C#与C++的发展历程第一 - 由C#3.0起
俗话说学以致用,本系列的出发点就在于总结C#和C++的一些新特性,并给出实例说明这些新特性的使用场景。前几篇文章将以C#的新特性为纲领,并同时介绍C++中相似的功能的新特性,最后一篇文章将总结之前几篇没有介绍到的C++11的新特性。
C++从11开始被称为现代C++(Modern C++)语言,开始越来越不像C语言了。就像C#从3.0开始就不再像Java了。这是一种超越,带来了开发效率的提高。
一种语言的特性一定是与这种语言的类型和运行环境是分不开的,所以文章中说C#的新特性其中也包括新的.NET Framework和CLR(DLR)对C#的支持。
由于C#2.0除了泛型,迭代器yield,foreach等与Java等有所不同,其它没有特别之处,所以本系列将直接从C#3.0开始。
C#3.0 (.NET Framework 3.5, CLR 2.0 下同)
C# 对象初始化器与集合初始化器
在对象初始化器出现之前,我们实例化一个对象并赋值的过程代码看起来是很冗余的。比如有这样一个类:
|
1
2
3
4
5
6
|
class
Plant
{
string
Name{
get
;
set
;}
string
Category{
get
;
set
;}
int
ImageId{
get
;
set
;}
}
|
实例化并赋值的代码如下:
|
1
2
3
4
|
Plant peony =
new
Plant();
Peony.Name =
"牡丹"
;
Peony.Category=
"芍药科"
;
Peony.ImageId=6;
|
如果我们需要多次实例化并赋值,为了节省赋值代码,可以提供一个构造函数:
|
1
2
3
4
5
6
|
Plant(
string
Name,
string
Category,
int
ImageId)
{
Name = name;
Category=category;
ImageId= imageid;
}
|
这样就可以直接调用构造函数来实例化一个对象并赋值,代码相当简洁:
|
1
|
Plant peony =
new
Plant(
"牡丹"
,
"芍药科"
,6);
|
如果我们只需要给其中2个属性赋值,或者类中又增加新的属性,原来的构造函数可能不能再满足要求,我们需要提供新的构造函数重载。
现在有了对象初始化器,我们可以使用更简单的语法来实例化对象并赋值:
|
1
2
3
4
5
6
|
Plant peony =
new
Plant
{
Name =
"牡丹"
,
Category=
"芍药科"
,
ImageId= 6
}
|
我们可以根据需求随意增加或减少对属性的赋值。
接着来看看集合初始化器,习惯了对象初始化的语法,集合初始化器是水到渠成的:
|
1
2
3
4
5
|
List< Plant > plants =
new
List< Plant > {
new
Plant { Name =
"牡丹"
, Category =
"芍药科"
, ImageId =6},
new
Plant { Name =
"莲"
, Category =
"莲科"
, ImageId =10 },
new
Plant { Name =
"柳"
, Category =
"杨柳科"
, ImageId = 12 }
};
|
另一个常用的小伙伴Dictionary<K,V>类的对象也可以用类似的方式实例化:
|
1
2
3
4
5
6
|
Dictionary<
int
, Plant > plants =
new
Dictionary<
int
, Plant>
{
{ 11,
new
Plant { Name =
"牡丹"
, Category =
"芍药科"
, ImageId =6},
{ 12,
new
Plant { Name =
"莲"
, Category =
"莲科"
, ImageId =10 },
{ 13,
new
Plant { Name =
"柳"
, Category =
"杨柳科"
, ImageId = 12 }
};
|
使用对象初始化器或集合初始化器时赋值部分调用构造函数的圆括号可以省略,直接以花括号开始属性赋值即可。
在下文介绍匿名类和隐式类型数组时还会看到对象初始化器和集合初始化器的语法。
注意:对于C#3.0的新特性基本上都可以说是语法糖,因为运行的CLR没有变,只是编译器帮我们将简化的语法编译成我们之前需要手写的复杂的方式。
