用PGCL为安卓编写有效的OpenCL代码
在前一篇文章中,我们介绍了创建一款可用于OpenCL的安卓应用所的安卓应用所需的基本步骤,这款应用可与作为OpenCL计算设备的NEON/SIMD扩展程序并行运行于多个ARM CPU内核。本文我们重点介绍使用PGCL为多核ARM编写有效的OpenCL代码,而PGCL是一种用于以ARM处理器为基础的系统级芯片(SoCs)的OpenCL编译器架构。
你需要了解OpenCL执行和编程模型的基本概念,从而为OpenCL设备编写最佳应用。本文第一部分将简要介绍OpenCL执行和编程模型。此外,还会详细介绍用于多核CPU的OpenCL执行模型在PGCL架构下的运行。第二部分介绍如何使用PGCL编写有效的OpenCL核心程序,特别是用于编写有利于多核CPU的有效OpenCL代码的相关技巧。
OpenCL执行和编程模型
OpenCL界定的是一种平台模型,它包含一个连接着一台或多台OpenCL计算设备的主机。一台OpenCL计算设备分为一个或多个计算单元,然后继续分成一个或多个处理元件。在OpenCL计算设备上的执行由主机控制和驱动。基于此原因,OpenCL编程模型将代码划分为两部分:一是主机代码,采用一套标准的CAPI函数引用,用于管理计算设备,并在计算设备上启动代码执行;二是以OpenCL-C语言编写的设备代码,成为各处理元件执行的操作指令。
OpenCL界定的是一种并行编程模型,其计算指令根据核心程序来进行描述。采用OpenCL-C语言编写的核心程序定义的是由一个工作项执行的计算指令,而该工作项则由单个处理元件执行。工作项被归纳为工作组,每个工作组均由单个计算单元执行。工作项并行执行,并可在同一工作组中使用同步原语与其他工作项协作, 也可在指定的计算单元中与本地存储器协作,而该存储器由所有处理元件共享。
与此相反,工作组之间不能同步。对于一项给定的计算,程序员必须编写一个核心程序来明确工作项的任务,然后说明如何把这些工作项归集成工作组,并通过界定一个OpenCL NDRange来明确这些计算所适合的域。对于一个给定的核心程序,工作项可以通过查询工作组内的索引,以及NDRange内的工作组索引(或全局索引)来检索坐标(相当于适合其计算指令的域的坐标)。
该编程/执行模型能够与最新的CPU+GPU架构相匹配,CPU作为OpenCL主机,GPU则作为OpenCL计算设备。不过,OpenCL标准不会限定GPU核心程序的执行。它还界定了其他OpenCL计算设备的类型:GPU型、CPU型,以及硬件加速器型,但是不管计算设备为何种类型,编程模型均保持一致。
我们考虑一个简单函数f(x),让它适用于矩阵A中的各个因素。使用C语言,这种计算可能会编写成这样:
for (j=0; j<dimY; j++)
for (i=0; i<dimX; i++)
B|j][i] = f(A[j][i]) ;
如图1所示,如果SIMD单元为在n个因素的矢量上运行的函数f(x)提供支持,则用于具有SIMD性能的多核CPU的并行/优化编译程序可以在CPU内核上分配j 次循环迭代,并将i次循环迭代矢量化。
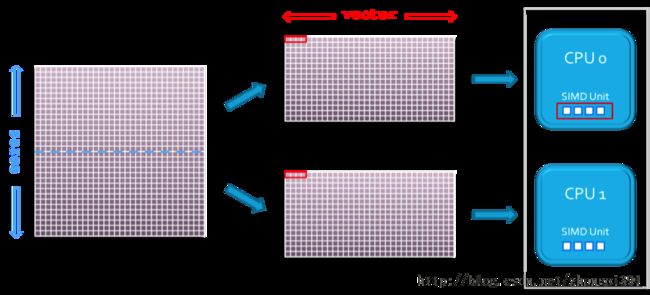
图1:在双核CPU上的计算指令分布
OpenCL内有许多可能的变体来匹配核心程序和计算设备,而程序员必须定义如何将这些计算指令进行有效分组(如1D、2D或3D)。最佳选择取决于运行的计算指令以及OpenCL计算设备的架构和性能。
例如,程序员可能决定各个工作项都需计算矩阵中的一列。在该情况下,程序员将定义一个OpenCL核心程序代码,如下:
int i, j ;
j = get_global_id(0) ; /* global coordinate for work-item, here line number */
for (i=0; i<dimX; i++)
B|j][i] = f(A[j][i]) ;
主机代码应指定工作组大小和形状。例如,每个工作组需处理的列数,以及用于NDRange的1D域 ,二者共同限定所处理的矩阵行数。
如果程序员决定各工作项均需计算一个矩阵点,OpenCL核心程序代码可编写如下:
int i, j ; i = get_global_id(0) ; /* global X coordinate for work-item */ j = get_global_id(1) ; /* global Y coordinate for work-item */ B|j][i] = f(A[j][i]) ;
