基于Solr的LBS(地理位置搜索)实现原理
基于Solr的空间搜索学习笔记
在Solr中基于空间地址查询主要围绕2个概念实现:
(1) Cartesian Tiers 笛卡尔层
Cartesian Tiers是通过将一个平面地图的根据设定的层次数,将每层的分解成若干个网格,如下图所示:
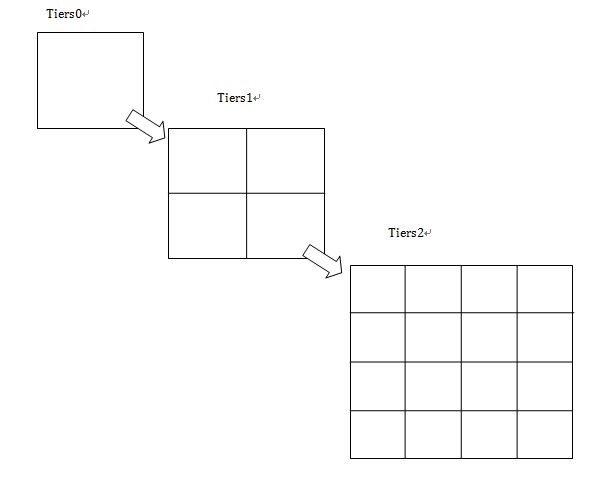
每层以2的评方递增,所以第一层为4个网格,第二层为16 个,所以整个地图的经纬度将在每层的网格中体现:

笛卡尔层在Lucene中对空间地理位置查询最大的用处在查找周边地址的时候有效的减少查询量,即将查询量可以控制在分层后最小的网格中的若干docId。
那么如何构建这样的索引结构呢,其实很简单,只需要对应笛卡尔层的层数来构建域即可。
也即是tiers0->field_0,tiers1->field_1,tiers2-field_2,……,tiers19->field_19。(一般20层即可)。每个对应笛卡尔层次的域将根据当前这条记录的经纬度通过笛卡尔算法计算出归属于当前层的网格,然后将gridId(网格唯一标示)以term的方式存入索引。这样每条记录关于笛卡尔0-19的域将都会有一个gridId对应起来。但是查询的时候一般是需要查周边的地址,那么可能周边的范围超过一个网格的范围,那么实际操作过程是根据经纬度和一个距离确定出需要涉及查询的从19-0(从高往低查,留给读者思考)若干层对应的若干网格的数据(关于代码实现在后面的文章内容阐述)。那么一个经纬度周边地址的查询只需要如下图圆圈内的数据:
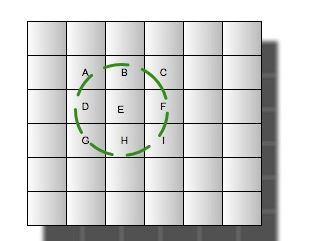
所以通过这样的数据过滤,将极大的减少计算量。
(2) GeoHash算法
在Lucene索引中将经纬度的二维坐标通过geohash,变成一个一维的字符串base32的坐标,例如,经纬度对应一个base32的坐标为DRT2Y,那这个base32的字符串什么意思呢,
其实编码中每个字符都是代表一个区域,并且前面的字符是后面字符的父区域,即R是D区域内的子区域,T又为D区域的子区域,大家可以从如下图片获得base32的层级关系(以下图片均来自互联网):
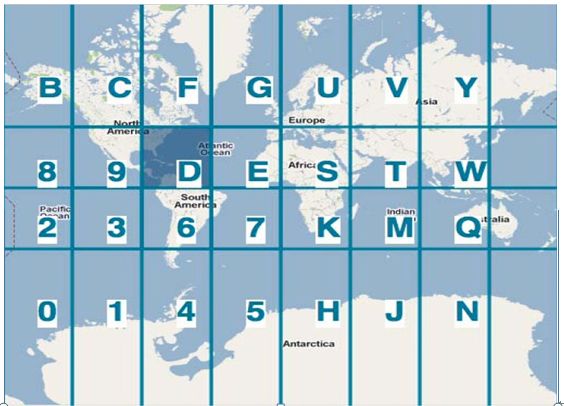
进入D区域,则看到又分为若干区域,而R为其子区域:
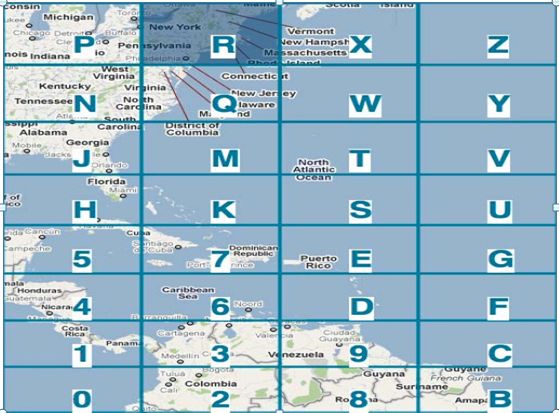
继续进入R区域,可以继续看到有子区域T区域:
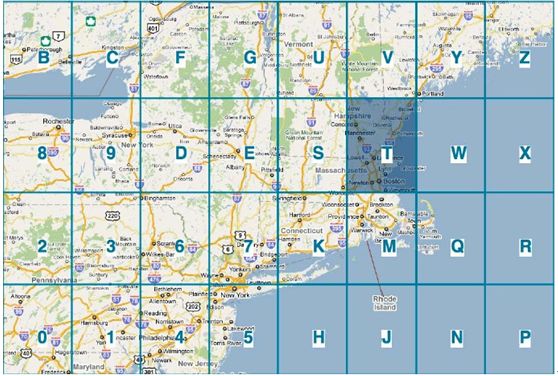
而2Y也是基于以上的关系类推,所以一个base32的编码是标示一个区域,而编码过程中会根据经纬度的精度来确定这个区域大小。从上面的解释大家肯定会想到编码的前缀是表示更大的区域。例如wx4g0ec1,它的前缀wx4g0e表示包含编码wx4g0ec1在内的更大区域。所以根据这个特点,利用模糊查询是可以达到一种附近地点的查询。
geohash算法实现其实非常简单,网上有很多例子,在这里借用下这些例子再加上比较详细的说明。基本算法流程是基于多轮的收敛,以达到满足精度要求为止。具体流程以(39.92324 纬度, 116.3906 经度)为例,首先将纬度的范围(-90, 90)平分成两个区间(-90, 0)、(0, 90),如果目标纬度位在(-90,0),则编码为0,在(0,90)则编码为1。由于上面的例子中维度39.92324是属于(0, 90),所以第一轮获得的编码位取1。接下来再将(0, 90)分成 (0, 45), (45, 90)两个区间,而39.92324位于(0, 45),所以编码为0。以此类推,直到精度符合要求为止,如下图所示:
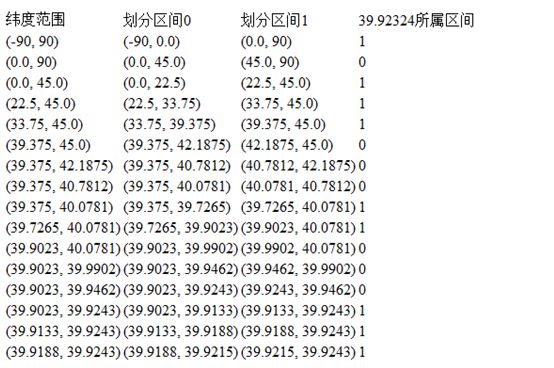
所以通过16轮的计算后得到经度39.92324的编码为:1011 1000 1100 0111 1001
