MOSES系统训练中间过程和意义详解
关于Moses训练的那些事
前面已经将moses从编译到训练测试的整体流程过了一遍,想必大家对这个工具有了一个大致的理解。这里再详细说一些东西,可能能帮助大家对moses有更深的认识。
也许你在训练过程中会遇到一定的问题,事实上,训练总共分为7个steps(步骤),有些情况下(尤其是语料非常大的时候,这个本人非常有体会,昨天训练了700万句平行语料数据,结果...)执行到某些步骤的时候会停下来,这样后续步骤无法从该步骤获得数据,整个过程就停止了。也就是说:你训练到了一半!!!这是很蛋疼的一个问题,因为从头训练意味着要大量的时间,而且你还是不能保证整个步骤是流畅的,所以本节的内容可能对你帮助很大。你可以通过它了解到如何分步进行训练,也可以在训练中断时判断目前训练进度以及下一步改进型训练的哪一个小步骤了。
1 训练过程中产生的文件和内容
言归正传,首先给大家介绍一下使用moses训练后的目录以及目录下的文件,在调用moses训练命令之后,如果训练全程都很顺利,那么在你的train文件夹下,会有四个文件夹Corpus、giza.zh-en、giza.en-zh、model,其目录下文件如下所示,在后续第2节会介绍每个文件夹中哪些文件分别是训练那个阶段获得的:

上述各目录结构内容截图如下所示:
l Train文件夹下:
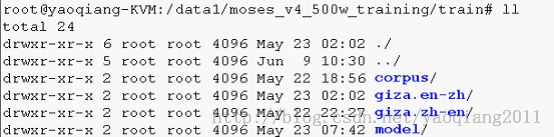
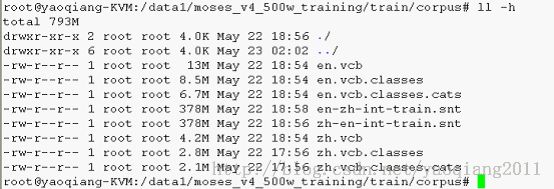
l Train/corpus文件夹下:
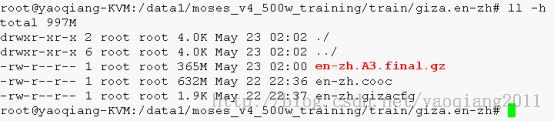
l Train/giza.en-zh文件夹下:
l Train/giza.zh-en文件夹下:

l Train/model文件夹下:

下面我们看看以上后4个文件夹下的东西的内部结构是什么样的:
Ø 首先我们看看corpus下的内容:
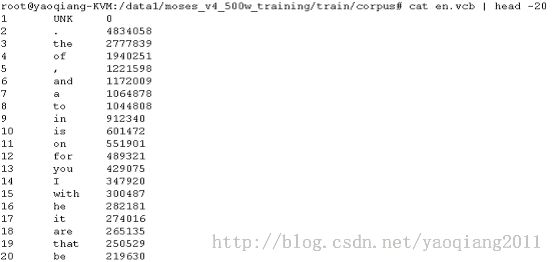


Ø 上面是corpus下的英文部分,中文部分的文件也是类似的:

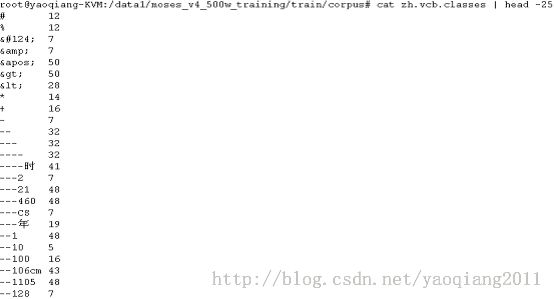

Ø 下面我们看看giza.en-zh下的文件:


