基于RGB-D数据的人体检测(People detection in RGB-D data)
基于RGB-D数据的人体检测
Luciano Spinello Kai O.Arras
摘要
人体检测是机器人和智能系统的一个重要问题。之前的工作使用的是摄像头和2D或者3D探测器。在这篇论文里,我们提出一种新的基于RGB-D数据的人体检测方法。我们的灵感来自HOG(the Histogram of Oriented Gradients),设计了一个稳定的基于稠密深度数据的人体检测方法,称之为HOD(Histogram of Oriented Depths)。HOD对局部深度变化的方向进行编码,并且依靠的是一个预知深度信息的尺度空间搜索,该搜索使检测过程获得3倍的加速。随后我们提出了Combo-HOD,一个以一定概率地结合了HOD和HOG的RGB-D检测器。实验包括和几个检测方法的综合比较,包括HOG方法、几个HOD的变形方法、用于3D点云的几何体检测器以及基于Haar的AdaBoost检测器。在最远8米范围内,等错误率为85%的情况下,实验结果显示HOD和Combo-HOD在用kinect传感器获得的室内环境的真实数据集上具有鲁棒性。
Ⅰ.引言
人体检测是许多机器人、交互系统和智能车辆的重要的又基础的组成部分。常用于人体检测的传感器是摄像机和测距仪。这两种传感器各有利弊,但是随着廉价而可靠的可以同时获得彩色图像和距离数据的RGB-D传感器的利用,它们的区别将成为过去。
在机器人领域里,很多研究者利用距离数据进行人体检测。早期的工作是利用2D距离数据[1][2]。在人体检测中利用3D距离数据是一个较新的问题。Navarro等[3]将3D数据分割成虚拟的2D切片,从中找到地平面上的显著的垂直目标并利用一系列SVM分类器特征对人体分类。Bajracharya等[4]从立体视觉的点云中,通过处理垂直目标,和考虑基于固定的行人模型的点云中的一系列几何和统计特征进行人体检测。这些方法都需要地平面假设,而Spinello等[5]通过对已分类部分投票的方法和自上而下的验证过程克服了这一限制,该验证过程可以学习最优特征集。
在计算机视觉领域,从单张图片中检测人体已经研究了很长时间。最近的工作,包括[6][7][8][9][10],使用的是基于人体各部分投票的方法或者滑动窗口搜索方法。在前一个方法中,人体各部分独立地对人体进行投票,在后一个方法中,固定尺寸的检测窗口在图像的不同的尺度空间位置上滑动来对每个区域进行分类。其他的研究提出多模型人体检测问题:[11]提出了一个可训练的2D距离数据和摄像机系统,[12]使用立体系统来结合图像数据、差异映射和光流,[13]使用灰度图和低分辨率的time-of-flight摄像机。
本文对人体检测领域的贡献如下:
· 我们提出了一个健壮的基于稠密深度信息的人体检测方法HOD(Histogram of Oriented Depths),灵感来自Histogram of Oriented Gradients(HOG)和kinect RGB-D传感器的深度特征。
· 我们基于一个已训练的尺度到深度的映射和一个新的积分图[14]使用方式进行预知深度信息的尺度空间搜索。
· 我们提出了Combo-HOD,一个新的利用RGB-D数据进行人体检测的融合方法。
· 实验包括和几个检测方法的综合比较,包括HOG方法、几个HOD的变形方法、用于3D点云的几何体检测器[5]以及基于Haar的AdaBoost检测器[15]。
注意我们的方法既不依赖于背景学习也不依赖于地平面假设。
论文的结构如下:Kinect传感器特性在下一节进行讨论,随后的SectionⅢ是基于稠密深度数据的HOD检测器以及在RGB-D数据中检测人体的Combo-HOD方法。Section Ⅳ中描述了数据集、性能度量方法和对比实验。SectionⅤ是总结。

图1 在RGB-D数据(右图)和彩色图像数据(左图)上检测人体。此方法既不依赖于背景学习也不依赖于地平面估计。
