MOSES翻译系统的训练,调优和使用
这里我假设你已经成功安装了摩西moses,并希望在平行语料数据的基础上建立一个真正的短语翻译系统。这个过程需要一定的Unix的基础,理想情况下,最好还有一台Linux服务器。当然,如果你只是想试试的话,你也可以在一台笔记本电脑上安装并运行它,但最少要2G的内存(貌似现在的电脑都至少有这么大吧),和10G的空闲磁盘空间(声明一下,这是本人估计的,有可能配置达不到这个也能跑,但训练的速度会非常慢的)。
在进行下述操作之前,我建议你将编译后生成的moses可执行文件和之前编译安装过后的Irstlm以Giza++工具整理到一个文件夹下,便于调用,本人大致的目录结构如下:

1 语料库准备和预处理
这个地方,本人使用的是射手网和各种字幕网站采集和清洗过的英文电影电视剧字幕的中英平行语料。你要是只是想试一试moses而又没有语料的话,可以wget http://www.statmt.org/wmt12/training-parallel.tgz进行下载,这里面是欧洲各国语言(德语,英语,法语等)的平行语料库,你可以用作测试。
在进行语料训练之前,要先对我们的平行语料做一些预处理,主要包括以下以下步骤:
tokenisation:这一步主要是在单词和单词之间或者单词和标点之间插入空白,以便于后续识别和其他操作。
truecasing:初始每句话的字和词组都被转换为没有格式的形式(例如统一为小写)。这有助于减少数据稀疏性问题。
cleaning:长句和空语句可引起训练过程中的问题,因此将其删除,同时删除显不对齐句子删除。
对了,对于平行语料的中文部分的话,在训练之前一定要注意要先分好词,这样后面使用giza-pp进行对齐训练的时候才能精准对齐词、词组和短语。我使用的是中科院ictclas分词系统,但是又licence过期的可能,你也可以使用Ansj,基本是将ictlas用java重写了一遍,词库基本不变,分词的程序我可以在之后的文章里给出。
我的语料存在/data/traing_500m_data/中,则执行以下指令即可:
tokenisation:
/home/yaoqiang/moses/moses_binary/scripts/tokenizer/tokenizer.perl -\l en ‐threads 8 < all_movie_data_20130422_en > all_movie_data_20130422.tok.en
/home/yaoqiang/moses/moses_binary/scripts/tokenizer/tokenizer.perl -\l zh ‐threads 8 < all_movie_data_20130422_zh > all_movie_data_20130422.tok.zh
Truecaser和truecasing:
/home/yaoqiang/moses/moses_binary/scripts/recaser/train-truecaser.perl --model truecase-model.en --corpus \
all_movie_data_20130422.tok.en
/home/yaoqiang/moses/moses_binary/scripts/recaser/train-truecaser.perl --model truecase-model.zh --corpus \
all_movie_data_20130422.tok.zh
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\model.en < all_movie_data_20130422.tok.en \
> all_movie_data_20130422.true.en
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\
model.zh < all_movie_data_20130422.tok.zh \
> all_movie_data_20130422.true.zh
cleaning:
/home/yaoqiang/moses/moses_binary/scripts/training/clean-corpus-n.perl all_movie_data_20130422.true zh en \
all_movie_data_20130422.clean 1 80
2 语言模型训练
首先,我前面预处理过的语料已经存储在/data/train_500m_data/文件夹下了。
再说一下,这里要训练生成的语言模型(LM)是用来确保最后翻译后流畅的输出的,所以它是关于目标语言(这里是中翻英,即英语)的。Irstlm的文献给出很多命令行选项的详细说明,但以下的指令足以建立一个合适的3-gram语言模型,消除singletons,并使用改进的Kneser-Ney方法进行平滑了,且添加句子边界符号:
/home/yaoqiang/moses/moses_binary/training-tools/irstlm/bin/add-start-\ end.sh < all_movie_data_20130422.true.en > all_movie_data_20130422.sb.en