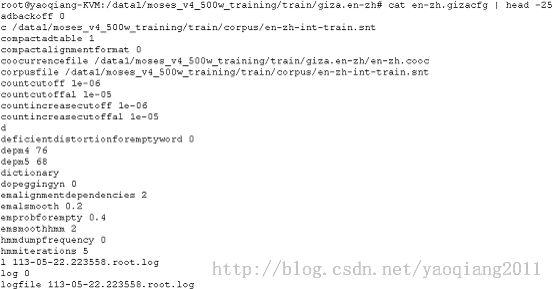
相应的giza.zh-en文件夹下是反过来相对应的对齐信息,这里就不一一截图列举了。
下面我们看看非常重要的部分,train/model文件夹下内容的内部结构(这里不一一详细说明,后续章节会提到这里文件内容中每个变量具体指代的含义):
aligned.grow-diag-final-and文件记录的是词和短语的对齐信息,如下

extract.inv.sorted.gz如下

extract.o.sorted.gz

extract.sorted.gz

lex.e2f

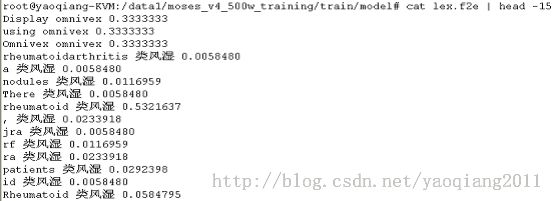
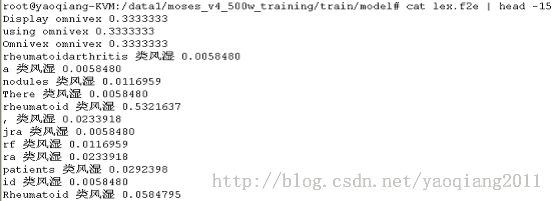
lex.f2e
moses.ini
phrase-table.gz

