HTK工具搭建识别器的总体框架
老早之前就学习了HTK工具,并用于搭建连续语音识别器,但是好久没有用对于一些东西又忘记了,现在由于做实验需要用到HTK,又重新看了一遍,所以把一些大致的东西记录下来,以后可以直接看这个。感觉用HTK搭建识别器,学习一门脚本语言非常重要,如Perl,和Shell..........
Hinit:用于对HMM模型的参数进行初始化。
HRest: 用Baum-Welch算法对HMM参数进行估计,可以用许多训练样本构造HMM模型参数,通常和Hinit一起使用。
识别工具:
在HTK中没有哪个工具直接实现了Viterbi算法,但是HVite工具中实现了该算法,
HVite用于孤立词识别,HNET和HRec用于连续语音识别,如果该识别器有语法图,也可以作为一个特例用于孤立词语音识别。
连续语音识别:
对于连续语音识别,需要找出每个连续语音的子词,可以用Hinit和HREst来初始化子词模型(bootstrap operation)。主要用于训练的工具是HERest,主要用于嵌入式训练(Embeddedtraining).嵌入式训练和用Baum-Welch训练孤立词模型的过程相似,不同的是它所有的模型一起训练,而不是一个一个模型的训练。在这个过程中不需要训练语音的分界信息,但是需要训练语音的对应的符号标记。
在HTK中的连续语音识别,用token passing algorithm取代Viterbi算法进行识别。该算法在库模块HNET和HRec中实现了,可以通过识别工具HVite调用。它能提供multiple-tokenpassing recognition, single-best output, lattice output, N-best lists, supportfor cross-word context-dependency, lattice rescoring and forced alignment.
说话人自适应
用工具HERest 和 HVite能进行说话自适应,它需要提供一定的自适应数据。HERest提供线下的有监督的自适应。而HVite提供在线的自适应(用HVite识别该词,再利用产生的符号标记进行调整HMM参数)。HERest的有监督自适应具有更强的鲁棒性。
HTK工具简介:
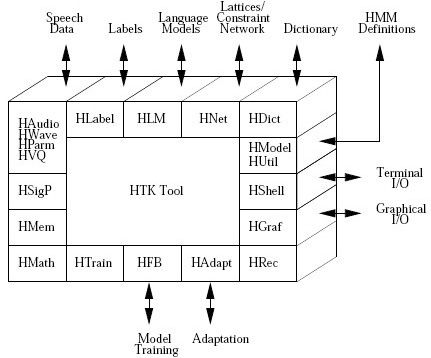
HSHELL:用于输入/输出控制。HMEM库用于内存管理。HMath:数学计算库
HSigp:语音分析中用到的信号处理库。
HLabel用于标记文件。HLM:用于语言模型。HNet:用于词网络和网格
HDict:用于词典。HVQ :VQ算法。 HModel:用于HMM模型的定义。
所有的语音文件通过HWave进行处理,用HParm进行参数化。HWave和HLabel对多种语音文件格式提供支持。HAudio用于实时语音输入,HGraf提供图形界面接口。HUtil provides a number of utility routines formanipulating HMMs while HTrain and HFB contain support for the various HTKtraining tools. HAdapt provides support for the various HTK adaptation tools.Finally, HRec contains the main recognition processing functions.
工具使用方法:
命令行参数形式:
HFoo -T 1 -f 34.3 -a -s myfile file1 file2
该工具主要包含两个主要的参数,file1和file2.加上四个可选参数。可选参数通常用小写字母表示,后面跟一个具体的数值,-f表示一个实数,-T表示一个整数,用于控制HTK工具的输出信息,-s表示一个字符串,-a后面没有数值,表示对工具的某些特性的屏蔽。
配置参数:
HFoo -C config -f 34.3-a -s myfile file1 file2
多个配置文件:HFoo -Cconfig1 -C config2 -f 34.3 -a -s myfile file1 file2
HTK语音识别过程
数据准备,训练,测试,分析结果
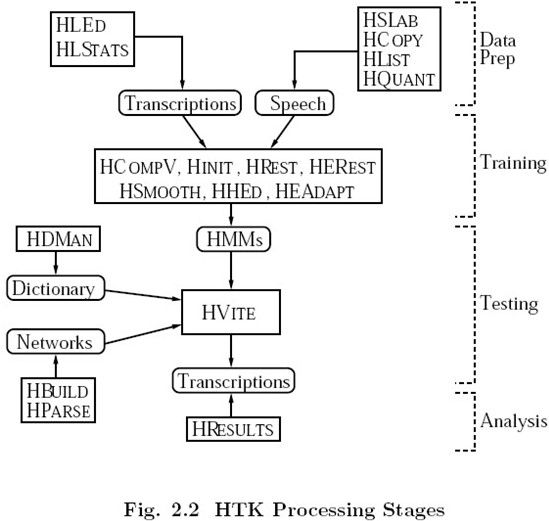
数据准备工具:
HSLab:用于语音的录制。
HCopy:用于特征提取,将原语音文件Copy为参数文件。
HList:用于检查提取的特征参数。
Transcriptions(标注)也需要提取准备,label在训练语音中可以不需要,HMM训练是一个上下文相关的一个过程,它需要标注信息,HLEd是用于将标签转换为HTK固有的标签格式。HLED可以输出单个的MLF Master Label File文件。
HLStats:用于收集和显示Label文件信息。
HQuant:用于建立VQ码本,用于离散HMM模型。
模型训练工具:
HTK的训练过程:
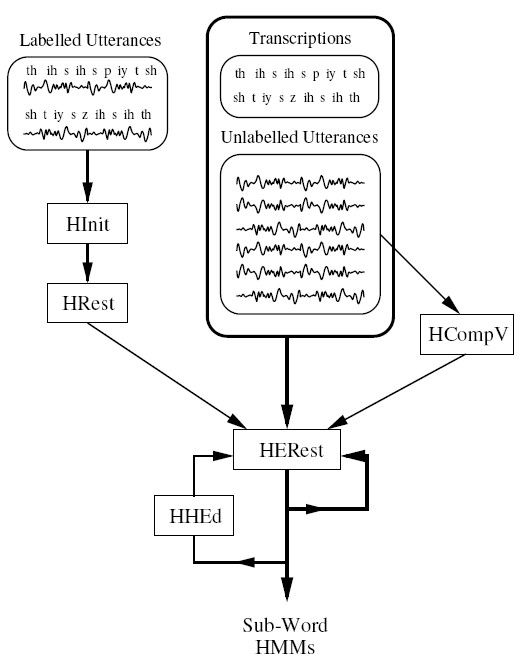
1.需要先定义HMM原型,HMM模型的定义,均值和方差可以任意给定,但是转移概率矩阵要给出,后面 面的训练过程对这个不敏感,主要用于确定HMM的结构。转移概率需要给出合理的值(可以设置所有的转移概率相等),但是这样不影响后面的训练过程。
2. 模型参数初始化(HInit and HRest)If there issome speech data available for which the location of the sub-word (i.e. phone)boundaries have been marked, then this can be used asbootstrap data. In this case, the tools HInit and HRest provideisolated wordstyle training using the fully labelled bootstrap data. Eachof the required HMMs is generated individually(用HINIT工具中的分段K均值算法进行参数的初始化). On the second and successive cycles, the uniformsegmentation is replaced by Viterbi alignment. The initial parameter valuescomputed by HInit are then further re-estimatedby HRest.
When no bootstrap data is available, a so-called flatstart can be used. In this case allof the phone models are initialized to be identical and have state means andvariances equal to the global speech mean and variance (用HCompV工具计算全局的均值和方差)。
3.通过第二步已经创建了初始的HMM模型,用HERest工具对所有的训练集进行嵌入式训练。HERest performs a single Baum-Welch re-estimation of the wholeset of HMM phone models simultaneously. For each training utterance, thecorresponding phone models are concatenated and then the forward-backwardalgorithm is used to accumulate the statistics of state occupation, means,variances, etc., for each HMM in the sequence. When all of the training datahas been processed, the accumulated statistics are used to compute re-estimates of the HMMparameters. HERest工具是HTK的核心训练工具,可以用于处理大型数据库。
HHED是HMM模型定义的编辑工具,可以通过参数绑定或者增加混合高斯函来克隆上下文有关的HMM模型,然后进行参数的重估。re-estimate the parameters of the modified set using HERestafter each stage.为了提高特定说话人的识别率,可以用HERest和HVite进行说话人的自适应。
建立上下文相关的HMM系统最大的问题就是训练数据的不足,所以需要找一个平衡点。The more complex the model set, the more data is neededto make robust estimates of its parameters, and since data is usually limited,a balance must be struck between complexity and the available data. 在连续HMM模型中,通常通过参数绑定来解决训练数据的不足。HSmooth:用于HMM模型高斯分布的平滑。
识别工具:
HVite:可以利用语言模型和词网格进行语音识别。
HVite takes as input anetwork describing the allowable word sequences, a dictionary defining how eachword is pronounced and a set of HMMs. Recognition can then be performed on either a list ofstored speech files or on direct audio input.
词网络是一个有向图,代表语音识别系统的任务语法。词网络用标准的HTK文件格式保存。HTK提供两个工具来创建词网络。HBUild,HPARSE:将文法转换成词网络。
词网络就是语法规则,限定哪些语句是合法的。
有了词网络就可以生成符合词网络的句子了。用HGEN工具实现,输入为词网络,输出为一些词的句子。
HLRecsore:可以让HVIte和HDEcode生成词网格,用于更复杂的语言模型。
HDMAN:词典管理工具。
分析工具:
HRESULTS:HResults which uses dynamic programming to align the twotranscriptions and then count substitution, deletion and insertion errors. HResults canalso provide speaker-by-speaker breakdowns, confusion matrices and time-alignedtranscriptions.
For word spottingapplications, it can also compute Figure of Merit (FOM) scores and Receiver OperatingCurve (ROC) information.