C++11 统一的初始化语法
C++11中统一了初始化对象的语法,这语法与C#的对象初始化器是孪生兄弟,就是一对花括号 – {}。我们由基本类型的初始化说起。
在C++11之前,我们初始化一个int一般写出这样:
|
1
|
int
i(3);
|
或
|
1
|
int
i = 3;
|
参见本小节末:初始化和赋值的区别
使用新的初始化语法可以写为:
|
1
|
int
i{3};
|
同样char类型对象新的初始化方式:
|
1
|
char
c{
'x'
};
|
使用赋值的方式下,下面代码是可以工作的:
|
1
|
int
f=5.3;
|
赋值完成后f的值为5,编译器进行了窄转换,而使用新的初始化方式,窄转换就不会发生,即下面的代码无法通过编译:
|
1
|
int
f{5.3};
//注意,类型不匹配,无法通过编译
|
接着看一下类类型的例子:
我们使用与C#部分类型的类:
|
1
2
3
4
5
6
7
8
9
10
11
|
class
Plant
{
public
:
Plant();
virtual
~Plant();
string m_Name;
string m_Category;
unsigned
int
m_ImageId;
protected
:
private
:
};
|
不同于C#使用{}初始化类成员时需要显式指定类成员名称,C++类通过定义构造函数来获知初始化列表中参数的顺序。我们可以这样实现一个Plant类的构造函数,其中冒号开始的语法被称为"构造函数初始化列表":
|
1
2
3
4
|
Plant::Plant(string _name,string _category,unsigned
int
_imageId)
:m_Name(_name),m_Category(_category),m_ImageId(_imageId)
{
}
|
别忘了在头文件中给新的构造函数重载加个声明,然后就可以这样实例化一个Plant对象了:
|
1
|
Plant plant{
"牡丹"
,
"芍药科"
, 6};
|
上面的例子都是在栈上分配的对象,对于堆上分配的对象,也可以使用new关键字加上新的初始化方式,如对于前面的Plant类,可以使用这种方式在堆上实例化一个新的对象:
|
1
|
Plant *plant =
new
Plant{
"牡丹"
,
"芍药科"
, 6};
|
对于struct,不需要实现重载构造就可以使用统一的初始化语法:
|
1
2
3
4
5
6
|
struct
StPlant
{
string m_Name;
string m_Category;
unsigned
int
m_ImageId;
};
|
可以直接这样实例化一个StPlant对象:
|
1
|
StPlant stplant{
"牡丹"
,
"芍药科"
, 6};
|
在C++中声明,定义,初始化和赋值有着概念上的大不同,这对于用惯C#这样不太区分这种概念的语言的同学可能感觉很不理解。下面依次介绍下这几个概念:
声明,例如:
externinti;在类型名前添加一个extern关键字表示声明一个变量,这个变量在其他链接的文件中被定义。C++中一个变量可以被声明很多次但只能被定义一次。
定义:
inti;定义是最常见的,注意,定义的同时也表示声明了这个变量。
初始化,初始化的方式有两种:
inti(5);inti = 5;前者是直接初始化,后者是拷贝初始化。这两者的不同是前者是寻找合适的拷贝/移动构造函数,后者是使用拷贝/移动赋值运算符。C++11后明确引入了右值及移动语意,初始化的性能大大提高。
赋值:
inti;i=5;这样把定义与赋值分开,则赋值的过程一定是调用拷贝/移动赋值运算符,而不是通过构造函数来完成。
最后看看下面这种写法:
externinti = 5;这样extern会被忽略,这是一个定义(含声明)及拷贝初始化变量的语句,且这个变量不能被再次定义。
C++11 初始化列表
标准库中的容器也可以使用统一的初始化方式进行填充:
|
1
|
std::vector<
int
> vec = {0, 1, 2, 3, 4};
|
更复杂一点的栗子:
|
1
2
3
4
5
|
vector<Plant> plants = {
{
"牡丹"
,
"芍药科"
, 6},
{
"牡丹"
,
"芍药科"
, 6},
{
"牡丹"
,
"芍药科"
, 6}
};
|
同样std::map系列容器也可以使用类似的方式初始化:
|
1
2
3
4