export IRSTLM=$HOME/irstlm; /home/yaoqiang/moses/moses_binary/training-tools/irstlm/bin/build-lm.sh -\ i all_movie_data_20130422.sb.en -t ./tmp -p -s improved-kneser-ney -o all_movie_data_20130422.lm.en
/home/yaoqiang/moses/moses_binary/training-tools/irstlm/bin/compile-lm --\ text yes all_movie_data_20130422.lm.en.gz all_movie_data_20130422.arpa.en
经过这一步之后我们会得到一个*.arpa.en格式的语言模型文件,接下来我们将会使用KenLM对其进行二值化(这样的话载入的时间会更快)。
这一步的指令如下:
/home/yaoqiang/moses/moses_binary/bin/build_binary all_movie_data_20130422.arpa.en all_movie_data_20130422\.blm.en
我们可以在这一步之后测试一下训练的模型是否正确,运用如下的linux命令:
echo "is this an English sentence ?" | /home/yaoqiang/moses/moses_binary/bin/query all_movie_data_20130422.blm.en
我的测试结果如下,表明生产模型成功:
root@yaoqiang-KVM:/data/train_500m_data# echo "is this an English sentence ?" | /home/yaoqiang/moses/moses_binary/bin/query all_movie_data_20130422.blm.en
Loading statistics:
user 0
sys 0.040002
VmPeak: 217224 kB
VmRSS: 215600 kB
is=28 2 -2.221 this=140 3 -1.03372 an=451 3 -2.22049 English=7517 2 -3.12162 sentence=8256 2 -3.97998 ?=60 2 -1.19407 </s>=16 3 -0.0103952 Total: -13.7813 OOV: 0
After queries:
user 0
sys 0.040002
VmPeak: 217232 kB
VmRSS: 215600 kB
Total time including destruction:
user 0
sys 0.052003
VmPeak: 217232 kB
VmRSS: 656 kB
3 翻译模型训练
经过上述这一系列过程之后,我们可以开始训练我们的翻译模型了。接下来这一条linux命令,将完成包括词对齐(使用GIZA++),短语提取和评分,创建词汇化的重新排序表以及创建你的moses的配置文件(moses.ini)等一系列任务。我建议你建立适当的目录结构,然后运行训练命令,我的目录结构如下指令中所述。记得最后将训练过程记录在日志中:
mkdir /data/translating_working
cd /data/translating_working
nohup nice /home/yaoqiang/moses/moses_binary/scripts/training/train-model.perl -cores 8 -root-dir train -\ corpus /data/train_500m_data/all_movie_data_20130422.clean -f zh -e en -alignment grow-diag-final-and -\reordering msd- bidirectional-fe -lm 0:3:/data/train_500m_data/all_movie_data_20130422.blm.en:8 -external-bin-\ dir /home/yaoqiang/moses/moses_binary/training-tools/giza >& training_log.out &
其中参数-cores 8将服务器中8个cpu全都用上了。
这一步的时间稍长,主要是前期giza-pp对词和短语对齐训练耗时,比如说我这里训练的语料大概是中英文各300m左右,训练完成的时间大概是36个小时,我这里使用的是12G内存8核cpu的服务器,所以如果你急着看到训练结果的话,加载的语料库要稍小一些,上次加载的语料库大概是100万句子(30m左右),训练了将近4个小时。
上述过程完成后,你可以在translating_working/train/model 文件夹下找到一个moses.ini配置文件,这是需要在moses解码时使用到的。但这里有几个问题,首先是它的加载速度很慢,这个问题我们可以通过二值化(binarising)短语表和排序表来解决,即编译成一个可以很快地加载的格式。第二个问题是,该配置文件中moses解码系统用来权衡不同的模型之间重要程度的权重信息都是刚初始化的,即非最优的,如果你打开moses.ini文件看看的话,你会看到各种权重都被设置为默认值,如0.2,0.3等。要寻找更好的权重,我们需要调整(tuning)翻译系统,即下一步。
4 调整(tuning)翻译模型
