Eclipse下配置使用Hadoop插件
【http://youzitool.com 新博客,欢迎访问】
前提,请先配置好Hadoop集群,并启动Hadoop守护进程。
集群搭建参见:http://blog.csdn.net/matraxa/article/details/7179366
我使用的软件版本如下:
Ubuntu: Ubuntu10.04
JDK: jdk1.6.0_25
Eclipse: Eclipse3.71
Hadoop: Hadoop-0.20.203.0
一、在Eclipse下配置Hadoop插件
1.复制 hadoop安装目录hadoop-0.20.203.0/contrib/eclipse-plugin/hadoop-eclipse-plugin-0.20.203.0.jar到eclipse安装目录下的plugins目录中。
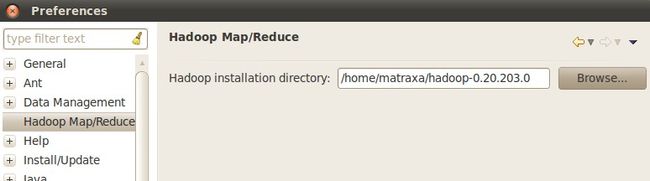
3.配置Map/Reduce Locations。
在Window-->Show View->other...,在MapReduce Tools中选择Map/Reduce Locations。
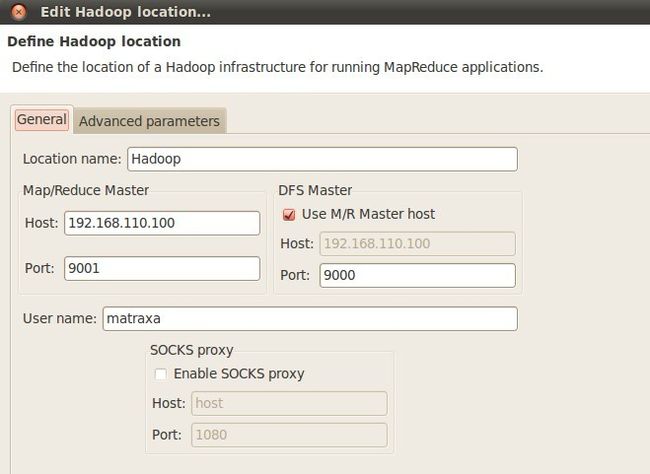
在Map/Reduce Locations(Eclipse界面的正下方)中新建一个Hadoop Location。在这个View中,点击鼠标右键-->New Hadoop Location。在弹出的对话框中你需要配置Location name,可任意填,如Hadoop,以及Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。我的这两个文件中配置如下:
mapred-site.xml
<property> <name>mapred.job.tracker</name> <value>matraxa:9001</value> </property>
core-site.xml:
<property> <name>fs.default.name</name> <value>hdfs://matraxa:9000</value> </property>
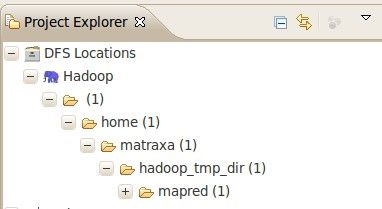
设置完成后,点击Finish就应用了该设置。然后,在最左边的Project Explorer中就能看到DFS的目录,如下图所示:
错误及解决方法
但是在我实践尝试中,发现hadoop-0.20.203.0版本的该包如果直接复制到eclipse的插件目录中,在连接DFS时会出现错误,提示信息为: "error: failure to login",弹出的错误提示框内容为"An internal error occurred during: "Connecting to DFS hadoop". org/apache/commons/configuration/Configuration". 经过察看Eclipse的log,发现是缺少jar包导致的。进一步查找资料后,发现直接复制hadoop-eclipse-plugin-0.20.203.0.jar,该包中lib目录下缺少了jar包。
经过网上资料搜集,此处给出正确的安装方法:
首先要对hadoop-eclipse-plugin-0.20.203.0.jar进行修改。用归档管理器打开该包,发现只有commons-cli-1.2.jar 和hadoop-core.jar两个包。将HADOOP_HOME/lib目录下的 commons-configuration-1.6.jar , commons-httpclient-3.0.1.jar , commons-lang-2.4.jar , jackson-core-asl-1.0.1.jar 和 jackson-mapper-asl-1.0.1.jar 等5个包复制到hadoop-eclipse-plugin-0.20.203.0.jar的lib目录下,如下图:
然后,修改该包META-INF目录下的MANIFEST.MF,将classpath修改为一下内容:
Bundle-ClassPath: classes/,lib/hadoop-core.jar,lib/commons-cli-1.2.jar,lib/commons-httpclient-3.0.1.jar,lib/jackson-core-asl-1.0.1.jar,lib/jackson-mapper-asl-1.0.1.jar,lib/commons-configuration-1.6.jar,lib/commons-lang-2.4.jar
如下图:
这样就完成了对hadoop-eclipse-plugin-0.20.203.0.jar的修改。
最后,将hadoop-eclipse-plugin-0.20.203.0.jar复制到Eclipse的plugins目录下,重启Eclipse即可。
二、在Eclipse中建立项目测试Hadoop插件是否成功配置
1、新建项目。
File-->New-->Other-->Map/Reduce Project
项目名可以随便取,如hadoopTest。
复制 hadoop安装目录/src/example/org/apache/hadoop/example/WordCount.java到刚才新建的项目下面。
2、上传模拟数据文件夹。
为了运行程序,需要一个输入的文件夹和输出的文件夹。输出文件夹,在程序运行完成后会自动生成。我们需要给程序一个输入文件夹。
(1)、在当前目录(如hadoop安装目录)下新建文件夹input,并在文件夹下新建两个文件file01、file02,这两个文件内容分别如下:
file01
Hello World Bye World
file02
Hello Hadoop Goodbye Hadoop
(2)、.将文件夹input上传到分布式文件系统中。
在已经启动Hadoop守护进程终端中cd 到hadoop安装目录,运行下面命令:
bin/hadoop fs -put input input
3、运行项目。
(1)、在新建的项目hadoop-test,点击WordCount.java,右键-->Run As-->Run Configurations
(2)、在弹出的Run Configurations对话框中,点Java Application,右键-->New,这时会新建一个application名为WordCount
(3)、配置运行参数,点Arguments,在Program arguments中输入“你要传给程序的输入文件夹和你要求程序将计算结果保存的文件夹”,如:
hdfs://matraxa:9000/user/matraxa/input hdfs://matraxa:9000/user/matraxa/output
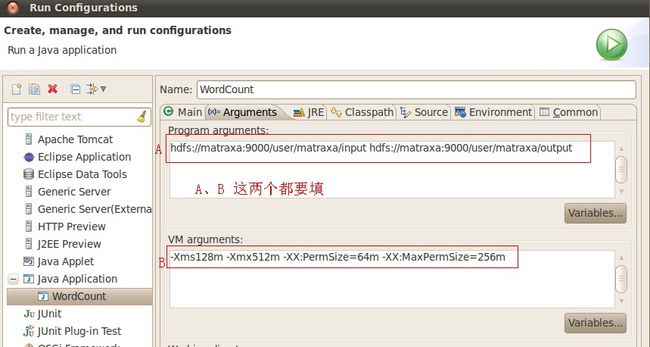
注意:虚拟机的启动参数"VM arguments"还是要填,不然会报堆不够的错误!具体见上图的填法
(4)、点击Run,运行程序。
点击Run,运行程序,过段时间将运行完成,等运行结束后,可以在终端中用命令如下,查看是否生成文件夹output:
bin/hadoop fs -ls
用下面命令查看生成的文件内容:
bin/hadoop fs -cat output01/*
如果显示如下,说明已经成功在eclipse下运行第一个MapReduce程序了。
Bye 1 Goodbye 1 Hadoop 2 Hello 2 World 2
参考文章:
http://phz50.iteye.com/blog/932373
http://hi.baidu.com/wangyucao1989/blog/item/279cef87c4b37c34c75cc315.html