5
|
map<
int
, Plant> plantsDic = {
{1, {
"牡丹"
,
"芍药科"
, 6}},
{2, {
"牡丹"
,
"芍药科"
, 6}},
{3, {
"牡丹"
,
"芍药科"
, 6}}
};
|
C++11对初始化列表支持的背后,一个其关键作用的角色就是新版标准库新增的std::initializer<T>模板类。编译器可以将{list}语法编译为std::initializer<T>类的对象。新版库中的容器也都添加了接收std::initializer<T>类型参数的构造函数重载,所以上面示例的几种写法都可以被支持。vector中增加的构造函数形如:
|
1
|
template
<
typename
T> vector::vector(std::initializer_list<T> initList);
|
我们也可以在自己的函数实现中使用std::initializer<T>作为参数,如下代码:
注意:使用std::initializer<T>需要#include <initializer_list>
|
1
2
3
4
5
6
7
8
9
|
void
GetGoodNum(std::initializer_list<
double
> marks) {
unsigned
int
num = 0;
// 统计80分以上学生人数
for_each (marks.begin(), marks.end(), [&num](
double
& m) {
if
(m>80) {
num++;
}
})
}
|
这样我们就可以向函数传递一个{list}列表。
|
1
|
GetGoodNum({100,70.5,93,84,65});
|
这个例子用到了C++11的lambda表达式,后文有关于这个语法的介绍。
C# 隐式类型、匿名类和隐式类型数组
隐式类型
C#3.0中新增了var关键字。使用var关键字可以简化一些比较长,比较复杂不容易记忆的类型名的输入。不同于Javascript中的var,C#中的var在编译之后会被替换为原有的类型,所以C#中var还是强类型的。
举几个简化我们输入的例子吧。Tuple是一个比较复杂的泛型类(下篇文章会有介绍),如果没有var,我们实例化一个Tuple对象的代码就像:
Tuple<string,string,int> plant = Tuple.Create("莲","莲科",1);使用var代码就可以简化为:
varplant = Tuple.Create("莲","莲科",1);在foreach循环中也常常是var的用武之地
foreach(varkvpindictionaryObj){}如果没有var,我们就要手写KeyValuePair<K,V>类型的名称,如果遍历的集合类是一个不常见的类型,诸如Enumerable.ToLookup()和Enumerable.GroupBy()方法返回的值,可能都记不清其中每一项的具体类型。使用var就可以轻松表示这一切。
var和后面要介绍的Linq也是结合最紧密的,一般Linq返回的都是一个类型非常复杂的对象。使用var能减少很大的编码工作量,使代码保持整洁。
匿名类
如果我们将前文介绍的对象初始化器语法中的new关键字类型去掉,这样就得到了匿名类,如:
varpeony =new{Name ="牡丹",Category="芍药科",ImageId= 6}匿名类中所有属性都是只读的,且其类型都是自动推导得来不能手动指定。当两个匿名类型具有相同的属性,则它们被认为是同一个匿名类型
如这个对象:
varpeach =new{Name ="桃花",Category ="蔷薇科",ImageId = 7,};判断类型的话,它们是相同的:
varsametype = peony.GetType() == peach.GetType();匿名类型的属性可以直接用另一个对象的属性来初始化:
varfootball =new{Name ="足球",Size ="Big",peach.ImageId,};这样football中就会有一个名为ImageId的属性,且值为7。当然也可以自定义名称,如果属性名相同省略就好。这种用法在LINQ的Select扩展方法中接收的lambda表达式创建新的匿名对象时常常会见到。
隐式类型数组
通过隐式类型数组这个特性,声明并初始化数组时也不用显式指定数组类型了。编译器会自动推导数组的类型,如:
一维数组