这是所有步骤中过程进行的最慢的一部分,所以你大可在这一步进行的时候,放张椅子,躺下来吃点东西读点莫言的小说啥的。调整(tuning)过程需要一份不同于训练数据的小平行语料,这个的话又要靠你自己收集了(如果你训练的时候用的是上面提供的欧洲平行语料的话,在相同的网址你还可以下到一些用于tuning的数据),另外一个简单的处理方法就是在训练的时候只用全部平行语料的一大部分,例如95%,而剩下的5%用于调优这一步。以下是用于调整的语料准备的过程(同样需要先将数据进行tokenlizer、truecase和长度限定等处理):
/home/yaoqiang/moses/moses_binary/scripts/tokenizer/tokenizer.perl -l en < dev/rwx.web.en > test.tok.en
/home/yaoqiang/moses/moses_binary/scripts/tokenizer/tokenizer.perl -l zh < dev/rwx.web.zh > test.tok.zh
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\model.en < test.tok.en > test.true.en
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\model.zh < test.tok.zh > test.true.zh
/home/yaoqiang/moses/moses_binary/scripts/tokenizer/tokenizer.perl -\l en < tuning_data_20130422_en > tuning_data_20130422.tok.en
/home/yaoqiang/moses/moses_binary/tokenizer/tokenizer.perl -\l zh < tuning_data_20130422_zh > tuning_data_20130422.tok.zh
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\model.en < tuning_data_20130422.tok.en > tuning_data_20130422.true.en
/home/yaoqiang/moses/moses_binary/scripts/recaser/truecase.perl --model truecase-\model.zh < tuning_data_20130422.tok.zh > tuning_data_20130422.true.zh
接下来我们可以开始tuning我们moses解码器配置文件中的权重了:
nohup nice /home/yaoqiang/moses/moses_binary/scripts/training/mert-\moses.pl ../corpus/test.true.zh ../corpus/test.true.en \ /home/yaoqiang/moses/moses_binary/bin/moses train/model/moses.ini --mertdir ../moses_binary/bin/ &> mert.out &
可在最后加上--decoder-flags="-threads 8"以使用多个线程,因为这个过程非常非常缓慢,你当然要使用能使用上的所有资源。
5 测试系统
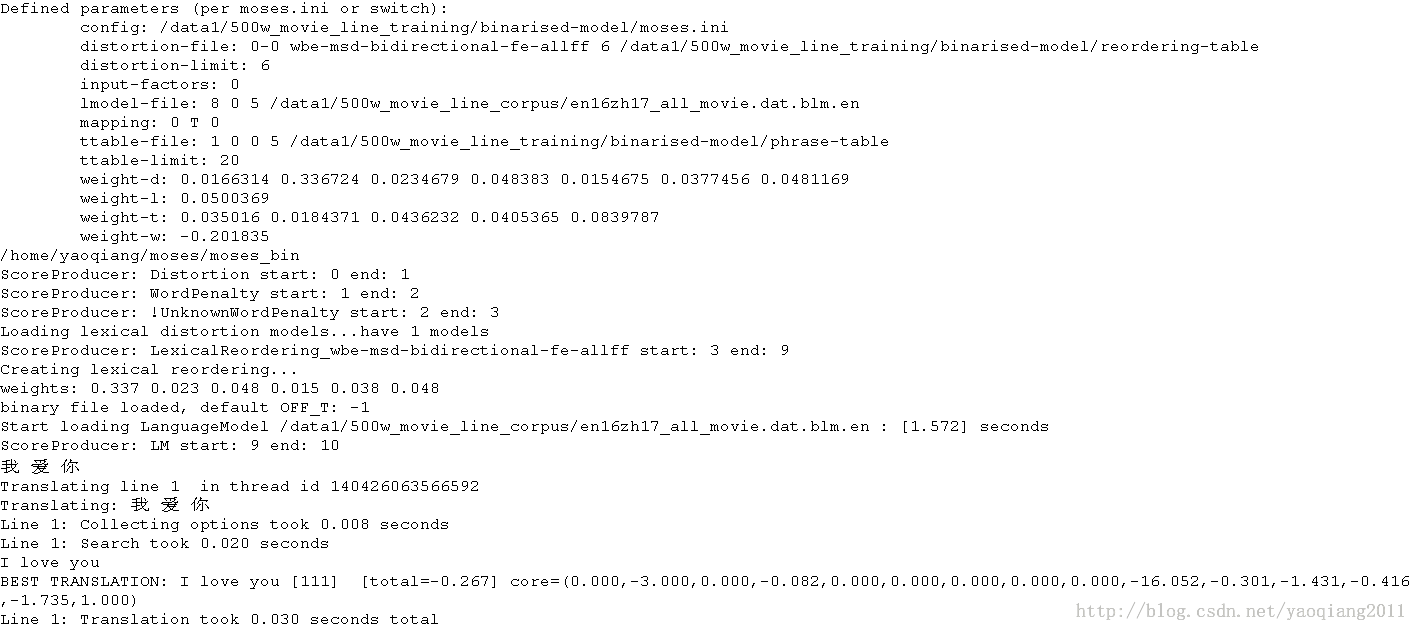
你现在就可以通过/home/yaoqiang/moses/moses_binary/bin/moses -f /data/train_500m_data/translating_working/mert-work/moses.ini来运行moses了,你可以输入你最喜欢的中文句子(分好词的),moses将会将其翻译成为对应的英文句子。
哦,对了,如果你想让运行的速度加快的话,你可能还需要稍微修改下/data/train_500m_data/translating_working/mert-work/文件夹下的moses.ini文件。将其中的语言模型和reordering表载入地址换做二值化后的语言模型和reordering表,如下:
0 0 0 5 /data/train_500m_data/translating_working/train/model/phrase-table.gz
变成
1 0 0 5 /data/train_500m_data/translating_working/binarised-model/phrase-table
0-0 wbe-msd-bidirectional-fe-allff 6 /data/train_500m_data/translating_working/train/model/reordering-table.wbe-msd-bidirectional-fe.gz
变成
0-0 wbe-msd-bidirectional-fe-allff 6 /data/train_500m_data/translating_working/binarised-model/reordering-table
至此为止,moses从编译到训练语言模型到训练翻译模型,再到配置文件中权重的调整和最后的测试都已讲完了,有兴趣的话你可以自己下载相关代码和平行语料测试一下!
下面是运行moses后的一个小结果,大家可以看看: