在应用中嵌入使用Mahout,实现Kmeans聚类(非打包jar运行模式)
最近在项目中要使用Mahout来进行Kmeans聚类,搜了一下资料,发现大多数都是用hadoop jar的形式运行Mahout程序。我们的项目是一个后端接口服务,也就是需要放在resin或tomcat中运行的war程序。这就不可能打包成jar,用hadoop jar这种粗糙的形式来跑了。
hadoop之所以需要我们把程序打包成jar,是因为他需要把我们的程序分发到各个分布式节点中跑。那有什么办法可以让他不需要我们打包jar也可以分布式运行呢?
首先理解一个概念,真正需要分发到各个节点运行的是Mahout内部的运算逻辑。所以,如果我们在hadoop的mapreduce classpath中加入mahout相关的jar包,就可以实现这个目的。
增加这个配置:
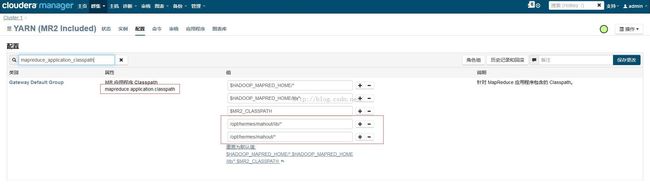
增加之后点右上角的保存修改即可。
也可以在mapred-site.xml配置文件中手动修改,见如下:
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/*,$HADOOP_MAPRED_HOME/lib/*,$MR2_CLASSPATH,/opt/hermes/mahout/lib/*,/opt/hermes/mahout/*</value>
</property>这种方式修改完成之后需要重启hadoop使之生效。
注:这上面的/opt/hermes/mahout是我linux环境里的mahout安装位置。
接下来看一下我的Kmeans工具类:
package com.cn21.function; import java.io.IOException; import java.net.URI; import java.util.List; import java.util.Set; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.util.ToolRunner; import org.apache.log4j.Logger; import org.apache.mahout.clustering.kmeans.KMeansDriver; import org.apache.mahout.common.HadoopUtil; import org.apache.mahout.utils.clustering.ClusterDumper; import org.apache.mahout.vectorizer.SparseVectorsFromSequenceFiles; import com.cn21.common.config.DefaultConfigure; import com.cn21.function.hadoop.SequenceFilesFromDirectory; import com.cn21.util.HdfsUtil; import com.cn21.util.ReadFileInLineTool; import com.google.common.collect.Lists; import com.google.common.collect.Sets; import com.google.gson.Gson; /** * <p> * Kmeans文本聚类 * <p> * * @author <a href="mailto:[email protected]">kexm</a> * @version * @since 2015年11月19日 * */ public class KmeansClusterFunction { private static final Logger log = Logger.getLogger(KmeansClusterFunction.class); /** * Kmeans文本聚类 * @param inputDir * @param hadoopDir * @param outputFilePath * @return * @throws Exception */ public static Set<List<String>> run(String inputDir, String hadoopDir, String outputFilePath) throws Exception { log.info("method[run] begin inputDir<" + inputDir + "> hadoopDir<" + hadoopDir + "> outputFilePath<" + outputFilePath + ">"); String seqFileOutput = LOCAL_FILE_PREFIX + outputFilePath + "/SeqFile"; String seqFileHadoopPath = hadoopDir + "/SeqFile"; String vectorOutFile = LOCAL_FILE_PREFIX + outputFilePath + "/VectorFile"; String vectorHadoopFile = hadoopDir + "/VectorFile"; String hadoopVectorOutFile = hadoopDir + "/VectorFile"; String dictionaryFileName = hadoopVectorOutFile + "/dictionary.file-0"; String tdidfFileName = hadoopVectorOutFile + "/tfidf-vectors"; String initCluster = hadoopDir + "/kmeans-init-clusters"; String kmeansPath = hadoopDir + "/kmeans"; String kmeansClusterPoint = kmeansPath + "/clusteredPoints"; String kmeansDumpPath = outputFilePath + "/kmeans-result"; /** 1. 如果结果文件已经存在,删除结果文件 */ Configuration conf = new Configuration(); conf.addResource("hdfs-site.xml.mahout"); conf.addResource("mapred-site.xml.mahout"); conf.addResource("core-site.xml.mahout"); conf.addResource("yarn-site.xml.mahout"); log.info("config init"); HadoopUtil.delete(conf, new Path(seqFileOutput)); HadoopUtil.delete(conf, new Path(seqFileHadoopPath)); HadoopUtil.delete(conf, new Path(vectorOutFile)); HadoopUtil.delete(conf, new Path(hadoopVectorOutFile)); HadoopUtil.delete(conf, new Path(initCluster)); HadoopUtil.delete(conf, new Path(kmeansPath)); HadoopUtil.delete(conf, new Path(kmeansDumpPath)); log.info("method[run] deleted."); HdfsUtil.createHadoopDir(hadoopDir); log.info("method[run] ahadoopDir<" + hadoopDir + "> created."); /** Step1: 把存放邮件的文件夹转成Seq文件*/ log.info("starting dir to seq job"); log.info("conf<"+conf.get("yarn.resourcemanager.address")+">"); String[] dirToSeqArgs = { "--input", inputDir, "--output", seqFileOutput, "--method", "sequential", "-c", "UTF-8", "-chunk", "64" }; ToolRunner.run(new SequenceFilesFromDirectory(), dirToSeqArgs); log.info("finished dir to seq job"); log.info("starting copy vector files to hadoop vectorOutFile<" + vectorOutFile + "> hadoopDir<" + hadoopDir + ">"); /** Step2: seq文件上传至hadoop*/ FileSystem fs = FileSystem.get(new URI(DefaultConfigure.config.hadoopDir), conf); fs.copyFromLocalFile(false, true, new Path(seqFileOutput), new Path(hadoopDir)); log.info("finished copy"); /** Step3: seq文件转为vector*/ log.info("starting seq To Vector job seqFileHadoopPath<" + seqFileHadoopPath + "> vectorOutFile<" + vectorHadoopFile + ">"); String[] seqToVectorArgs = { "--input", seqFileHadoopPath, "--output", vectorHadoopFile, "-ow", "--weight", "tfidf", "--maxDFPercent", "85", "--namedVector", "-a", "org.apache.lucene.analysis.core.WhitespaceAnalyzer" }; ToolRunner.run(conf, new SparseVectorsFromSequenceFiles(), seqToVectorArgs); log.info("finished seq to vector job"); /** Step4: kmeans运算*/ log.info("starting kmeans job tdidfFileName<" + tdidfFileName + "> initCluster<" + initCluster + "> kmeansPath<" + kmeansPath + ">"); String[] kmeansArgs = { "-i", tdidfFileName, "-o", kmeansPath, "-k", "5", "-c", initCluster, "-dm", "org.apache.mahout.common.distance.CosineDistanceMeasure", "-x", "100", "-ow", "--clustering" }; ToolRunner.run(conf, new KMeansDriver(), kmeansArgs); log.info("finished kmeans job"); String finalResult = ""; FileStatus[] files = fs.listStatus(new Path(kmeansPath)); for (FileStatus file : files) { if (file.getPath().getName().contains("-final")) { finalResult = file.getPath().toString(); } } /** Step5:解析聚类结果*/ log.info("starting clusterDumper finalResult<" + finalResult + "> dictionaryFileName<" + dictionaryFileName + "> kmeansDumpPath<" + kmeansDumpPath + "> " + "kmeansClusterPoint<" + kmeansClusterPoint + ">"); ClusterDumper dump = new ClusterDumper(); String[] dumperArgs = { "-i", finalResult, "-d", dictionaryFileName, "-dt", "sequencefile", "-o", kmeansDumpPath, "--pointsDir", kmeansClusterPoint, "-n", "20" }; dump.run(dumperArgs); log.info("finished clusterDumper job."); /** Step6:从聚类结果中读取*/ Set<List<String>> result = readDump(kmeansDumpPath); log.info("result<" + new Gson().toJson(result) + ">"); /**清除运算过程产生的文件*/ HadoopUtil.delete(conf, new Path(kmeansDumpPath)); HadoopUtil.delete(conf, new Path(hadoopDir)); log.info("method[run] file<"+kmeansDumpPath+"> <"+hadoopDir+"> deleted."); return result; } /** * 读聚类结果文件,从中获得每个话题的关键词 * @param kmeansDumpPath * @return * @throws IOException */ private static Set<List<String>> readDump(String kmeansDumpPath) throws IOException { ReadFileInLineTool rt = new ReadFileInLineTool(); rt.setPath(kmeansDumpPath); Set<List<String>> result = Sets.newHashSet(); List<String> topic = Lists.newArrayList(); boolean inTopic = true; String line = ""; while ((line = rt.readLine()) != null) { // log.info("line<" + line + ">"); if (!line.contains("=>")) { if (inTopic) { result.add(topic); topic = Lists.newArrayList(); inTopic = false; } continue; } inTopic = true; String term = line.split("=>")[0].trim(); topic.add(term); } return result; } private static final String LOCAL_FILE_PREFIX = "file:///"; }
