Standford 机器学习应用的建议及机器学习系统的设计
前几讲学习了很多机器学习的算法,但是在实际的应用中会遇到很多过拟合和欠拟合的问题,这些问题都会导致测试结果不理想。用什么方法解决这些问题,是本讲研究的主题。
举一个房价预测的例子,如果学习了一个模型,发现测试结果非常不理想(有非常大的误差),那么接下去该怎么办?下面有几种解决方法:
1、 获取更多的样本,来训练模型
2、 试着用更少的特征来构建特征向量
3、 特征向量中添加其他的特征
4、 特征向量中添加已有特征的多次项
5、 增加regularization中的lambda
6、 减少regularization中的lambda
但是我们不能盲目地去选取里面的某个方法,这样会浪费不必要的时间,比如用更多的样本,数据的获得往往是非常艰难的,会花上很多时间去收集数据,也许会发现,用更多的数据没有得到更好的结果。所以出现问题后,我们要首先去诊断,到底是什么导致了很大的误差,再针对问题去采取相应的措施。
一、评估模型
把数据集分成两部分(训练数据和测试数据),往往在已有的数据集中训练数据分70%,测试数据分30%,学习的过程就是最小化训练误差,但是训练误差小,不一定测试误差就小,这就是泛化能力。我们要追求的就是使模型具有很强的泛化能力。
在逻辑回归的例子中可以这样定义测试误差:

二、模型的选择
在线性回归的例子中,我们可以选取下面的多种模型中的一个作为模型拟合出不同的曲线,定义d=degreeof polynomial,即模型的最高项多项式的系数,
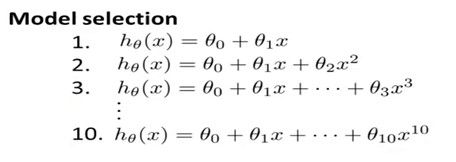
对每一个模型训练之后会学习得到10个theta向量,对每一个向量用测试集进行验证,当然也会得到不同的测试结果如下图:
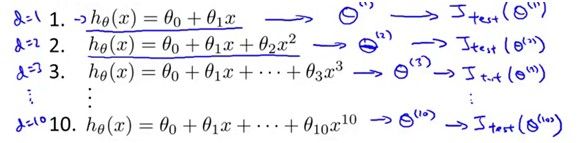
比如说d=5的时候测试误差是最小的,那么我们就认为d=5这个模型具有最强的泛化能力,为了测试这个模型预测准确率如何,就必须用新的样本(不能再用这个测试样本),因为这个模型本来就是根据这个测试样本的误差最小得到的,再用这个样本测试定会得到很小的误差,但是对其他数据性能如何我们不得而知。
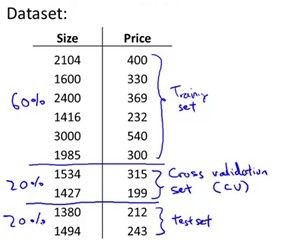
因此需要将数据分成三部分:训练数据,交叉验证数据,测试数据。训练数据用来学习模型,交叉验证数据来验证不同的模型的交叉验证误差,选择交叉验证误差最小的那个模型。然后用测试数据来验证模型预测的准确率(这里的测试数据不要和上面的测试数据搞混了,上面的测试数据其实就是交叉验证数据)。这三部分数据划分如下:分别占60%,20%,20%。
线性回归中,他们的误差定义如下:

三、诊断bias和variance
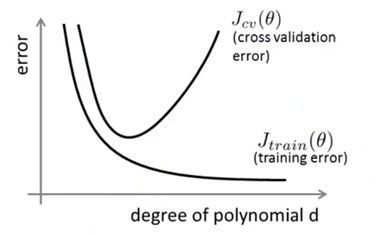
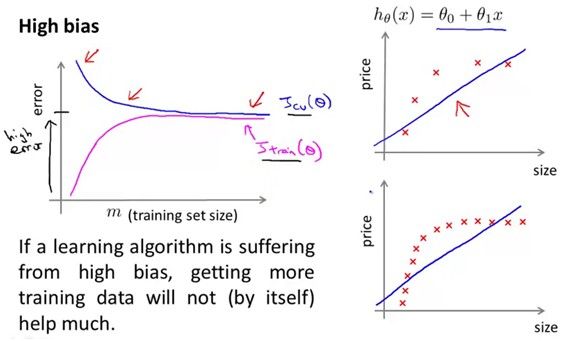
模型欠拟合就是会有很高的bias,如果过拟合就有很高的variance,如下图:

