Parallel FP-Growth for Query Recommendation翻译
近期又重新看起关联规则相关内容,看了自己写的关联规则源码分析,发现第二部分自己写的很不清楚,因为当时自己也不甚理解该算法。现在重新阅读此算法的相关论文,并做点翻译工作,仅供以后参考(只翻译了部分)。原文为:Parallel FP-Growth for Query Recommendation。
2. PFP:PARALLEL FP-GROWTH
FIM(频繁项集挖掘)的定义:I={a1,a2,...am}是一个项目的集合,一个事务数据库DB是I的一个子集,DB={T1,T2,...Tn},每一个Ti属于I(1<=i<=n),Ti属于一个事务。模式A(属于I)的支持度为supp(A),是这个某些事务(包含模式A)在整个DB中的个数。A是一个频繁模式且supp(A)>=ξ(ξ被定义为最小支持度阈值)。给定一个DB和ξ,这个问题就可以描述为在DB中寻找频繁模式集合,即为频繁项集挖掘问题。
2.1 FP-Growth Algorithm
FP-Growth体现了一种分治的策略。该算法需要扫描两次数据库,第一次扫描数据库时计算所有项目的频数,并按照此频数的降序排序生成一个F-List。在第二次扫描中所有数据库中的数据都被压缩为一个FP-tree。接着FP-Growth就开始挖掘这个FP-tree,即针对每一个满足supp()>ξ的项目递归的生成一个条件FP-tree。然后递归的挖掘这个FP-tree。所以就把寻找频繁项目集转换为递归地查找和创建树的过程。

图1显示了一个简单的例子。这个例子中DB有5个事务(每个事务由小写字母表示)。第一步就是排列每个事务的项目集,同时移除不是频繁的项目集。在这个例子中,设置ξ=3,比如对于第一行数据{f,a,c,d,g,i,m,p}就被转换为{f,c,a,m,p}。接着FP-Growth就压缩这个被转换后的事务到一个前缀树中。其中根节点是频数最大的项目,树上的每条路径显示了一个事务(共享相同的前缀),每个节点对应一个项目。树的每层对应一个项目,项目列表是用来连接事务的中相应的项目。FP-tree是一个压缩的,代表全部事务的同时支持快速访问所有事务(拥有相同的前缀项目)的一种数据结构。当树被建成后,就可以执行后缀模式了。但是这种结构还是不能减少可能的候选模式数量,这也是FP-Growth的瓶颈。算法1显示了FP-Growth的伪代码,可以推测出其创建F-List时间复杂度为O(DBSize)。但是Growth()的时间复杂度(算法2)至少也是多项式的。FPGrowth()递归的调用Growth(),所以导致多个条件Fp-tree被存储在内存中,这个也是此算法的瓶颈所在。