reordering-table.wbe-msd-bidirectional-fe.gz

2 训练过程及中间步骤
整个训练的命令如之前所述,总结下来,最基本的格式是
train-model.perl --root-dir . --f zh --e en --corpus corpus/data >& LOG
其中有一些可配置参数,这个在之后会提到。这是一条总体的训练命令,也就是说敲下这条命令之后,如果中途不出问题,训练完成之后我们就可以完整的得到上述所说的四个文件夹及全部文件。事实上,moses的训练是可以分作9个步骤的,你可以通过--first-step和--last-step任意选择你需要的训练步骤,9个步骤分别如下所示(右侧为某次训练时所花费时间):
1)Prepare data(45分钟)
2)Run GIZA++(16小时)
3)Align words(2.5小时)
4)Get lexical translation table(30分钟)
5)Extract phrases(10分钟)
6)Score phrases(1.25小时)
7)Build reordering model(1小时)
8)Build generation models
9)Create configuration file(1秒)
如果我们需要从第4步开始,则使用train-model.perl [...] --first-step 4 即可以满足我们的需求。
如果你的电脑是多核的,你可以试着加上--parallel参数,这将加快你的训练过程。
上述9个步骤中,起始步骤必须是7之前。下面我将详述以上9个步骤。
2.1 第一步:prepare data
在进行第二步之前,我们的平行语料库需要先被转换成一种适用于GIZA + +工具包的格式。这一步之后会有两个词汇文件被生成,这两个文件中定量地记录了我们的平行语料库中标点和词汇词组的个数。如下所示:
==> corpus/en.vcb <==
1 UNK 0
2 the 1085527
3 . 714984
4 , 659491
5 of 488315
6 to 481484
7 and 352900
8 in 330156
9 is 278405
10 that 262619
==> corpus/zh.vcb <==
1 UNK 0
2 我 1578046
3 他的 614454
4 你们 631793
GIZA++在处理的时候还需要我们将词划分到词类里( words to be placed into word classes)。这是通过调用mkcls程序来自动完成的。词类只在GIZA++ IBM重新排序模型中用到。词类文件格式如下所示:
> head corpus/en.vcb.classes
! 14
" 14
# 30
% 31
& 10
' 14
( 10
) 14
+ 31
, 11
2.2 第二步:运行GIZA++
GIZA++是IBM模型的一个免费实现工具。他的输入需要如第一步建立的词对齐样式。
运行GIZA++这一步是整个训练过程中最耗时的一步。它同时也需要大量的内存(如果你要训练大的平行语料,我建议你在64位系统上进行,否则3.5G的内存限制很有可能让你这一步失败,我个人训练的服务器内存是12GB的)。
GIZA++能处理获得IBM模型4的转换表,但我们只对词对齐文件感兴趣,如下所示(这是moses官网训练的德语和英语对齐的一个示例,中文和英文的对齐方式可以看我上一节列举的对应文件的截图):
> zcat giza.de-en/de-en.A3.final.gz | head -9
# Sentence pair (1) source length 4 target length 3 alignment score : 0.00643931
wiederaufnahme der sitzungsperiode
NULL ({ }) resumption ({ 1 }) of ({ }) the ({ 2 }) session ({ 3 })
# Sentence pair (2) source length 17 target length 18 alignment score : 1.74092e-26
ich erklaere die am donnerstag , den 28. maerz 1996 unterbrochene sitzungsperiode
des europaeischen parlaments fuer wiederaufgenommen .
NULL ({ 7 }) i ({ 1 }) declare ({ 2 }) resumed ({ }) the ({ 3 }) session ({ 12 })
of ({ 13 }) the ({ }) european ({ 14 }) parliament ({ 15 })
adjourned ({ 11 16 17 }) on ({ }) thursday ({ 4 5 }) , ({ 6 }) 28 ({ 8 })
march ({ 9 }) 1996 ({ 10 }) . ({ 18 })
# Sentence pair (3) source length 1 target length 1 alignment score : 0.012128
begruessung
