等价于scala.collection.mutable.HashMap。
8 继承
要点
- extends, final关键字与Java中相同。
- 重写方法时必须用override。
- 只有主构造器可以调用超类的主构造器。
- 可以重写字段。
8.1 扩展类
class Employee extends Person {
...Scala中final的含义与Java一致。
8.2 重写方法
在Scala中重写一个非抽象方法必须使用override关键字。
override修饰符可以给出有用的错误提示:
- 拼错了要重写的方法名
- 在新方法中使用了错误的参数类型
- 在���类中引入了新方法,但这个新方法与子类的方法冲突。
调用超类方法: super.toString等。
8.3 类型检查和转换
obj.isInstanceOf[C1] => obj instanceof C1
obj.asInstanceOf[C1] => (C1) obj
classOf[C1] => C1.class模式匹配通常是更好的选择。
8.4 protected字段和方法
protected成员可以被任何子类访问,但不能从其他位置访问。
与Java不同,Scala的protected成员对类所属的包而言是不可见的。
protected[this]修饰符号:跟private[this]类似,将访问权限限制在当前的对象。
8.5 超类的构造
辅助构造器永远都不能调用超类的构造器,只有主构造器可以调用超类的构造器,注意这里的超类的构造器不一定是其主构造器。
Scala的类可以扩展Java类,其主构造器必须调用Java类的一个构造方法。
8.6 重写字段
可以在子类中用同名的val字段重写超类的中的val字段(或不带参数的def)。
更常见的是用val重写抽象的def。
限制
- def只能重写另一个def
- val只能重写另一个val或不带参数的def
- var只能重写另一个抽象的var
8.7 匿名子类
和Java一样,在Scala中可以通过包含带有定义或重写的代码块的方式创建匿名子类。
例:
class Person(val name : String) {}
val alice = new Person("Alice") {
def greeting = "greeting " + this.name
}
匿名子类可以理解为是一种结构类型,相应的可以作为参数类型定义:
def meet(p : Person { def greeting : String }) {
println(p.greeting)
}其类别标记为Person { def greeting : String }。
8.8 抽象类
和Java一样,可以用abstract关键字来表示不能被实例化的类。
在子类中重写超类的抽象方法时,可以省略override关键字。
8.9 抽象字段
Scala类除抽象方法外,还可以拥有抽象字段。
抽象字段就而是一个没有初始值的字段。
具体的子类必须提供具体的字段。也可以使用匿名子类重写抽象字段。
8.10 构造顺序和提前定义
超类会在子类构造前被构造。
提前定义语法可以在超类的构造器执行钱初始化子类的val字段。
一个示例:
class Creature {
val range : Int = 10
val env : Array[Int] = new Array[Int](range)
}
class Ant extends Creature {
override val range = 2
}
// predefinition
class Ant2 extends {
override val range = 2
} with Creature
object Main extends App {
val ant = new Ant
println(ant.range)
// since `Creature` is construct before `Ant`
println(ant.env.length) // 0
val ant2 = new Ant2
println(ant2.range)
println(ant2.env.length) // 2
}8.11 Scala继承层次
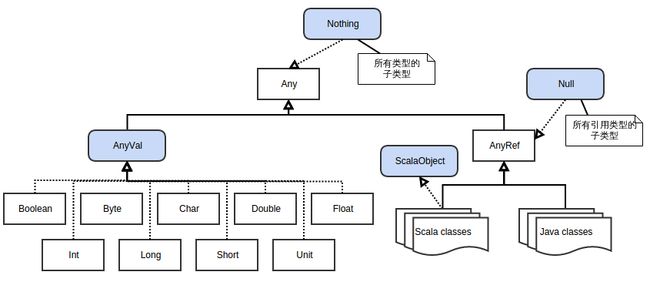
8.12 对���相等性
Scala中,AnyRef的eq方法会检查两个引用是否指向同一个对象,其equals方法默认调用eq。
应用重写类的equals和hashCode方法,以提供业务实例的相等性判断。
对引用类型,==会在null检查后调用equals方法。
9 文件和正则表达式
要点
- Source.fromFile(...).getLines.toArray输出文件的所有行
- Source.fromFile(...).mkString以字符串形式输出文件内容
- 将字符串转换为数字,可以用toInt或toDouble方法
- 使用Java的PrintWriter来写入文本文件
- "<正则>".r是一个Regex对象
- 如果正则表达式中包含反斜杠()或引号("),可以使用"""..."""