Ⅱ.kinect传感器特性
我们在此节中分析和讨论实验中用到的微软Kinect RGB-D传感器的特性。kinect传感器包括一个红外摄像机(IR Camera),一个红外发射器(IR Projector)和一个标准彩色摄像机,利用红外光结构原理[16]来测量深度。深度图分辨率为640*480,每个像素的位深度为11位。有趣的是,并不是所有的位都用来编码深度信息:超出距离范围的深度值(例如低于最小距离)被定为Vmax= 1084,深度最小值为Vmin= 290,所以,只有794个深度值(10位)来编码每个像素的深度信息。
原始深度值v和以米为单位的距离d之间的关系通过实验定义为[17]:

其中B = 0.075m,表示红外发射器和红外摄像机之间的距离(基线),Fx是红外摄像机在水平方向的焦距长度。d如果是负值则被忽略。公式(1)是双曲线关系,类似于深度与立体摄像机系统中点到点的对应关系。图2显示了v和d的关系,以及制造商所规定[18] 的传感器可靠工作的合理距离范围。空间被限制在设备前最远2m到2.5m。
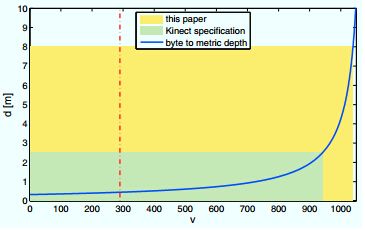
图2 Kinect深度数据的特点。蓝色曲线是深度图中的像素值与以米为单位的距离值间的关系。红色线表示传感器的最小测量深度。绿色区域是Kinect说明书中建议的合理使用范围,黄色区域是本文中用来检测人体时使用的距离范围。注意到我们是在建议距离范围的几乎4倍空间内进行人体检测,所以深度分辨率变得相当粗糙。
本文中,我们在0到8米的范围内检测人体,这几乎达到了说明书中的使用范围的4倍距离。深度分辨率上的损失使该研究具有挑战性。86.9%的深度值被用来编码0到2.5米间的深度信息,剩下仅有140个值来编码2.5到8米间的深度信息。这种效应,来自公式(1)的双曲线特征,在图3的两个不同距离的人的点云图上可以明显看出来。在前方大约2米处的人的形状很清晰,而远处的目标人体仅有几个点来描述,非常粗糙。这表明传感器远处目标的3D几何信息严重依赖于距离并且在距离传感器较远时会严重损失。
另一个效应,尤其在远距离上,是对物体表面材料的敏感性。强红外吸收表面会使发出去的红外光的返回信号时变得非常弱,这会导致块状的深度信息丢失。在图3的右图中显示出了这一效应。

图3 左图:双曲分辨率损失效应。传感器前不同距离的两个人的侧视图。近处的一个人被描述地精确而详细。越往远处量子化越严重,人体的形状信息损失严重。在这种数据上用于人体检测的几何方法将表现非常差。右图:远处的红外吸收表面会导致大量块状的深度数据丢失(如最左边的人的上半身,白色表示深度数据丢失)。
Ⅲ.基于RGB-D数据进行人体检测
在此节中介绍我们提出的检测器。首先总结一下普通图像的HOG检测器,然后介绍我们通过HOG方法而提出的用于稠密深度数据的新方法HOD,最后介绍结合两种方法的Combo-HOD方法。
A.HOG:Histograms of Oriented Gradients
由Dalal和Triggs[6]提出的Histograms of Oriented Gradients(HOG)方法是目前应用最广的视觉人体检测方法[9][10]。此方法使用一个固定尺寸的检测窗口,窗口被划分为以cell为单位的均匀网格。计算每个cell中像素的梯度方向并统计到一个一维直方图中。直观的表述就是局部外观和形状可以被局部梯度的分布很好地描述,而不需要知道这些梯度在网格中的精确位置。将一组cell聚合成blocks,进行局部对比度归一化。将所有block中的直方图串接起来,构成检测窗口的描述子向量,此描述子向量被用来训练线性SVM分类器。检测人体时,在图像的不同尺度空间滑动检测窗口,计算每个位置和尺度的HOG描述子,然后用学习好的SVM分类器进行分类。详见论文[6]。
B.HOD : Histograms of Oriented Depths