vara =new[] { 1, 10, 100, 1000 };// int[]varb =new[] {"hello",null,"。world"};// string[]交错数组
vard =new[]{new[]{"Luca","Mads","Luke","Dinesh"},new[]{"Karen","Suma","Frances"}};隐式类型数组也可以包含匿名类对象,当然所有的匿名类对象要符合同一个匿名类的定义。
参考下面这段示例代码:
varplants =new[]{new{Name ="莲",Categories=new[] {"山龙眼目","莲科","莲属"}},new{Name =" 柳",PhoneNumbers =new[] {"金虎尾目","杨柳科","柳属"}}};
C++11 类型推导
在C++中同样由于模板类型的大量使用导致某些类型的对象的类型不容易记忆及书写。C++11提供了auto关键字来解决这个问题。auto关键字的用法与C#中的var极为相似,即在需要指定具体类型的地方代之以auto关键字,如方法返回值前,以范围为基础的for循环中。
如:
string s("some lower case words");for(autoit=s.begin(); it!=s.end && !isspace(*it); ++it);*it=toupper(*it);//转换为大些字母在C++11中还有一个更为强大的定义类型的操作符 - decltype。我们直接看一个例子,再来说明这个关键字的用法:
string s("some words");decltype(s.size()) index=0;代码中s.size()返回值的类型为string::size_type,decltype使用这个类型来定义index变量,代码中第二句相当于:
string::size_type index=0;通过decltype可以简化很多类型的记忆及书写,编译器将在编译时自动以正确的类型替换。
关于decltype更详细的讨论,推荐学习C++ Primer(第5版)2.5.3节内容,其中讲述的decltype和引用的问题尤其值得认真学习。
C# 扩展方法
C#的扩展方法主要是为已存在,且不能或不方便直接修改的其代码的类添加方法。比如,C#3.0中为实现IEnumerable<T>接口的类型添加了如Where,Select等一些列扩展方法,从而可以以Fluent API的方法实现与LINQ等价的功能。这样,除了一些复杂的如join等通过LINQ语法实现更方便外,其他一些如简单的where通过Where扩展方法来完成则会使代码有更好的可读性。
怎样实现扩展方法?还是通过一个例子来介绍更直观:
在写代码时我们常遇到需要将一个集合以指定分隔符合并成一个字符串,即String.Join()方法完成的功能。一般的写法如下:
varlist =newList<int>() {1,2,3,4,5};list = list.Where(i=>i%2==0).ToList();varstr =string.Join(";", list);可能你会想如果能在第二行代码一次生成字符串可能更方便,我们通过扩展IEnumerable<T>来实现这个功能:
publicstaticclassEnumerableExt{publicstaticstringStrJoin<T>(thisIEnumerable<T> enumerable,stringspliter){returnstring.Join(spliter, enumerable);}}可以看到扩展方法需要定义在静态类中,且扩展方法自身也需要是静态方法。扩展方法所在的类的名字不重要,相对而言这个类所在的命名空间的名字更重要,因为是通过引用的命名空间让编译器知道我们扩展方法来自于哪里。扩展方法最重要的部分为第一个参数,这个参数前面有一个this,表示我们要扩展这个参数的类型,扩展方法主要执行在这个参数对象上。除此之外实现扩展方法和实现一般方法相同。使用这个扩展方法重写之前的代码后:
varlist =newList<int>() {1,2,3,4,5};varstr = list.Where(i=>i%2==0).StrJoin(",");当然这个扩展方法不满足Fluent API传入参数和返回值类型相同的要求,但作为调用链最后一个方法未尝不可。
扩展方法这个特性C++没有类似功能,没得写。
C# Lambda表达式