- 如果正则表达式包含分组,使用如下语法提取内容:for(regex(var1, ..., varn) <- 字符串)
9.1 读取行
用scala.io.Source对象处理文件。
import scala.io.Source
// 1 read lines
val source1 = Source.fromFile(currentDir + "myfile.txt", "UTF-8")
// get line iterator
val lineIter = source1.getLines
for (line <- lineIter) println(line)
// read again??? NO!
println(lineIter.isEmpty)
// close Source
source1.closegetLines返回的是一个迭代器,可以对该迭代器使用toArray或toBuffer进行转换。
文件较小时,可以使用Source#mkString将整个文件读取成一个字符串。
9.2 读取字符
Source对象扩展了Iterator[Char],可以逐字符处理。
调用Source对象的buffered方法,可以在返回的迭代器上调用head查看而不是消耗下一个字符。
9.3 读取词法单元和数字
调用toInt或toDouble方法将字符串转换为数字。
使用StdIn.readInt()从终端读整数。
9.4 从URL或其他源读取
使用Source.fromURL()方法从URL中读取内容。
使用Source.fromString()方法从字符串中读取内容,方便调试。
使用Source.stdin从终端读去内容。
9.5 读取二进制文件
Scala没有提供读取二进制文件的方法。
9.6 写入文本文件
Scala没有提供写入文件的支持。
9.7 访问目录
Scala没有正式提供访问目录的支持。
9.8 序列化
@SerialVersionUID(-1L)
class Person extends SerializableScala的集合类都是可序列化的。
9.9 进程控制
sys.process包中有从字符串到ProcessBuilder对象的隐式转换。用!操作符执行,例:
import sys.process._
val result1 : Int = "ls -al .." !
val result2 : String = "ls -al .." !!管道和重定向
"ls -al .." #| "grep scala" !
import java.io.File
"ls -al .." #| "grep scala" #> new File("output.txt") !
"ls -al .." #| "grep scala" #>> new File("output.txt") !
"grep scala" #< new File("output.txt") !进程间逻辑运算符
p #&& q // 如果p执行成功,则执行q
P #|| q // 如果p执行失败,则执行q使用Process对象:
// parameter: command, start directory
val p = Process("pwd", new File("/home/zhoujiagen/local_git_repository/scala/scala"), ("LANG", "en_US"))
// execute it
p!9.10 正则表达式
用String类的r方法构造Regex对象。
val numPattern = "[0-9]+".r如果正则表达式中包含\或",建议使用""""""(原始字符串语法)。
val wsNumwsPattern = """\s+[0-9]+\s+""".r一些Regex对象的方法
numPattern.findAllIn(testString)
wsNumwsPattern.findFirstIn(testString)
numPattern.findPrefixOf(testString)
numPattern.replaceFirstIn(testString, "XX")
numPattern.replaceAllIn(testString, "XX")9.11 正则表达式组
与Java类似,在要提取的子表达式两侧加上括号,构成组。
要匹配组,可以将正则表达式对象作为提取器使用。
val numItemPattern = "([0-9]+)\\s+([a-z]+)".r
// regex object as an extractor
val numItemPattern(number, item) = "99 alice"
println(number)
println(item)
// extract multiple matches
for (numItemPattern(number, item) <- numItemPattern.findAllIn(testString))
println(number + ": " + item)10 特质
要点
- 类可以实现任意数量的特质
- 特质可以要求实现它们的类具备特定的字段、方法或超类
- 和Java接口不同,Scala特质可以提供方法和字段的实现
- 将多个特质叠加在一起时,顺序很重要:其方法先被执行的特质排在更后面
10.1 为什么没有多重继承
Scala和Java一样,不允许类从多个超类继承。
Scala提供了特质(trait)而非接口。特质可以同时拥有抽象方法和具体方法,类可以实现多个特质。
10.2 当作接口使用的特质
Scala的特质完全可以像Java中的接口一样工作。
类扩展特质,用extends关键字。用with关键字连接扩展的多个特质。
特质中未被实现的方法默认就是抽象的。在重写特质的抽象方法时,不需要给出override关键字。
10.3 带有具体实现的特质
在Scala中,特质中的方法并不需要一定是抽象的。
类扩展带有具体实现的特质,称该特质被“混入”了类。
这种情况下,当特质改变时,所有混入了该特质的类都必须重新编译。
10.4 带有特质的对象
在构造单个对象时,可以为它添加特质。
10.5 叠加在一起的特质
可以为类或对象添加多个相互调用的特质,从最后一个开始。
对特质而言,super.someMethod并不像类那样拥有相同的含义。super.someMethod调用的是级联的特质层次中的下一个特质,具体是哪一个,要按照特质被添加的顺序。一般来说,特质是从最后一个开始被处理。
对特质而言,无法直接从源代码中判断super.someMethod会执行哪里的方法。如果想控制具体是哪一个特质的方法被调用,可以使用限定语法:super[DirectlyParentTrait].someMethod,这里给出的类型DirectlyParentTrait必须是当前特质的直接超类型。
10.6 在特质中重写抽象方法
特质中没有提供方法实现,在其子特质中提供的方法实现中调用super.someMethod,需要在子特质实现方法前加上abstract关键字,即该方法仍是抽象的。
10.7 当作富接口使用的特质
特质可以包含大量工具方法,而这些方法依赖一些抽象方法来实现。使用该特质的类可以任意调用这些工具方法。
10.8 特质中的具体字段
特质中的字段可以是具体的,也可以是抽象的。
如果给出字段的初始值,则字段就是具体的。
对于特质中每个具体字段,扩展/混入该特质的类都会获得一个与之相应的字段。这些字段不是被继承的,而是简单的被添加到类中。
10.9 特质中的抽象字段
特质中未被初始化的字段在具体的子类中必须被重写。
这种提供特质参数值的方式在临时构造对象时很便利。
10.10 特质构造顺序
和类一样,特质也可以有构造器,有字段的初始化和其他特质体中的语句构成。
构造器以如下顺序执行:
(1) 首先调用超类的构造器
(2) 特质构造器在超类构造器之后、类构造器之前执行