基于HOG的思想,我们提出一种新的用于稠密深度数据的人体检测器Histograms of Oriented Depths(HOD)。
1)操作原理:HOD在深度图像上遵循与HOG相同的处理流程。包括将固定窗口划分为cell,计算每个cell的描述子,将深度方向梯度统计到一维直方图中。四个cell组成一个block,并通过聚集和归一化使达到L2-Hys[6]的单元长度并从而对深度噪声具有更好的鲁棒性。直观的表达就是局部深度变化数组可以很好的描述局部3D形状和外表。最后得到的HOD特征向量被用来训练一个软线性SVM分类器,使用论文[6]中给出的两部训练方法。
2)深度图像预处理:在SectionⅡ中已讨论过,原始深度图对真实距离的编码非常不均匀。对于远处的目标,一个深度值可以对应15cm的距离变化。这对于HOG/HOD框架非常重要,因为在该方法中目标轮廓周围的block占有很大的权重。特别是那些对应具有最高正权重的SVM超平面的block。所以,我们对带有公式(1)的原始深度图进行预处理来加强前景和背景的分割。为了加强梯度计算的数值稳定性,将得到的以米为单位的深度值乘以M/Dmax,其中M = 100,表示恒定增益,Dmax = 20,是最大距离,单位为米。此预处理步骤类似用于加强深度图像对比度的伽马校正的思想。我们可以利用关于传感器的一些知识,用较好的身体模型来消除非线性影响。
3)预知深度信息的尺度空间搜索:多数视觉检测方法例如HOG使用在图像中的尺度空间的搜索来发现目标。在HOD方法中,我们可以利用深度信息来引导此搜索过程。有了预知深度信息的估计,搜索会更加高效和精确。
我们改进搜索过程的思想是提出一个快速区分深度图中每个位置上兼容的尺度的方法。首先,从训练数据集中计算出平均人体高度Hm,数据集中地面位置和每个样本的高度都做了精确标注。随后此信息按如下公式用来计算一个尺度到深度的映射(如图4中所示):
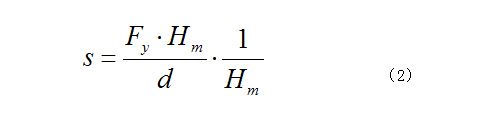
Fy是红外摄像机在垂直方向的焦距长度,Hm = 1.74m是人体的平均高度,Hw是检测窗口在尺度为1时的高度,单位为米。注意公式2左边的部分表示高度为Hm的半平面在距离d处垂直于摄像机的图像投影。为了限制内存使用,每1/3尺度对函数2进行一次量化。计算深度图中每个像素的尺度s,形成一个尺度映射,从中可以得到所有尺度的列表S。此列表S只包括图像中人体可能存在位置的尺度。此方法避免了在图像金字塔的所有尺度进行启发式搜索。
每个图像对应一个尺度列表S,然后进行尺度空间的搜素。搜索时,只有当搜索窗口的深度信息对应列表S中的尺度时,才拿到SVM分类器中进行分类。
解决这一问题的简单做法是选择尺度列表S中的一个尺度s,看检测窗口中每个位置的深度值是否与s兼容。这种方法需要扫描搜索窗口中的每个位置并测试是否有至少一个深度值与s兼容,计算复杂度很高,尤其是遇到大尺度时。
通过使用积分图[14],我们提出一种更快速地可在O(1)时间内完成的测试尺度是否兼容的方法。积分图是一种可快速计算矩形区域内像素值和的技术。积分图中每个点的像素值是原图中该点左上方所有点像素值的和。构建积分图的过程耗时O(N),N是原图的尺寸大小。使用积分图的主要优点是可通过4次减法快速计算面积积分。将此原理扩展到积分张量,即多层积分图,层数与受公式2量子化影响的S中的尺度个数相同。积分张量中的每层是一个二进制图像,其非白像素对应该层的尺度。这样就可以高效地测试给定搜索窗口是否包含至少一个某一尺度的像素。积分张量的构建每张图片需要进行一次。
检测时,选择S中的一个尺度s。对于每个搜索窗口位置,用积分张量中对应尺度s的层对搜索窗口进行面积积分。如果结果大于0,说明至少有一个与尺度s兼容的深度像素,则计算HOD描述子;否则该检测窗口不被考虑,继续测试下一个窗口。
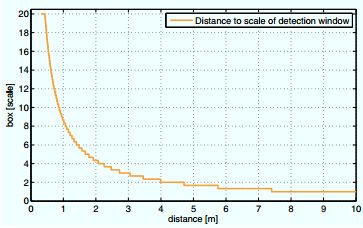
图4 ,反应米制深度与检测窗口尺度关系的量化回归曲线。曲线的最大尺度限制在20,以避免过大的检测窗口。