在lambda表达式出现之前,只能通过委托表示一个函数,通过委托的实例或匿名函数来表示一个“函数对象”。有了lambda表达式,C#2.0中出现的匿名函数就可以退役了。lambda表达式可以完全取代匿名函数实现的功能。而且.NET Framework新增的Action及Func<T>系列委托类型也可以减少我们自定义委托类型的必要。
C#的lambda表达式的语法概括如下:
参数部分 => 方法体
对于参数部分,如果有2个或2个以上的参数需要用小括号括起来,lambda表达式的参数部分参数无需指定类型,编译器会自动进行类型推导。当然也可以明确指定参数类型:
(intx) => x+1;对于方法体部分如果只有一条语句则无需加{},且对于有返回值的方法体也可以省略return关键字。如果是超过一条语句则需要{}且对于有返回值的情况不能省略return,如:
x => { x=x+1;returnMath.Pow(x,2);}C#中lambda表达式一般用于各种和委托类型相关的场景,比如一个方法接收委托类型参数或返回一个委托类型对象。在实现Fluent API样式的LINQ语法的那些扩展方法中很多都是接收委托类型的参数,如:
IEnumerable<TSource> Where<TSource>(thisIEnumerable<TSource> source, Func<TSource,bool> predicate)IEnumerable<TResult> Select<TSource, TResult>(thisIEnumerable<TSource> source, Func<TSource, TResult> selector)调用这些方法时,相应的参数传入lambda表达式就可。
关于闭包
闭包指的是在一个lambda表达式的方法体中访问了不属于这个方法体的外部变量。在C#4.0以及早期版本的编译器中,对于下面个例子(例子来源)的执行会产生和一般想法不太一样的结果:
varvalues =newList<int>(){ 10, 20, 30};varfuncs =newList<Func<int>>();foreach(varvalinvalues){funcs.Add(() => val);}foreach(varfinfuncs){Console.WriteLine((f()));}乍一看来这段代码会依次返回10,20,30。但在C#4.0及之前(编译器随VS版本而变,可以用VS2012之前的版本测试)的编译器上测试执行返回3个30。如果VS安装有Resharper,会得到复制一份变量到本地的提示。
这是因为foreach中这个循环变量如果换成for的形式如下:
intval;for(vari=0;i<3;i++){val = values[i];...}所以lambda表达式捕获到的是一个相对于循环作用域的外部变量,最终捕获到的是循环的最终值30。要想让结果正确需要把foreach每次的变量复制到本地一份:
varvalues =newList<int>(){ 10, 20, 30};varfuncs =newList<Func<int>>();foreach(varvalinvalues){intvalLocal = val;funcs.Add(() => valLocal);}foreach(varfinfuncs){Console.WriteLine((f()));}这样输出结果就是符合一般思维的10,20,30了。
在C#5.0及以后的编译器中,遇到这种情况会自动复制一份本地实例到循环体中,从而保证结果符合大众思维。
关于Func<>与Action<> (.NET Framework 3.5)
在早期版本的.NET定义委托要使用delegate关键字这样进行:
delegateintIamAdd(intleft,intright);定义这个委托的实例需要这样:
IamAdd addMethod =newIamAdd((l, r) => l + r);如果使用Func<>,则代码可以简化为:
Func<int,int,int> addMethod = (l, r) => l + r;颜值倍增吧。Func有多种重载,.NET Framework3.5中参数最多的重载可以接收最多4个参数,在.NET Framework4以后Func重载数量暴增,最多的重载可以接收16个参数。对于没有返回值的委托可以使用Action系列重载,和Func使用几乎一模一样。
C++11 Lambda表达式
在C#之后传统的面向对象语言也都纷纷加入lambda表达式,主要是C++和Java,作为一个微软狗,我认为C# lambda语法最漂亮,C++11的也不错,Java的和C++11差不多,不知道谁模仿的谁。论语法来说还是C++11的最复杂,这和C++本身有关,又是引用又是值又是指针的。类似C#中的lambda表达式主要用于接收委托类型的地方,C++中的lambda表达式主要用于接收函数指针的地方,可能是模板库中的方法也可能是自定义的方法。还是先来看一下C++11中lambda表达式的各种语法,然后在来举一个实际中应用的例子。
C++11中lambda表达式的一般语法如下:
[捕捉列表](参数) mutable ->返回类型 {方法体}
逐一来分析C++11 lambda表达式的组成部分:
[捕捉列表],这里的[]起到了告诉编译器下面部分是一个lambda表达式的效果。捕捉列表的作用在于,C++不像C#那样默认捕获所有父作用域的变量,而是需要程序员手动指定捕获那些变量。这部分可能的情况有如下几种:
[]:不捕获任何外部变量,当lambda表达式不属于任何块作用域时,捕获列表必须为空。
[var]:以传值方式捕获变量
[=]:以传值方式捕获所有变量
[&var]:以引用方式捕获变量
[&]:以引用方式捕获所有变量
[this]:以传值方式捕获当前的this指针
这些也是可以混合使用的,比如[&, a]表示使用传值方式捕获a,使用引用方式捕获其他所有变量。
(参数),C++11中参数列表必须指明类型,不能省略,这点与C#不同,如果参数是泛型则lambda中参数的类型用auto表示。另外如果不存在参数,则()可以省略。(如果存在mutable关键字,则即使参数列表为空也必须加上括号)
mutable关键字,默认C++11的lambda表达式为const函数,即方法体不能修改外部变量,可以通过添加mutable关键字将lambda转为非const函数。
->返回类型,在C++无法推断返回值类型的情况下,需要使用这个语法手动指定,否则包括箭头在内的返回类型可以直接省略,而使用自动推断。
方法体,C++中方法体必须放在{}中,即使只有简单的一行代码,且如果lambda有返回值return也不能省略。
说完C++11 Lambda表达式的语法,再来说说其应用。C++中应用Lambda表达式最多的地方还是标准库中以前接收函数对象的地方,尤其和容器相关的一些算法,下面一个小栗子足以说明一切:
std::vector<int> c{ 1,2,3,4,5,6 };std::remove_if(c.begin(), c.end(), [](intn) {returnn % 2 == 1; });在C#中,如果要引用Lambda表达式一般都使用Action或Function<T>。同样在C++引用Lambda表达式可以使用std::function,上面的Lambda表达式可以这样引用:
std::function<bool(int)> func = [](intn) {returnn % 2 == 1; };模板中,第一个类型表示返回值类型,参数的类型被放在括号中。
C++中Lambda的工作原理很简单。在内部编译器将lambda表达式编译为一个匿名对象,在其中有一个重载的函数调用运算符,其方法体即lambda表达式的方法体。
语言集成查询 - LINQ
自从C#3.0、.NET Framework3.5提供LINQ支持以后,LINQ已经成了.NET Framework中相当重要的一部分。当然这个LINQ应该不限于下面这种标准的LINQ语法:
int[] list = { 0, 1, 2, 3, 4, 5, 6 };varnumQuery =fromnuminlistwhere(num % 2) == 0,selectnum;还应包括以LINQ思想Fluent API方式的扩展方法的实现:
int[] list = { 0, 1, 2, 3, 4, 5, 6 };varnumQuery = list.Where(i=>i%2==0).Select(i=>i);之前看过一篇Java社区讨论该不该有LINQ的问题,好多人说Java 8中一种名为"Streams"的新语法比LINQ看起来好很多,其实那就是.NET Fluent API的克隆版,而出现却比.NET的实现完了n年,某些Java程序员还是很有阿Q精神,其实Java及其框架比C#落后好多这是不争的事实。继续正题...