(3) 特质由左至右被构造
(4) 每个特质当中,父特质先被构造
(5) 如果多个特质共有一个父特质,且父特质已经被构造,则父特质不会被再次构造
(6) 所有特质构造完成后,子类被构造
一个示例:
object ConstructorsOfTrait extends App {
// output:
// Account
// Logger
// FileLogger
// ShortLogger
// SavingAccount
val account = new SavingAccount
}
trait Logger {
println("Logger")
def log(msg : String) {}
}
trait ConsoleLogger extends Logger {
println("ConsoleLogger")
override def log(msg : String) {
println(msg)
}
}
trait FileLogger extends Logger {
println("FileLogger")
// body of trait, as part of constructor of trait
val out = new PrintWriter("account.log")
out.println("# " + new java.util.Date().toString())
out.flush()
override def log(msg : String) {
out.println(msg)
out.flush()
}
}
trait ShortLogger extends Logger {
println("ShortLogger")
// abstract field
val maxLength : Int
override def log(msg : String) {
super.log(
if (msg.length > maxLength) msg.substring(0, maxLength) + "..." else msg
)
}
}
class Account {
println("Account")
var balance = 0.0
}
class SavingAccount extends Account with FileLogger with ShortLogger {
println("SavingAccount")
var interest = 0.0
// should override abstract filed in trait
val maxLength = 5
def withDraw(amount : Double) {
if (amount > balance) log("Insuffient funds")
else balance -= amount
}
}10.11 初始化特质中的字段
特质不能有构造器参数,每个特质都有一个无参数的构造器。
从技术上讲,缺少构造器参数是特质与类的唯一区别。
因特质的构造器会早于子类构造器执行,对特质字段的初始化需要一些奇怪的语法:
(1) 在带有特质的对象中使用提前定义语法;
(2) 在类定义中extends之后使用提前定义语法;
(3) 在特质构造器中使用lazy值。
an example:
object InitialFieldsInTrait extends App {
// use case of predefinition in object
val account = new {
val filename = "account.log"
} with SavingAccount with FileLogger
account.withDraw(1.0)
// use case of predefinition in class definition
val account2 = new SavingAccount2
account2.withDraw(1.0)
// use case of lazy filed
val account3 = new SavingAccount with LazyFileLogger {
val filename = "account3.log"
}
account3.withDraw(1.0)
}
trait Logger {
def log(msg : String) {}
}
trait FileLogger extends Logger {
val filename : String
import java.io.PrintStream
val out = new PrintStream(filename)
override def log(msg : String) {
out.println(msg)
out.flush()
}
}
trait LazyFileLogger extends Logger {
val filename : String
import java.io.PrintStream
// use `lazy`: evaluated when firstly used
lazy val out = new PrintStream(filename)
override def log(msg : String) {
out.println(msg)
out.flush()
}
}
class Account {
var balance = 0.0
}
class SavingAccount extends Account with Logger {
var interest = 0.0
def withDraw(amount : Double) {
if (amount > balance) log("Insuffient funds")
else balance -= amount
}
}
// predefinition in class definition
class SavingAccount2 extends {
val filename = "account2.log"
} with Account with FileLogger {
var interest = 0.0
def withDraw(amount : Double) {
if (amount > balance) log("Insuffient funds")
else balance -= amount
}
}10.12 扩展类的特质
特质也可以扩展类,这个类将会自动成为所有混入该特质的类的超类。
特质T扩展了类TSC,如果混入该特质的类C已经扩展了另一个类CSC时,只要CSC是特质的超类TSC的一个子类即可。如果CSC与TSC没有此关系,则C不能混入特质T。
10.13 自身类型
除了扩展类的特质中对能够混入该特质的子类类型的约束外,Scala还提供了自身类型(self type)对一般的特质能够混入的类的类型做约束:
trait SomeTrait extends ...{
this: 类型Type =>
}则该特质SomeTrait只能被混入类型Type的子类。
自身类型同样也可以处理结构类型(structural type):这种类型只给出类必须拥有的方法,而不是类的名称。
10.14 背后发生了什么
Scala需要将特质翻译成JVM的类和接口。
(1) 只有抽象方法的特质被简单的变成一个Java接口;
(2) 如果特质有具体的方法,Scala会创建一个伴生类,该伴生类用静态方法存放特质的方法;
(3) (2)中的伴生类不会有任何字段。特质中的字段对应于接口中抽象的getter/setter方法,当某个类实现该特质时,这些字段被自动加入;
(4) 如果特质扩展了类,则伴生类并不继承这个超类,该超类会被任何实现该特质的类继承。