C. Combo-HOD : RGB-D人体检测
上面介绍的两种检测方法都是单独考虑彩色数据或距离数据。为了利用丰富的RGB-D数据,我们现在提出Combo-HOD,一种新的结合两种数据的检测方法。这种结合意义重大:深度数据对光照变化具有鲁棒性,但会受到返回信号强度过低的影响,并且分辨率有限。彩色图像具有丰富的数据颜色和纹理,较高的角坐标分辨率,但在非理想光线下很快失效。
Combo-HOD是分别在图像数据上训练一个HOG检测器,在深度数据上训练一个HOD检测器。此方法依赖于上面介绍的预知深度信息的尺度空间搜索:每个检测窗口都有一个对应的兼容的尺度,在深度图上计算HOD描述子,利用同一检测窗口在彩色图上计算HOG描述子。当无深度数据可用时,检测器自动退化为标准HOG检测器。需要一个校准程序来计算将两种图片合理对应起来的外部参数。
当HOG和HOD描述子都经过分类后,就该进行信息融合了。决策函数由HOD或HOG描述子和SVM超平面加偏移的点积的符号来给定。为了融合这两个信息,我们根据论文[19]中Platt等提出的方法,对每个SVM的输出拟合一个S型函数,将输出值映射到概率轴。来自HOD检测器的概率pD和HOG检测器的概率pG通过信息滤波器进行融合:
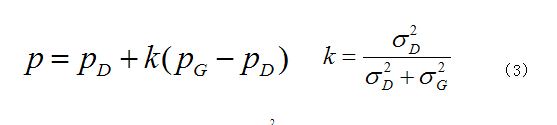
p是最终得到的检测出人体的概率,是验证集中错误率相同时HOD出错个数占HOG出错个数的比率,。
Ⅳ.实验
为了对比和评价不同的检测方法,我们收集了大量室内人体数据。数据集是在一个大学食堂午餐时间的大厅内收集的。此外还有一个在其他大学建筑内收集的数据集,专门用来产生背景样本。这是为了避免检测器学习到食堂大厅的背景,尤其是因为收集数据时传感器是固定的。数据集进行了人工标注,包括2D深度图中的目标边界框和可见状态(全可见/部分遮挡)。在1088张图片中总共标注了1648个人体实例。数据集可在作者的主页上获得。
我们使用的评价标准有精度-召回率和等错误率(ERR)。当检测结果与人工标注的目标重叠大于40%时,认为是正确检测。根据论文[9]中的不奖励不惩罚原则,若有检测结果与部分遮挡的人体匹配,既不记录为正确检测也不记录为误报。
用来训练所有检测器的训练集包括1030个人体深度数据样本(及其水平翻转镜像)和5000个从背景数据集中随机选出的负样本。
A.结果
实验将新的HOD检测器和其他基于深度的检测方法,基于视觉的检测方法,以及新的多模型RGB-D检测方法Combo-HOD进行了比较。
考虑到Kinect数据深度量化的重要性,我们评价了两种HOD变形方法:HOD11,考虑全部可用的11位深度数据;HOD8,只使用其中8位深度数据。还将使用其他预处理技术的HOD检测器与 Section Ⅲ-B 中的HOD方法进行比较。我们考虑了计算机视觉中的典型处理技术,包括对比度增强,光线均衡,例如平方根操作和对数操作,以及不做任何预处理。
图5中的左图清楚地显示出HOD11在整个精度-召回范围内都比HOD8表现好,这说明多余的3位深度编码有助于从背景中区分出人体。在深度数据上的所有预处理操作也都起到了作用(结果未在图5中展示)。对于HOD11,最好的预处理方法是Section Ⅲ-B中描述的方法,该方法证明了具有优秀理论的技术比启发式算法要好。特别地,HOD11的等错误率EER为83%,而HOD8最好的EER为75%。
谈论到RGB-D数据时,一个基本问题是深度信息对于纯视觉检测技术的贡献有多大。为估计这一贡献,我们考虑使用纯RGB数据的HOG检测器和由Viola和Jones[15]最初提出的基于Haar的Adaboost检测器(HA)。在图5的左图中可看到,这两种方法的表现都没有HOD11和Combo-HOD好,HOG方法的EER为73%,HA方法的EER为13%(未在图5中展示)。造成此结果的主要原因是光照,采集数据集的环境光线不太好。黑暗区域导致了移动人体的模糊图像,因为kinect RGB摄像机自动延长快门时间来产生更亮的图片。有阳光直射的背景区域会导致饱和的图像区域和较差的对比度。这些现象也会导致AH方法的失败,因为Haar微波对光线变化不是特别地稳健。结果说明对于在变化条件下工作的人体检测系统来说,单纯使用基于视觉的检测方法已不够用,需要使用深度信息来辅助进行检测。
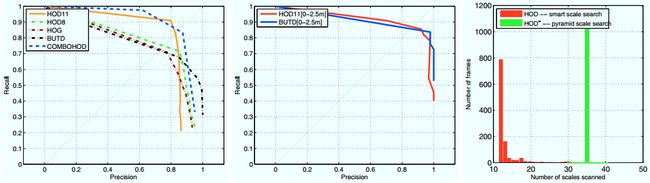
图5 左图 :几种检测方法的精度-召回率曲线。表现最好的是结合了HOD和HOG的RGB-D检测器Combo-HOD。有两种深度数据的HOD检测器,8bit深度数据和11bit深度数据。HOD11是表现最好的基于深度的检测方法。基于视觉的HOG检测器由于光照条件表现不是很好。BUTD检测器由于Kinect数据的双曲线深度分辨率损失表现不是很好。 中图 :在Kinect建议的最大2.5米使用范围内BUTD和HOD11的对比,两种方法性能表现相似。右图 :使用预知深度信息的尺度空间搜索时每张图片测试的尺度个数,和没有深度信息时(标记为HOD - )测试的尺度个数。尺度空间搜索加速了3倍。
同样重要的是与基于彩色图像技术的几何方法的对比。因此我们将HOD11与BUTD[5]进行了对比,BUTD是一个适用于稀疏3D数据的人体检测器,例如来自Velodyne传感器的点云数据。结果HOD11表现稍好(见图5的中图),EER为72%。注意BUTD自动退化并在召回率为53%时精度仍可以达到98%。然而,BUTD很大程度上依赖于形状信息,因此在距离较远处产生分辨率损失时会受很大影响。特别地深度数据量子化粗糙时,BUTD方法对距离图像的分割并不理想。然而,在分辨率很好的近处,两个检测器在ERR为86%时表现相近(见图5的中图)。这个结果表示,在有质量较好的数据时,基于形状的方法具有适用型。
图5的右图展示了HOD检测器的计算性能。我们比较了使用预知深度信息的尺度空间搜索时每张图片测试的尺度个数,和没有深度信息时(标记为HOD-)测试的尺度个数。HOD-使用尺度增量为5%的金字塔式搜索,不考虑图像内容。不像HOD中尺度是每张深度图中深度改变的一个变量。在整个数据集的图像上,测试的尺度个数降低了大约3倍,因此相对于HOD-每张图片的处理时间减少了大约3倍,见图5的右图。此算法完全在GPU上实现,可在Nvidia GTX480显卡上实时处理Kinect的RGB-D数据流(2*640*480,30fps)。
最终,和所有其他方法对比,本文提出的Combo-HOD检测器表现最好。在图5中Combo-HOD方法的EER值最高为85%。这说明结合使用深度信息和彩色图像信息可以提供更广泛的距离变化范围,使人体检测变得更可靠。多模态数据可在单一检测器无法处理时帮助改善人体检测。
图6是Combo-HOD检测器的检测结果。图中显示了几个在不同距离上检测出来的人体,其中包含一些部分遮挡和杂乱的情况。

图6 Combo-HOD检测器在RGB-D数据上的检测结果。在不同的部分遮挡、视觉和深度情况下进行人体检测。当两种传感器的数据都不可用时会发生 漏报 (False Negative),当两种数据都有杂波时会发生 误报 (FalsePositive)。第三列中,在无深度数据可用时仍可以检测出人体。我们的方法既不依赖于背景学习也不依赖于地平面估计。
Ⅴ. 总结
本文中介绍了Combo-HOD,一种新的利用RGB-D数据检测人体的方法。文中首先介绍了所用到的Kinect数据的特性,对我们所提出的方法有指引作用。深度方向直方图HOD对局部方向变化进行编码,依靠预知深度信息的尺度空间搜索可达到3倍的加速。然后将HOD和HOG结合,提出在RGB和深度数据上进行人体检测的Combo-HOD方法。在kinect传感器制造厂规定的操作空间的4倍距离内达到等错误率EER为85%。进一步通过对比试验深入分析了深度数据对纯视觉方法和基于形状的3D信息方法的贡献。可在GPU上达到30fps的实时检测,Combo-HOD方法比其他检测方法都要优秀。