LINQ的在.NET中用途太多了,.NET Framework内建对集合类型的LINQ to Object的支持,对XML支持的LINQ To XML,对数据库支持的LINQ to SQL。另外实体类框架的查询也是基于LINQ实现的,通过编写Provider你也可以实现自己的LINQ to xxx。
园子中介绍LINQ的文章的太多了,这一小节就简单介绍下LINQ的原理,并通过一个例子进行分析。至于如何实现自定义的Provider那样复杂的话题,请查找相关“专业”文章。
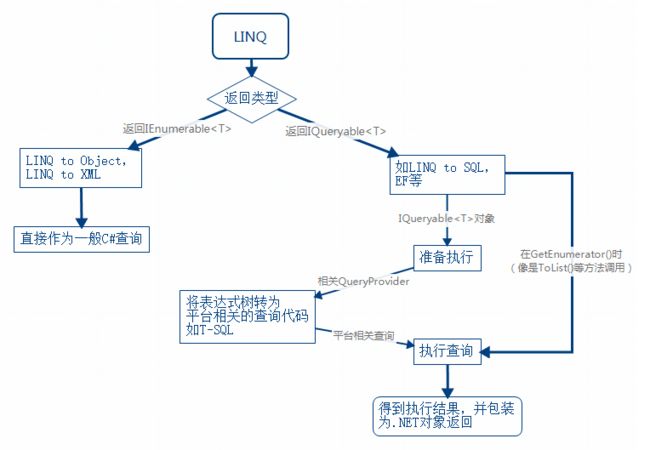
用XMind画了一个大体的流程图,电脑上实在没有其他方便的流程图工具。
图1
通过图可以看到除了LINQ to Object,其他LINQ to XXX都是被做为表达式树(ExpressionTree,下一小节会看到)在相应的QueryProvider上被“编译”,这个“编译”就是QueryProvider上的CreateQuery进行的工作。IQueryProvider接口定义了CreateQuery和Execute两个方法(算上泛型版本其实是4个)。我们自己实现LINQ to XXX时,最主要的就是实现IQueryProvider接口并在CreateQuery方法中将表达式树转为平台特定的查询,这个过程可能设计表达式树的遍历等,下一小节会做说明。在CreateQuery方法过后,平台相关查询就准备好了 ,但直到GetEnumerator方法被调用才会被实际执行。很多操作,如foreach或ToList都会让GetEnumerator被调用。实际执行平台相关查询实在Execute方法中发生的。
可以看到实现一个最基本的LINQ to XXX框架只需要实现IQueryable<T>和IQueryProvider接口两个方法就可以了。像是EF那种复杂的框架最底层也是通过这两个接口来完成,只是上层添加了许许多多其他装置。
本小节最后来一个小小的栗子吧,下面是一段EF中进行查询的代码:
varproductQuery =fromproductincontext.Set<Product>()whereproduct.Type == ProductType.Bookselectproduct.Name;varproducts = productQuery.ToList();结合上面的原理分析看一下这段代码,context.Set方法返回DbSet类对象,DbSet的父类DbQuery就是EF中实现IQueryable接口的类型。代码中的productQuery可以被看作是一个表达式树,当productQuery对象生成的时候,由EF实现的QueryProvider生成的T-SQL也就准备好了。当ToList方法被调用时,上面准备的T-SQL被发送到数据库执行并获得结果。
相信通过这一小节的介绍,大家应该对LINQ及其原理有个大概的介绍。这里强烈推荐李会军老师的一篇文章,仔细读过你就可以更好的理解本小节的内容,而且对实现自己的LINQ to XXX也能有更深入的了解。
下一小节谈谈上面反复提到的表达式树。
C# 表达式树
表达式树,顾名思义就是以树的形式来表示表达式。到底表达式树是什么样的呢?上一小节提到了LINQ中大量使用表达式树,我们去就那里面找找表达式树的痕迹。看一段简单的LINQ toSQL代码:
DataContext ctx =newDataContext("...connectionString...");Table<Product> products = ctx.GetTable<Product>();varproductQuery = products.Where(p => p.Name =="Book");看看其中定义在Queryable.cs文件中的Where方法
IQueryable<TSource> Where<TSource>(thisIQueryable<TSource> source, Expression<Func<TSource,bool>> predicate)有一个Expression<T>类型的参数,这就是我们要找的表达式树。
注意,在LINQ to Object或LINQ to XML的Where方法中是看不到Expression<T>类型的,LINQ部分讲过,这二者都是直接实现的查询方法没有经过QueryProvider。它们的Where方法定义在Enumerable.cs中,形如:
IEnumerable<TSource> Where<TSource>(thisIEnumerable<TSource> source, Func<TSource,bool> predicate)可以看到这个方法接收的参数就是一个普通的Func<T,T>委托对象,它们可以在.NET平台直接执行。
看到这问题来了,我们同样的lambda表达式既可以传递给表达式树,又可以传递给委托。那么表达式树和委托有什么不一样呢。其实它们区别还是很大的,lambda表达式本身就是委托类型,可以被看作一个委托的对象,它是一段可以直接被.NET编译运行的代码。而lambda到表达式树经历了由lambda变成一个LambdaExpression对象的过程。为了能更直观的看到表达式树的样子,把之前的代码稍作调整:
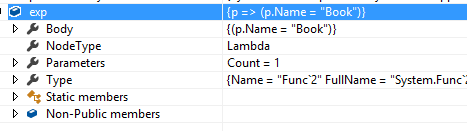
Expression<Func<Product,bool>> exp = p => p.Name =="Book";varproductQuery = products.Where(exp);来看一下exp这个表达式树对象在VS监视中的样子:
图2
如图,Parameters表示仅有一个参数Product类型的p,Body是Lambda的方法体,Type就是表达式树的类型Func<Product,bool>。最重要的就是这个NodeType,其值Lambda表示这个表达式是一个LambdaExpression。
通过上面的分析可以看到上面代码能成立最重要的一步就是编译器可以把Lambda转为LambdaExpression。对于像是上文这样一些简单的Lambda,.NET可以分析其组成并转为LambdaExpression,对于一些复杂的表达式,我们可能需要手动构造表达式树。
Expression抽象类包含了Add,Equal,Convert等数十中方法来表示表达式中的计算,通过这些方法的组合可以表示几乎所有的表达式。除了这些方法Expression中的Lambda方法用于生成LambdaExpression,这样手动构造的表达式树就可以用于接收表达式树的场景中。说了这么多,来看一下怎么手动构造上面提到的表达式:
ParameterExpression paraProduct = Expression.Parameter(typeof(Product),"p");MemberExpression productName = Expression.Property(paraProduct,"Name");ConstantExpression conRight = Expression.Constant("Book",typeof(string));BinaryExpression binaryBody = Expression.Equal(productName, conRight);Expression<Func<Product,bool>> exp = Expression.Lambda<Func<Product,bool>>(binaryBody, paraProduct);看起来很简单吧。Expression还提供了Compile方法把一个表达式树转为Lambda表达式:
Func<Product,bool> lambda = exp.Compile();说了这么多,表达式树到底有什么用呢。博主认为表达式树一个很大的作用就是把之前需要用字符串的地方换成了表达式,这种强类型可以在编译时被检查,有更好的稳定性。比如MVVM Light中那个经典的Set()方法:
boolSet<T>(Expression<Func<T>> propertyExpression,refT field, T newValue)这样可以通过表达式的方式设置更新的属性,这样比之前用propertyName那种字符串设置属性的方式更不容易出错。
当然表达式树还有很多用途,在.NET2.0时代我们获取一个对象的某个属性(在属性名为一个字符串的情况下),一般都是通过反射来完成。现在有了表达式树则可以使用表达式树来完成同样的工作。据测试速度要比反射快很多。这方面的文章网上有太多这里就不再多写了。同时像是老赵等大牛当年还讨论过表达式树的性能问题,如果需要大量应用表达式树这些都需要去仔细研究。这里就提下纲,对此不了解的园友可以按这个方向去查找相关文章学习。
与LINQ一样,这个在C++中也没有等价功能就不写了。
C# 其它细微变化
自动属性
C#的自动属性就是提供了对于属性传统写法一种更简洁的写法,比如下面是传统写法:
privateint_age;publicintAge{get{return_age; }set{ _age = value; }}如果我们无需使用_age,则可简写为:
publicintAge {get;set;}对于只读属性也可以:
publicintAge {get;}
分部方法
这个特性还真没发现有什么用,相对于分部类来说几乎没有应用场景。以一个例子简单说明:
publicpartialclassSample{partialvoidSamplePartialMethod(strings);}publicpartialclassSample{partialvoidSamplePartialMethod(String s){Console.WriteLine("Method Invoked with param:",s);}}分部方法并不能将实现分开放在两部分(显而易见,那样没法保证执行顺序),而是一部分提供一个类似声明的作用,而另一部分提供真正的实现。
值得注意的是,分部方法默认为private方法且必须返回void。
这两个语法糖也没见C++有等价的实现。