主机代码应指定工作组大小和形状。例如,每个工作组处理的点数,以及一个NDRange的2D域,二者共同限定需处理的矩阵点数量。如图2所示,工作组可以分布于OpenCL设备的计算单元,工作项可以分布于给定计算单元内的处理元件。NDRange限定了需处理的工作组数量,以及他们在计算单元内如何分布。
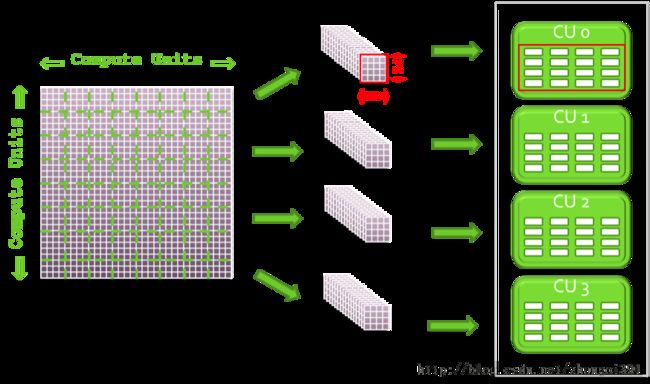
图2: 在含有4个计算单元的OpenCL设备上分布计算指令
按图2分布计算指令,可与当前GPGPU架构很好地匹配。
在设计PGCL时,我们知道多数可开放使用的OpenCL代码均适用于GPGPU设备。他们采用大型工作组的规模以及1D,2D或3D的形状,并利用了工作组之间的并行优势以及各工作组内工作项之间的并行优势。在带有NEONSIMD单元的多核Cortex-A9CPU上,我们可以指定一台OpenCL设备,在该设备上,每个内核即为一个计算单元,依赖NEON单元提供工作项之间的并行。不过,目前的NEON单元没有为工作项可能执行的运行指令提供语义。
次要选项可能将工作组规模限定为唯一工作项。这种解决方案可能非常有效,能与多核CPU硬件性能相匹配,且符合OpenCL标准。不过,它也可能阻碍我们进行编译以及运行现有的多数OpenCL代码。因此,我们决定执行PGCL OpenCL运行时,以便使用环境变量来定制OpenCL计算设备 ,从而支持任何规模的工作组运行256个工作项。每个CPU内核的线程都用于管理工作组执行,而工作项则采用用户级伪线程进行仿真。
这种方法足够灵活,不用修改即可运行多数GPGPU类型的OpenCL应用,代价则是性能也许不佳。缺乏工作项之间的实际并行,以及严重影响工作项之间同步,在某些情况下可导致性能变得极差。为解决此问题,我们在PGCL运行时中应用了三种执行模型。
- 对于任何规模的工作组,如果核心程序没有在工作项之间使用同步原语,运行则被序列化。在进行下一步前,各工作项都会执行结束,而且,在整个工作组执行期间,内核基本自由运行。
- 对于任何规模的工作组,如果核心程序在工作项之间采用同步原语,并行执行则可通过采用用户级仿线程进行仿真。一个工作项实现同步原语时可能会进行上下文切换,跳转执行下一个没有到达同步点的工作项。一旦所有工作项均到达同步点,则从第一个工作项重新开始执行,直至到达下一个同步点。
- 对于只有一个工作项的工作组,如果核心程序使用同步原语,那么原语执行则是nop-ified(删除同步基本是因为它对核心程序的执行不具有逻辑影响。)
这些执行模型允许程序员在没有高性能要求的模型中运行任何适用的GPGPU OpenCL代码,但需要对它们进行正确编译和运行,并逐步让核心程序适应这种有利于CPU以最佳速度运行的形式。
为多核CPU设备编写有效的OpenCL核心程序
以上内容我们介绍了OpenCL执行模型,及其在PGCL运行时中的执行。了解PGCL的执行引擎,有助于我们制定指南,用于为作为OpenCL计算设备的多核Cortex-A9CPU编写有效代码。事实上,这些规则适用于未来任何一种由PGCL运行时支持的多核ARM CPU计算设备。
需切记的是,在PGCL运行时中,对于多核CPU OpenCL计算设备而言,工作项之间就没有真正的并行。记住这点,下面的规则可用于为多核CPU计算设备编写有效代码。
1、与一个处理较少计算指令,但由许多工作项执行的核心程序相比,编写一个由较少工作项执行,但可进行多项计算指令的核心程序则更好。为GPU设备编写的OpenCL核心程序通常将计算指令分组,因此工作项可以“像素点”为基础运行计算指令,例如,对于一个CPU设备而言,建议工作项按“行”运行。回到我们的矩阵范例中,对于一个多核CPU而言, 编写可以计算矩阵行且由少量工作项执行的核心程序代码,要优于编写计算矩阵点且由较多工作项执行的核心程序代码。
例如,一个简单的图像水平切换核心程序可以编写如下:
__kernel void inverse_image_pixel (__global unsigned int* pixels)
{
int x = get_global_id(0);
int y = get_global_id(1);
int w = 2*get_global_size(0);
int i0 = x+y*w;
int i1 = (y+1)*w-x-1;
unsigned int tmp = pixels[i1];
pixels[i1] = pixels[i0];