NULL ({ }) welcome ({ 1 })
这里的例子来源于moses官网,德语和英语平行语料训练的结果,在这个文件中,一些统计信息和德语句子后,对应的英语句子是词对词与德语词对齐的,例如:第一个词resumption({1})与德国第一个字wiederaufnahme对齐。
注意每个英语单词可能是对齐的多个德语词,但每个德语词只能和一个英语单词对齐。在逆GIZA++训练过程中这个限制是相反的,即一个英语词对应多个德语词,如下:
> zcat giza.en-de/en-de.A3.final.gz | head -9
# Sentence pair (1) source length 3 target length 4 alignment score : 0.000985823
resumption of the session
NULL ({ }) wiederaufnahme ({ 1 2 }) der ({ 3 }) sitzungsperiode ({ 4 })
# Sentence pair (2) source length 18 target length 17 alignment score : 6.04498e-19
i declare resumed the session of the european parliament adjourned on thursday ,
28 march 1996 .
NULL ({ }) ich ({ 1 }) erklaere ({ 2 10 }) die ({ 4 }) am ({ 11 })
donnerstag ({ 12 }) , ({ 13 }) den ({ }) 28. ({ 14 }) maerz ({ 15 })
1996 ({ 16 }) unterbrochene ({ 3 }) sitzungsperiode ({ 5 }) des ({ 6 7 })
europaeischen ({ 8 }) parlaments ({ 9 }) fuer ({ }) wiederaufgenommen ({ })
. ({ 17 })
# Sentence pair (3) source length 1 target length 1 alignment score : 0.706027
welcome
NULL ({ }) begruessung ({ 1 })
2.3 第三步:Align Words
词对齐的过程建立基于两个GIZA++对齐步骤,可以使用一系列的探索法。其中默认的探索法是grow-diag-final(生长-诊断-结束),该过程由两个对齐的词开始,逐步添加新的对齐词直至完成句子的对齐。
其余的对齐探索方法如下所示:
Ø intersection
Ø grow (only add block-neighboring points)
Ø grow-diag (without final step)
Ø union
Ø srctotgt (only consider word-to-word alignments from the source-target GIZA++ alignment file)
Ø tgttosrc (only consider word-to-word alignments from the target-source GIZA++ alignment file)
这些方法之间可以通过--alignment参数进行选择和切换.
默认的grow-diag-final探索法的对齐过程伪代码如下所示:
GROW-DIAG-FINAL(e2f,f2e):
neighboring = ((-1,0),(0,-1),(1,0),(0,1),(-1,-1),(-1,1),(1,-1),(1,1))
alignment = intersect(e2f,f2e);
GROW-DIAG(); FINAL(e2f); FINAL(f2e);
GROW-DIAG():
iterate until no new points added
for english word e = 0 ... en
for foreign word f = 0 ... fn
if ( e aligned with f )
for each neighboring point ( e-new, f-new ):
if ( ( e-new not aligned or f-new not aligned ) and
( e-new, f-new ) in union( e2f, f2e ) )
add alignment point ( e-new, f-new )
FINAL(a):
for english word e-new = 0 ... en
for foreign word f-new = 0 ... fn
if ( ( e-new not aligned or f-new not aligned ) and
( e-new, f-new ) in alignment a )
add alignment point ( e-new, f-new )
下面的图是对齐的例子:

在上图的对齐基础上,加上了一些新的对齐词组并调整,如下图:
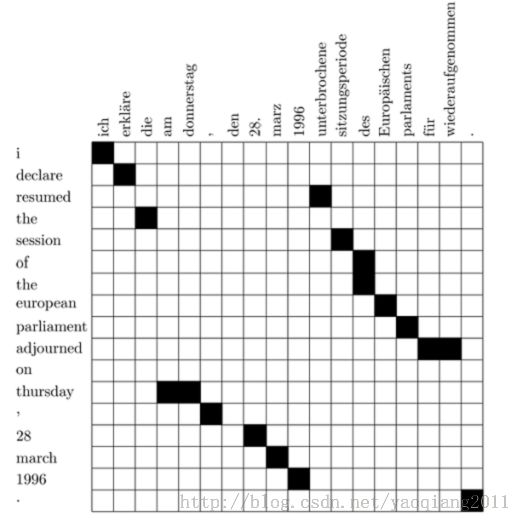
但是上图中两个动词的对齐方式混淆了,resumed和unterbrochene对齐, adjourned 和wiederaufgenommen对齐,但事实上,实际的对齐结果是相反的。
我们来看一看,词语对齐之后的结果文件,也许对本节的认识会深一些:
==> model/aligned.de <==
wiederaufnahme der sitzungsperiode
ich erklaere die am donnerstag , den 28. maerz 1996 unterbrochene sitzungsperiode
des europaeischen parlaments fuer wiederaufgenommen .
begruessung
==> model/aligned.en <==
resumption of the session
i declare resumed the session of the european parliament adjourned on
thursday , 28 march 1996 .
welcome
==> model/aligned.grow-diag-final <==
0-0 0-1 1-2 2-3
0-0 1-1 2-3 3-10 3-11 4-11 5-12 7-13 8-14 9-15 10-2 11-4 12-5 12-6 13-7
14-8 15-9 16-9 17-16
0-0
2.4 第四步:Get Lexical Translation Table(获得词汇翻译概率表)
基于上一步得到的对齐词汇表,很容易估计得到一个最大似然词汇翻译表。我们估计的W(E|F)以及逆W(F|E)字翻译表。下面为europa这个德语单词翻译成英文的最佳翻译结果:
> grep ' europa ' model/lex.f2n | sort -nrk 3 | head
europe europa 0.8874152
european europa 0.0542998
union europa 0.0047325
it europa 0.0039230
we europa 0.0021795
eu europa 0.0019304
europeans europa 0.0016190
euro-mediterranean europa 0.0011209
europa europa 0.0010586
continent europa 0.0008718
2.5 第五步:Extract Phrases(抽取短语)
在这一步中,所有的短语被扔进了一个大的文件中,文件从前那往后读的部分内容如下所示:
> head model/extract
wiederaufnahme ||| resumption ||| 0-0
wiederaufnahme der ||| resumption of the ||| 0-0 1-1 1-2
wiederaufnahme der sitzungsperiode ||| resumption of the session ||| 0-0 1-1 1-2 2-3
der ||| of the ||| 0-0 0-1
der sitzungsperiode ||| of the session ||| 0-0 0-1 1-2
sitzungsperiode ||| session ||| 0-0
ich ||| i ||| 0-0
ich erklaere ||| i declare ||| 0-0 1-1
erklaere ||| declare ||| 0-0
sitzungsperiode ||| session ||| 0-0
可以从上面看到,每一行的格式都是固定的:德语,英语,词对齐时候的点标记。点标记是一对一对的。哦,对了,还有一个逆的extract.inv也产生了,里面的内容和上述文件刚好是相反的。
2.6 第六步:Score Phrases(短语概率打分)
随后,从存储的短语翻译对中我们可以得到一张翻译表。需要有这个步骤而不是直接用翻译表替代短语翻译表,是因为较大的翻译模型中,短语翻译表在内存中存不下。幸运的是,我们不必在内存中存储整个短语翻译表,我们可以将其构建在磁盘上。
估计的短语翻译概率φ(E|F)我们的步骤如下:首先,提取文件排序。这将确保一个外国短语的所有英语短语翻译文件是在彼此旁边的。因此,我们可以处理文件中某一个词的时候,对其翻译做收集和计数,并计算φ(E|F),其中F为外国短语(源语言短语).估计φ(F|E)时,倒排文件要进行排序,φ(F|E)计算时,一个英语短语估测一次。
在得到短语翻译概率分布φ(F|E)和φ(E|F)之后,有一些其他的短语翻译打分结果可以计算,例如词汇权重,单词惩罚,短语惩罚等。目前我们在计算的时候,词汇权重是正向反向翻译概率的叠加,再加上五分之一分的短语惩罚。下面是其中文件的示例:
> grep '| in europe |' model/phrase-table | sort -nrk 7 -t\| | head
in europa ||| in europe ||| 0.829007 0.207955 0.801493 0.492402 2.718
europas ||| in europe ||| 0.0251019 0.066211 0.0342506 0.0079563 2.718
in der europaeischen union ||| in europe ||| 0.018451 0.00100126 0.0319584 0.0196869 2.718
in europa , ||| in europe ||| 0.011371 0.207955 0.207843 0.492402 2.718
europaeischen ||| in europe ||| 0.00686548 0.0754338 0.000863791 0.046128 2.718
im europaeischen ||| in europe ||| 0.00579275 0.00914601 0.0241287 0.0162482 2.718
fuer europa ||| in europe ||| 0.00493456 0.0132369 0.0372168 0.0511473 2.718
in europa zu ||| in europe ||| 0.00429092 0.207955 0.714286 0.492402 2.718
an europa ||| in europe ||| 0.00386183 0.0114416 0.352941 0.118441 2.718
der europaeischen ||| in europe ||| 0.00343274 0.00141532 0.00099583 0.000512159 2.718
在现在的moses翻译系统中,我们计算了五种不同的翻译概率,分别是:
1.inverse phrase translation probability反向短语概率φ(f|e)
2.inverse lexical weighting反向词汇权重lex(f|e)
3.direct phrase translation probability正向短语翻译概率φ(e|f)
4.direct lexical weighting正向词汇权重lex(e|f)
5.phrase penalty短语惩罚度(always exp(1)=2.718)
默认的情况下我们会使用到上述5中概率,但是也许你只想使用上述概率中的一部分,这样的话,可以通过以下的参数来作调整:
· NoLex -- do not use lexical scores (removes score 2 and 4)
· OnlyDirect -- do not use the inverse scores (removes score 1 and 2)
· NoPhraseCount -- do not use the phrase count feature (removes score 5)
这在训练的时候,在调用train-model.perl后添加-score-options调用上述参数可以做到:
train-model.perl [... other settings ...] -score-options '--NoLex'