这个类接收三个参数,inputDir是一个包含多个文本文件的目录,每个文本文件中是一篇已用空格分词好的文章;hadoopDir是一个hdfs目录,用于存放运算过程文件;outputFilePath是存放最终ClusterDump文件的目录。输出一个Set<List<String>>,包括了N个主题,每个主题里有M个关键词。
这里有一个关键点,Configuration的配置。
此处我选择让conf加载classpath(项目中是WEB-INF/classes目录)下的四个文件,但这四个文件没有用原始命名,而是在文件后增加了 ".mahout"后缀。
原因是SequenceFilesFromDirectory是需要在本地跑local job的,不可以用分布式job跑。因为这里要合并的文件目录是本地目录而非hadoop目录(要是是hadoop目录,就不用转化SequenceFile了)。我翻看了一下SequenceFilesFromDirectory的源码,它在我们配置--method sequential的情况下,会创建一个默认的Configuration作为它的配置,Configuration在创建时会默认读取classpath下的hdfs-site.xml和core-site.xml,这样会令SequenceFilesFromDirectory在--method sequential时也跑在分布式 job上,引起出错。因此,我修改了配置文件的后缀。确保SequenceFilesFromDirectory跑本地job。
当然,最好是用 conf.set("attr", "value") 的形式来配置Configuration,这样也可以免除这个问题。
到这里,接口里就可以正常调用mahou的分布式计算了。
截一小段我的邮件的聚类结果,因为平时没用邮箱,都是些测试邮件,所以结果不是很规律。
调试过程遇到的错误:
1. 这是Configuration配置不当引起的。
Error: org.apache.hadoop.mapreduce.task.reduce.Shuffle$ShuffleError: Error while doing final merge at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:160)at org.apache.hadoop.mapred.ReduceTask.run(ReduceTask.java:376)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1671)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)Caused by: java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.mahout.math.VectorWritable not foundat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2231)at org.apache.hadoop.mapred.JobConf.getOutputValueClass(JobConf.java:1096)at org.apache.hadoop.mapred.JobConf.getMapOutputValueClass(JobConf.java:847)at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.finalMerge(MergeManagerImpl.java:693)at org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl.close(MergeManagerImpl.java:371)at org.apache.hadoop.mapreduce.task.reduce.Shuffle.run(Shuffle.java:158)... 6 moreCaused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.mahout.math.VectorWritable not foundat org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2199)at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2223)... 11 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.mahout.math.VectorWritable not foundat org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2105)at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2197)... 12 more
3. map时就报classNotFound错误,这是因为hadoop的classpath中没有包含mahout的jar导致的。
Error: java.lang.ClassNotFoundException: org.apache.lucene.analysis.standard.StandardAnalyzerat java.net.URLClassLoader$1.run(URLClassLoader.java:366)at java.net.URLClassLoader$1.run(URLClassLoader.java:355)at java.security.AccessController.doPrivileged(Native Method)at java.net.URLClassLoader.findClass(URLClassLoader.java:354)at java.lang.ClassLoader.loadClass(ClassLoader.java:425)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)at java.lang.ClassLoader.loadClass(ClassLoader.java:358)at org.apache.mahout.vectorizer.document.SequenceFileTokenizerMapper.setup(SequenceFileTokenizerMapper.java:62)at org.apache.hadoop.mapreduce.Mapper.run(Mapper.java:142)at org.apache.hadoop.mapred.MapTask.runNewMapper(MapTask.java:787)at org.apache.hadoop.mapred.MapTask.run(MapTask.java:341)at org.apache.hadoop.mapred.YarnChild$2.run(YarnChild.java:163)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:415)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1671)at org.apache.hadoop.mapred.YarnChild.main(YarnChild.java:158)
希望能帮大家少走弯路。本文中的图都比较大,可以右键查看原图。