随着d的增加,训练误差会越来越小,因为多次项次数越高,拟合的越精确,训练数据上的误差当然越小。对于测试误差,d小的时候是欠拟合,误差当然大,中间慢慢减小,超过一定程度后就变成了过拟合,误差当然也就增大。误差变化如下:
解决过拟合的方法就是regularization,regularization有没有好的效果关键是lambda的选取,lambda过小会过拟合,lambda过大会欠拟合。
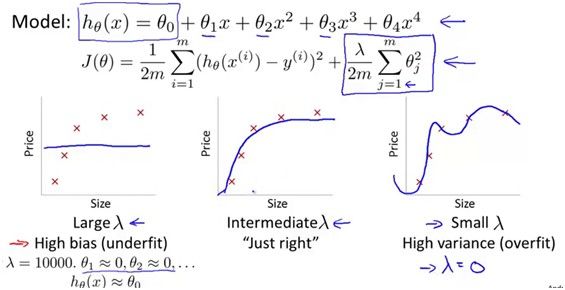
那么应该怎么样选取这个lambda值呢?当然是选测试误差最小时候的lambda!如下图所示,根据不同的lambda学习出来的模型,在交叉验证数据集上得到了相应的误差,选取交叉验证误差最小的那个lambda就行了。
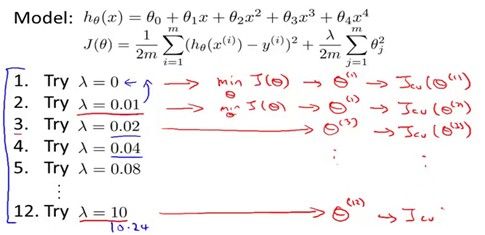
那么随着lambda增大,训练误差和测试误差又是怎么样变化的呢?对于训练误差,lambda很小的时候,是过拟合,当然训练误差很小,随着lambda的增大,越来越不能精确的拟合训练数据,所以训练误差不断增加,直到欠拟合。对于测试误差,lambda小的时候是过拟合,测试误差很大,lambda到中间某个值的时候误差到最小,lambda很大的时候是欠拟合,测试误差又变大。但往往测试误差比训练误差要大,因为模型是根据训练数据学习出来的。变化关系如下图。
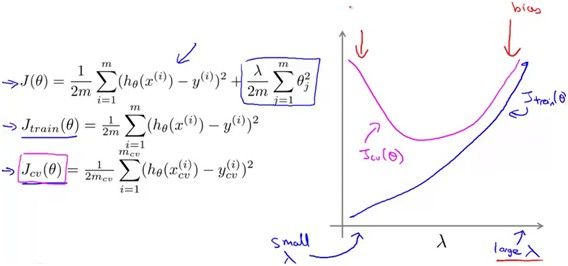
四、学习曲线
这条曲线是关于测试误差和训练样本个数关系的。如果训练样本很少,如下图右边上面的例子,模型会很容易的拟合所有样本,训练误差小,随着样本个数增多,模型越难越拟合所有的样本,因此训练误差逐渐升高。对于测试误差,样本个数少训练出来的模型当然不具有代表性,测试误差小,样本数增多测试误差会逐渐减小。最后无论是测试误差还是训练误差都会收敛到一个阈值。

看下面这个例子,样本数很多的时候,训练误差和测试误差都很大,这个模型是欠拟合,于是增加样本不能对测试误差有一个很好的改进,
如果模型是过拟合的,增多样本会降低过拟合的程度,试想,如果样本无限多,这样拟合出来的模型是否就是一个精确的模型呢?所以highvariance的时候,增加样本的数量是有帮助的。样本越多可以得到越精确的模型。微博上看到google翻译之所以比别的翻译做的好,是因为它有海量数据的支撑,这些数据使得它比其他公司准确率搞了5个百分点,而提高一个百分点,需要1年的研究。Google的数据帮助google赢得了5年的时间。
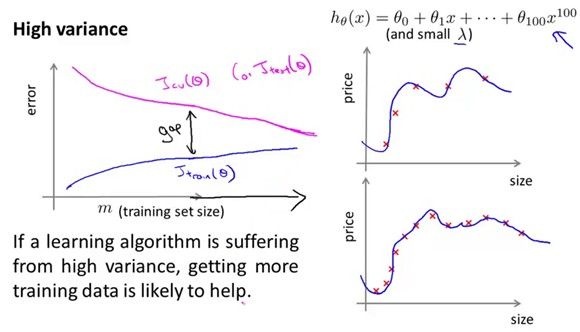
回到刚才的例子,对应的方法可以解决什么样的问题呢?

用复杂的模型,比如有很高次项数的模型或者神经网络,往往会趋向于过拟合,但是可以用regularization来防止过拟合,增加训练样本的方法也可以得出非常令人满意的模型。
五、误差的度量
在肿瘤预测的例子中,假设只有0.5%的人得了肿瘤,那么我的模型一直预测y=1的话,也测得所有肿瘤的样本,这样明显不太合理。
现在让y=1定义为我们想要检测的rare class(这个非常重要)。
定义precison=预测为正类的正类样本数/(预测为正类的样本数)
Recall = 预测为正类的正类样本数/实际为正类的样本数
如下图:
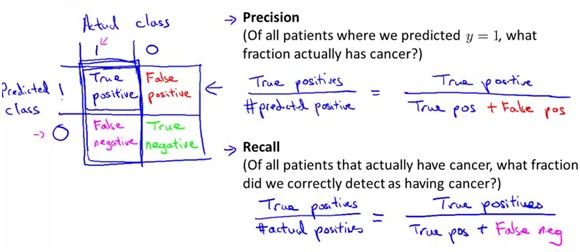
根据上面这个例子,设得没得肿瘤为正类,那么precision=0.5% recall=100%,用precision和recall两个量可以衡量模型的好坏,precision和recall都很高才是好的模型。
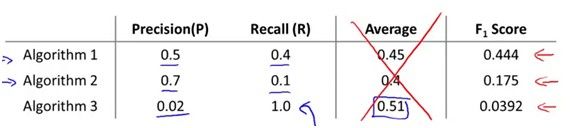
有上面三个模型的准确率和召回值,如何选择哪个模型最好呢?明显用平均值的方法会选到第三个,然而第三个模型是不理想的。常用的定义方法是F1score,F1score定义为2PR/(P+R),所以根据这个值,上面算法1是最理想的模型。
总结:在应用当中,遇到测试误差很大的时候,要学会去分析,通过话LearningCurve可以看出是过拟合的问题还是欠拟合的问题,然后在对症下药,该增加样本增加样本,该调整lambda调整lambda,该改变feature改变feature。