稀疏编码(Sparse Coding)的前世今生(三)
稀疏编码(sparse coding)和低秩矩阵(low rank)的区别
上两个小结介绍了稀疏编码的生命科学解释,也给出一些稀疏编码模型的原型(比如LASSO),稀疏编码之前的探讨文章就不说了,今天开始进入机器学习领域的稀疏表达。稀疏编码进入机器学习领域后,出现了很多应用,比如计算视觉领域的图像去噪,去模糊,物体检测,目标识别和互联网领域的推荐系统(Collaborative filtering)用到的low rank,其实sparsecoding和low rank有点区别,前者是稀疏系数,后者是稀疏基。就统称他们为稀疏表达吧。接下来简单的阐述下sparse coding和low rank的区别:
Sparsecoding就是围绕着![]() 开展工作,比如找到稀疏字典D和稀疏系数 alpha,如果X是人脸图像,训练的目标就是为了找到合适的字典基和一些系数的线性组合可以重建人脸X,假设训练样本有K类(即为K个人),每类有N个样本,那么D可表达为:
开展工作,比如找到稀疏字典D和稀疏系数 alpha,如果X是人脸图像,训练的目标就是为了找到合适的字典基和一些系数的线性组合可以重建人脸X,假设训练样本有K类(即为K个人),每类有N个样本,那么D可表达为:
![]() ,其中下标i表示第i类。
,其中下标i表示第i类。
![]()
不过还是要强调一下d表示一张图像向量,假设维度为m。这样某个样本可以表示为:
![]() ,其中
,其中![]()
,这下终于和sparse coding扯上关系咯,alpha是稀疏的,好多0啊![]() 。如果假设图像还有一些噪声,那么再扩展一下,可以继续表示为:
。如果假设图像还有一些噪声,那么再扩展一下,可以继续表示为:
![]()
到此位置机器学习的sparse coding模型基本就搭建好了,接着要做的就是对它求解,不得不说的是公式中都是未知数,看上去解很多,不过还有一个约束没用上,就是让alpha和e的非零个数尽可能的少,稀疏嘛,因此最终建立模型(公式一)所示:
![]()
(公式一)
对其优化求解就行了,常用的方法有coordinate descent和Orthogonal Matching Pursuit(OMP)方法,求解的alpha和e是稀疏的,但是求解方法主要看优化,各种优化算法层出不穷,这个话题就打住吧。
现在来看下low rank,先来看一个经典问题,如(图一)所示:
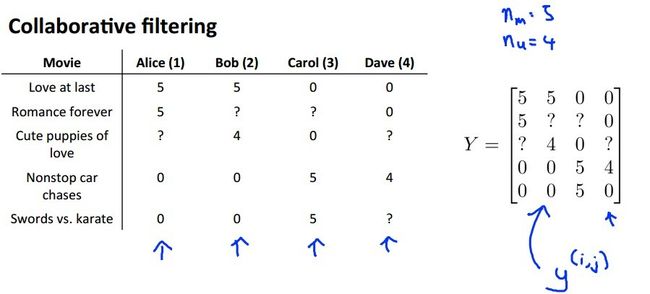
(图一)
(图一)是stanford人工智能教授andrew ng的课件截图,说的是四个人对不同电影打分,其中Alice和Bob偏向于喜欢看言情的浪漫电影,而Carol和Dave偏向于动作片和武侠片,可以推测出Alice和Bob是女的吧,而Carol和Dave则可能是男的。矩阵Y中也可以大概的看出这种规律,矩阵前两行数据(男同学打的分)很相似,可以把他们看成同一个轴,而下面两行看成另外一个轴,这两个轴构成了打分空间,因此轴就是基,类似于稀疏编码的字典。但是基是稀疏的,而系数不是稀疏的。其实现实中有很多类似的数据,比如你把对齐的同一个人脸数据按照这样的矩阵排放,同样是类似规律。同学们可能在找系数在哪,系数如(图二)所示:

(图二)
优化求解模型如(公式二)所示:

(公式二)
没错,和上面一样,又要求X又要求theta,求解方法仍然可以采用coordinate descent,但也有其他求解方法,其他方法主要从凸优化的角度来考虑,数学界的新星陶哲轩证明了在RIP条件下L0范数(就是计算元素数的)优化和L1范数优化具有相同的解,然后L1范数是个凸优化问题,顺便松弛到trace norm来求解,背后有很多数学证明,今天就说到这了,优化求解方法以后慢慢来触及吧。
对于稀疏表示的应用可以看看一篇名为“稀疏表达”的上中下博文
转载请注明链接:http://blog.csdn.net/cuoqu/article/details/9040731