经度也用同样的算法,对(-180, 180)多轮的依次细分计算:
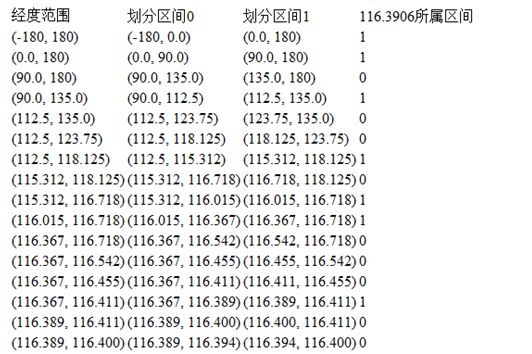
得到经度116.3906的编码为1101 0010 1100 0100 0100
经纬度的编码都计算完毕后,接下来就需要合并经纬度的编码,规则是以经度开始,依次每次取一位合并成5位的新编码,如上图红色字标示顺序所示:

完成合并编码后就需要将该编码和base32编码表对应起来,做法是每5位为一个十进制数,以11100为例,它的十进制数是28,所以对应的base32编码表示W,如下图所示:
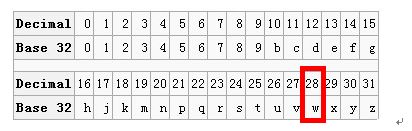
其他的五位编码依次从表中找到对应位置后,(39.92324 纬度, 116.3906 经度)的base32编码为:wx4g0ec1
解码算法与编码算法相反,先进行base32解码,然后分离出经纬度,最后根据二进制编码对经纬度范围进行细分即可,这里不再赘述。不过由于geohash表示的是区间,编码越长越精确,但不可能解码出完全一致的地址
关于Solr+Lucene使用Cartesian Tiers 笛卡尔层和GeoHash的构建索引和查询的细节介绍将在新的Blog中阐述。
在Solr中其实支持很多默认距离函数,但是基于坐标构建索引和查询的主要会基于2种方案:
(1)GeoHash
(2)Cartesian Tiers+GeoHash
而这块的源码实现都在lucene-spatial.jar中可以找到。接下来我将根据这2种方案展开关于构建索引和查询细节进行阐述,都是代码分析,感兴趣的看官可以继续往下看。
GeoHash
构建索引阶段
定义geohash域,在schema.xml中定义:
<fieldtype name="geohash" class="solr.GeoHashField"/>
接下来再构建索引的时候使用到lucene-spatial.jar的GeoHashUtils类:
String geoHash = GeoHashUtils.encode(latitude, longitude);//通过geoHash算法将经纬度变成base32的编码
document.addField("geohash", geoHash); //将经纬度对应的bash32编码存入索引。
查询阶段
在solrconfig.xml中配置好QP,该QP将对用户的请求Query进行QParser,查询语法规范是
{!spatial sfield=geofield pt= latitude, longitude d=xx, sphere_radius=xx }
sfield:geohash对应的域名
pt:经纬度字符串
d=球面距离
sphere_radius:圆周半径
接下来看看QP是如何解析上述查询语句,然后生成基于GeoHash的Query的,见如下代码,代码来源SpatialFilterQParser的parse()方法:
- //GeohashType一定是继承SpatialQueryable的
- if (type instanceof SpatialQueryable) {
- double radius = localParams.getDouble(SpatialParams.SPHERE_RADIUS, DistanceUtils.EARTH_MEAN_RADIUS_KM); //圆周半径
- //pointStr=经纬度串,dist=距离,DistanceUnits.KILOMETERS 距离单位
- SpatialOptions opts = new SpatialOptions(pointStr, dist, sf, measStr, radius, DistanceUnits.KILOMETERS);
- opts.bbox = bbox;
- //通过GeoHashField 创建查询Query
- result = ((SpatialQueryable)type).createSpatialQuery(this, opts);
- }
其中最核心的方法便是GeoHashField的createSpatialQuery(),该方法负责生成基于geoHash的查询Query,展开看该方法:
- public Query createSpatialQuery(QParser parser, SpatialOptions options) {
- double [] point = new double[0];
- try {
- //解析经纬度
- point = DistanceUtils.parsePointDouble(null, options.pointStr, 2);
- } catch (InvalidGeoException e) {
- throw new SolrException(SolrException.ErrorCode.BAD_REQUEST, e);
- }
- //将经纬度编码成bash32,对如何编码请看本文geohash算法解析篇幅
- String geohash = GeoHashUtils.encode(point[0], point[1]);
- //TODO: optimize this
- return new SolrConstantScoreQuery(new ValueSourceRangeFilter(new GeohashHaversineFunction(getValueSource(options.field, parser),
- new LiteralValueSource(geohash), options.radius), "0", String.valueOf(options.distance), true, true));
- }
从源码中可以看到代码作者有标示TODO:optimize this,笔者从源码中看到这块的实现,也觉得确实有疑惑,整个大体实现流程是基于Lucene的Filter的方式来过滤命中docId,但是其过滤的范围让笔者看起来觉得性能会出现问题,可能也是源码中有TODO:optimize this的缘故吧。
接下来继续讲下核心处理流程,Lucene的查询规则是Query->Weight->Scorer,而主要负责查询遍历结果集合的就是Scorer,该例子也不例外,同样是:
SolrConstantScoreQueryà ConstantWeightà ConstantScorer,通过Query生成Weight,Weight生成Scorer,熟悉Lucene的读者应该很清楚了,这里不再累述,
其中ConstantScorer的通过docIdSetIterator遍历获取满足条件的docId
而docIdSetIterator便是前面源码中的ValueSourceRangeFilter,该Filter将会过滤掉不在一个指定球面距离范围内的数据,而ValueSourceRangeFilter并不是实际工作的类,它又将过滤交给了GeohashHaversineFunction,见ValueSourceRangeFilter如下代码:
- public DocIdSet getDocIdSet(final Map context, final IndexReader reader) throws IOException {
- return new DocIdSet() {
- ////lowerVal=0,upperVal=distance,includeLower=true,includeupper=true
- @Override
- public DocIdSetIterator iterator() throws IOException {
- ////valueSource= GeohashHaversineFunction,也是实际进行DocList过滤的类
- return valueSource.getValues(context, reader).getRangeScorer(reader, lowerVal, upperVal, includeLower, includeUpper);
- }
- };
- }
那么继续看GeohashHaversineFunction,首先看其 getRangeScorer()方法,最核心的部分为:
- if (includeLower && includeUpper) {
- return new ValueSourceScorer(reader, this) {
- @Override
- public boolean matchesValue(int doc) {
- //计算docId对应的经纬度和查询传入的经纬度的距离
- float docVal = floatVal(doc);
- //如果返回的docVal(目标坐标和查询坐标的球面距离)在给定的distance之内则返回true
- //也就是说目标地址为待查询的周边范围内
- return docVal >= l && docVal <= u;
- }
- };
- }
所以再看看计算球面距离的GeohashHaversineFunction.floatVal()方法,可以从该方法最终调用的是distance()方法,如下所示:
- protected double distance(int doc, DocValues gh1DV, DocValues gh2DV) {
- double result = 0;
- String h1 = gh1DV.strVal(doc); //docId对应的经纬度的base32编码
- String h2 = gh2DV.strVal(doc); //查询的经纬度的base32编码
- if (h1 != null && h2 != null && h1.equals(h2) == false){
- //TODO: If one of the hashes is a literal value source, seems like we could cache it
- //and avoid decoding every time
- double[] h1Pair = GeoHashUtils.decode(h1); //base32解码
- double[] h2Pair = GeoHashUtils.decode(h2);
- //计算2个经度纬度之间的球面距离
- result = DistanceUtils.haversine(Math.toRadians(h1Pair[0]), Math.toRadians(h1Pair[1]),
- Math.toRadians(h2Pair[0]), Math.toRadians(h2Pair[1]), radius);
- } else if (h1 == null || h2 == null){
- result = Double.MAX_VALUE;
- }
- //返回2个经纬度之间球面距离
- return result;
- }
所以整个查询流程是将索引中的所有docId从第一个docId 0开始,对应的经度纬度和查询经纬度的球面距离是否在查询给定的distance之内,满足着将该docId返回,不满足则过滤。
大家可能看到是所有docId,这也是笔者觉得该过滤范围实现不靠谱的地方,也许是作者说需要进一步优化的地方。大家如果对怎么是所有docId进行过滤有疑惑,可以查看ValueSourceScorer的nextDoc() advance()方法,相信看过之后就明白了。到此Solr基于GeoHash的查询实现介绍完毕了。