FP-Growth面临的挑战有:
1. 存储。对于一个非常大的DB来说,其相应的FP-tree也是十分大的,以至于不能存储于内存中。所以生成比较小的DB就很有必要,所以可以把DB分为比较小的DB,然后每个DB创建本地的可以被放入内存中的FP-tree;
2. 分配计算。所有的FP-Growth可以被并行化,特别是递归的调用Growth();
4. 支持度阈值。阈值越大生成的树储存的就越小,相应的时间就越少;反之亦然;
2.2 PFP Outline
PFP使用三个MR去实现PF-Growth算法。图2显示描述了PFP的5步:
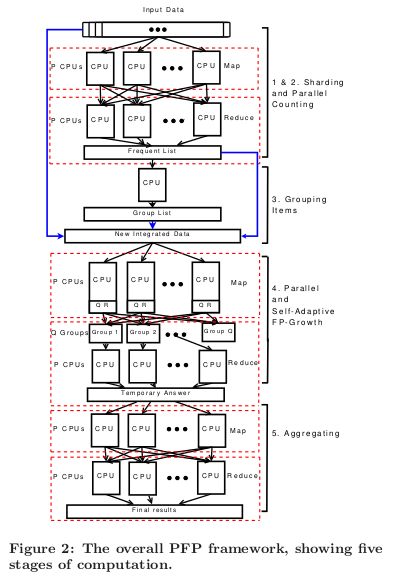
Step1:分割。分割DB到P台不同的电脑,每台电脑的部分数据称为分片(shard);
Step2:并行计算。使用一个MR计算所有项目的支持度。每个Mapper计算一个分片,最后的结果存储在F-list中;
Step3:划分项目组。把F-list分为Q组(每组为一个G-list),每组赋予一个唯一的组ID(gid),这个过程在一个电脑上完成;
Step4:并行FP-Growth。PFP的关键的一步,其Mapper和Reucer都是不同的操作;
Mapper:产生由组分配的事务集,事先读入G-list,输出一个或者多个key-value对,其中key为gid,value为由组分配的事务集;
Reducer:每个Reducer操作一个或者多个由组分配的分片,对于一个分片这个reducer建立一个本地的FP-tree,接着递归的建立条件FP-tree并且在递归的过程中输出发现的模式组合;
Step5:聚集所有的结果;
2.3 Parallel Counting,此部分可以参考:http://blog.csdn.net/fansy1990/article/details/8137942 ;
2.4 Parallel FP-Growth
这一步主要是转换DB中的事务到多个新的以组为分配的数据库中,这样本地创建FP-tree(根据本地的DB)在递归的创建条件FP-tree时就是相互独立的。算法4显示了该步的伪代码,相对于每个节点其空间复杂度为O(Max(NewDBSize));

2.4.1 Generating Transactions for Group-dependent Databases
当每个Mapper实例启动的时候,就会把G-list放入内存中(G-list足够小可以放入内存)。一般mapper读入G-list到一个hashmap中,把每个项目映射到相应的group-id。
对于每个Ti(属于DB),mapper执行下面的操作:
1. 对于每个项目aj(属于Ti),用相应的group-id替换aj;
2. For each group-id, say gid, if it appears in Ti , locate its right-most appearance, say L, and output a key-value pair key = gid, value = {Ti [1] . . . Ti [L]} .这句的直接翻译和伪代码表示的意思好像对不到,按照伪代码的意思应该是:对于这样一条已转换的记录[0,2,3,5],应该输出为{[5:0,2,3,5],[3:0,2,3],[2:0,2],[0:0]}.
当所有的Mapper实例完成后,MR框架就把相同的key的values放在一起,作为reducer的输入数据value,则reducer的输入数据为(key=gid,value=DBgid);
2.4.2 FP-Growth on Group-dependent Shards
在这步中,每个reducer实例一个接着一个的读取和操作键值对(key=gid,value=DB(gid)),DB(gid)是由组分配的片。
对于每个DB(gid),和传统的FP-Growth算法一样,reducer创建本地FP-tree接着递归的创建条件子树。在这个递归的过程中,输出发现的符合条件的模式组合。和传统的FP-tree算法不同的是上面发现的模式不是直接输出,而是放入一个由支持度为索引的最大堆。所以对于每个DB(gid),reducer都会生成一个最大堆(由K个元素组成,K为最大堆的大小)。当本地的递归调用过程结束后,每个reducer输出最大堆的每个元素按照下面的形式:(key = null, value = v + supp(v));
2.5 汇总
此步读取第四步的输出,并直接把第四步的输出作为此步的Mapper输入,对于每个aj ∈ v,mapper的输出为(key = aj , value = v + supp(v) );由于MR框架的自动收集功能,所以Reducer的输入为(key = aj , value = V(aj ) ),reducer只是筛选出含有最大支持度的K个模式并输出它们;此步的算法伪代码如下:

至此,此篇论文的关于算法的部分已分析完毕。
(说明:本人只过六级,翻译难免有误,望大家不吝赐教;同时如果可能最好还是阅读原文,因为有些地方是“只可意会不可言传”)
分享,快乐,成长
转载请注明出处:http://blog.csdn.net/fansy1990