pixels[i0] = tmp;
}
该情况下,各工作项执行两个像素点的切换。在此核心程序中,工作项任务有限。计算各像素点坐标所进行的操作较多,其支出大于切换像素点的支出,因此该代码执行情况可能很差。为使性能更好,较好的做法是按成块的像素点来执行像素点切换。因此,对多核CPU设备而言,最好将核心程序代码重写如下:
__kernel void inverse_image_block (__global unsigned int* pixels, int
blk_size_x, int blk_size_y, int image_width)
{
int x = get_global_id(0)*blk_size_x;
int y = get_global_id(1)*blk_size_y;
int i0 = x+y*image_width;
int i1 = (y+1)*image_width-x-1;
int i, j;
for (j=0; j<blk_size_y; j++)
{
for (i=0; i<blk_size_x; i++)
{
unsigned int tmp = pixels[i1-i];
pixels[i1-i] = pixels[i0+i];
pixels[i0+i] = tmp;
}
i0 += image_width ;
i1 += image_width ;
}
}
各工作项随后执行成块像素点的切换,减少与像素点切换成本有关的索引成本。该代码足够灵活,可以在任何规模和任何数量的工作组中(甚至是只有唯一工作项的工作组)运行,从而与目标CPU设备上可用的内核数量相匹配。
2、如果可能,应避免使用工作项的同步原语。同步原语(如OpenCL屏障)被编写到本地存储器后,常用来进行工作项同步。在一台GPGPU设备上,需要使用本地存储器,从而将响应时间较长设备的全局存储器的影响最小化。
a、在一台由PGCL运行时支持的多核CPU OpenCL计算设备上,OpenCL本地存储器和全局存储器并无硬件差别。二者均位于同一存储器,此情况下,DDR存储器通过CPU L2高速缓冲存储器访问。因此,使用本地存储器访问与使用全局存储器访问相比并无优劣之分,因为二者均通过共享相同的L2高速缓冲存储器运行,访问的是相同的物理内存。
b、要减少操作(例如一个阵列中所有元件的总和),通常在GPGPUOpenCL设备上使用对数分裂求和法来执行,如下列代码片段所示:
/* locSumArray: local array of resulting sums
* wiIndex: Work-Item index
* wgSize: Work-Group size, size of local array
* After call to this routine locSumArray[0] = SUM(locSumArray[0..wgSize])
*/
void sumAll(__local int* locSumArray, int wiIndex, int wgSize)
{
int stride ;
for (stride = wgSize/2; stride>0; stride>>=1)
{
if (wiIndex < stride)
locSumArray[wiIndex] += locSumArray[wiIndex+stride];
barrier(CLK_LOCAL_MEM_FENCE);
}
}
在第一步中,N/2的局部和通过N/2工作项执行并存储至本地阵列。在执行下一步之前进行工作项同步,下一步中,N/4工作项根据前面的结果计算局部和,并再次存储至本地阵列。重复此操作,直到执行完最后一步,由一个单独的工作项利用最后两项局部和计算出最终总和。这种方法要求将N个因素的总和按照log2N进行同步。
要在使用PGCL的多核CPU设备上有效执行,最好只由唯一的工作项计算N个因素的总和,然后将计算结果同步:
/* locSumArray: local array of resulting sums
* wiIndex: Work-Item index
* wgSize: Work-Group size, size of local array
* After call to this routine locSumArray[0] = SUM(locSumArray[0..wgSize])
*/
void sumAll(__local sum* locSumArray, int wiIndex, int wgSize)
{
int i ;
int sum = 0;
if (wiIndex == 0)
{
for (i=0; i<wgSize; i++)
{
sum += locSumArray[i] ;
}
locSumArray[0] = sum ;
}
barrier(CLK_LOCAL_MEM_FENCE);
}
3、如果可能,建议编写由一定数量的工作组执行的核心程序,这种工作组只有一个工作项。理想情况是,将工作组的数量限定为与平台上可用CPU内核相同的数量。不过,如果你将工作组的数量写死,那么在平台上运行代码时则不能与更多数量的CPU内核协调。使用一个以上工作项的工作组可以合理运行,只要工作项之间不进行同步,且各工作项均进行大量计算。
4、在多核ARM上进一步优化OpenCL代码,可以通过SIMD指令(也称NEON单元)实现。当OpenCL核心程序代码包含可向量化的循环时,或当OpenCL进行适量运算时,PGCL利用SIMD指令生成代码。要实现可向量化,在编译OpenCL核心程序时应将编译器选项指定为快速Mvect。
# pgcl ‑-opencl-flags ‑fast ‑Mvect ‑- sum.cl
将上述求和代码用于下列循环时:
…
for (i=0; i<wgSize; i++)
{
sum += locSumArray[i] ;
}
…
PGCL自动生成下列ARM NEONSIMD代码:
…
.LBB0_5: @ %L.B0007
@ =>This Inner Loop Header: Depth=1
vldmia r12, {d18, d19}
add r2, r12, #16
sub lr, lr, #8
add r12, r12, #32
vadd.i32 q8, q9, q8
cmp lr, #0
vldmia r2, {d18, d19}
vadd.i32 q8, q8, q9
bgt .LBB0_5
…
在此代码中,根据因数为8和4时并行计算的总和将循环展开。在详细说明处理最终总和时,余下的迭代次数(因为循环的迭代次数不是8的倍数)未在此处显示,PGCL编译器可以对他们进行正确处理。
如果你想调整控制矢量代码生成,可以使用OpenCL矢量数据类型。例如,求和核心程序可编写如下:
void sumAll4(__local int* locSumArray, int wiIndex, int wgSize)
{
int i = 0;
int4 sum4 = 0;
if (wiIndex == 0)
{
for (i=0; i<wgSize; i+=4)
{
sum4 += *((int4 *)&locSumArray[i]) ;
}
locSumArray[0] = sum4.x + sum4.y + sum4.z + sum4.w ;
}
barrier(CLK_LOCAL_MEM_FENCE) ;
}
然后,当采用PGCL- O2命令行选项时,主循环则生成如下:
…
.LBB0_4: @ %L.B0001
@ =>This Inner Loop Header: Depth=1
vldmia r3, {d18, d19}
sub r2, r2, #1
add r3, r3, #16
cmp r2, #0
vadd.i32 q8, q9, q8
bgt .LBB0_4
…
注意,正确执行此代码需假定locSumArray排列在int4范围内。在该情况下,程序员有责任保证阵列对齐,否则代码可能运行失败。还需注意 ‑fast–Mvect选项未被使用,因为在此情况下循环会被向量化。
结论
本文我们介绍了OpenCL执行模型,并详细说明了PGCL运行时在作为OpenCL计算设备的多核CPU上的运行情况。了解PGCL核心程序的执行模型有助于我们制定下列指南,用于为CPU类设备编写有效代码:
- 每个工作组处理较多计算指令
- 避免在OpenCL核心程序中使用OpenCL的屏障操作
- 尽量最小化每个工作组内工作项的数量(一个最好)
- 尽量减少工作组的数量,尤其是使用大量工作组时,要与目标设备上CPU内核数量相匹配
- 在多核ARM CPU上,通过在核心程序中编写可向量化的循环或使用OpenCL的矢量数据类型来利用NEON SIMD单元。
在今后的文章中,我们将详细介绍如何将这些规则运用到端口,以及如何利用PGCL把为GPGPU计算设备编写的可用于OpenCL的应用,优化为作为计算设备的多核ARM。