x264代码剖析(十二):核心算法之帧内预测函数x264_mb_analyse_intra()
x264代码剖析(十二):核心算法之帧内预测函数x264_mb_analyse_intra()
在帧内预测模式中,预测块是基于已编码重建块和当前块形成的,编码器通常选取预测块与编码块之间差异最小的预测模式。H.264帧内预测则是参考预测块左方或者上方的已编码块的临近像素点被引入空间域。
对于亮度像素而言,预测块用于16*16或4*4大小宏块的相关操作,其中,
(1)、16*16亮度块有4种预测模式,适用于平坦区域图像编码;
(2)、4*4亮度块有9种可选预测模式,独立预测每一个4*4大小的亮度子块,适用于带有大量细节的图像编码。
对于色度像素而言,色度块也有4种预测模式,类似于16*16大小亮度块的预测模式。
除此之外,H.264还有一种帧内编码模式I_PCM,该模式允许编码器直接传输图像的像素值,而不经过预测和变换。在一些特殊情况下,特别是图像内容不规则或者量化参数非常低时,该模式比起其他的“常规操作”(帧内预测——变换——量化——熵编码)效率更高。I_PCM模式的采用主要有以下几个目的:
(1)、允许编码器精确地表示像素值;
(2)、提供表示不规则图像内容的准确值,而不引起重大的数据量增加;
(3)、严格限制宏块解码比特数,但不损害编码效率。
1、16*16亮度预测模式
16*16大小的亮度块有4种预测模式,如下图:
2、4*4亮度预测模式
4*4大小亮度块的上方和左方像素为已编码并进行重构的像素,用作编解码器中的预测参考像素。4*4亮度块有9种可选预测模式,对应的预测模式以及描述如下:

3、8*8色度块预测模式
每个帧内编码宏块的8*8色度成分由已编码左上方色度像素预测而得,两种色度成分常用同一种预测模式。4种预测模式类似于帧内16*16预测的4种预测模式,只是模式编号不同。其中,DC为模式0,水平为模式1,垂直为模式2,平面为模式3。
4、帧内预测模式的选择
H.264采用拉格朗日率失真优化(Rate Distortion Optimization, RDO)策略进行最优化编码模式选择,通过遍历所有可能的编码模式,最后选择最小率失真代价模式作为最佳帧内预测模式。具体的编码模式选择过程概述如下:
(1)、计算当前4*4块和重建的4*4块之间的差值平方和(SSD,Sum of Squared Difference)以及编码的比特率;
(2)、计算9种帧内模式的率失真值;
(3)、选择具有最小率失真值的模式作为最佳4*4帧内预测模式;
(4)、对宏块内的16个4*4块重复上述(1)~(3),获得每一个4*4块的最佳预测模式和相应的最小率失真值;
(5)、累加计算得出16个块的最小率失真值,得到当前宏块的4*4帧内预测率失真值;
(6)、按照类似的方法,分别计算当前16*16大小宏块在4种模式下的宏块率失真值,选取宏块率失真最小的模式作为最佳帧内16*16预测模式;
(7)、根据(5)和(6)中的最小率失真值,选取亮度宏块采用4*4或16*16帧内预测模式;
(8)、8*8色度宏块的帧内预测模式与亮度类似。
在基本档次下,以色度模式为外循环,依次扫描亮度模式,搜索的总数是4*(9*16+4)=592次,获得的最优的帧内预测模式的计算量非常大。
5、x264中的帧内预测函数x264_mb_analyse_intra()分析
x264_mb_analyse_intra()用于对Intra宏块进行帧内预测模式的分析。该函数的定义位于encoder\analyse.c,函数关系图如下:
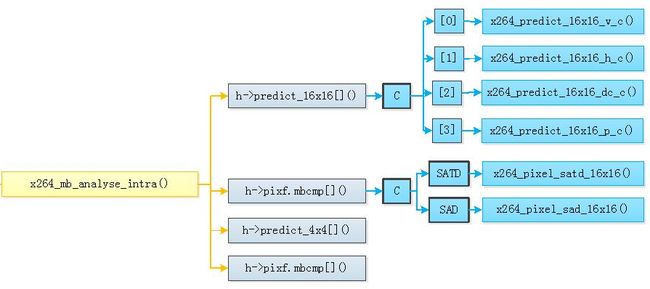
对应的代码分析如下:
/******************************************************************/
/******************************************************************/
/*
======Analysed by RuiDong Fang
======Csdn Blog:http://blog.csdn.net/frd2009041510
======Date:2016.03.14
*/
/******************************************************************/
/******************************************************************/
/************====== x264_mb_analyse_intra()函数 ======************/
/*
功能:帧内预测:从16x16的SAD,4个8x8的SAD和,16个4x4SAD中选出最优方式
*/
/* FIXME: should we do any sort of merged chroma analysis with 4:4:4? */
static void x264_mb_analyse_intra( x264_t *h, x264_mb_analysis_t *a, int i_satd_inter )
{
const unsigned int flags = h->sh.i_type == SLICE_TYPE_I ? h->param.analyse.intra : h->param.analyse.inter;
pixel *p_src = h->mb.pic.p_fenc[0];//p_fenc是编码帧
pixel *p_dst = h->mb.pic.p_fdec[0];//p_fdec是重建帧
static const int8_t intra_analysis_shortcut[2][2][2][5] =
{
{{{I_PRED_4x4_HU, -1, -1, -1, -1},
{I_PRED_4x4_DDL, I_PRED_4x4_VL, -1, -1, -1}},
{{I_PRED_4x4_DDR, I_PRED_4x4_HD, I_PRED_4x4_HU, -1, -1},
{I_PRED_4x4_DDL, I_PRED_4x4_DDR, I_PRED_4x4_VR, I_PRED_4x4_VL, -1}}},
{{{I_PRED_4x4_HU, -1, -1, -1, -1},
{-1, -1, -1, -1, -1}},
{{I_PRED_4x4_DDR, I_PRED_4x4_HD, I_PRED_4x4_HU, -1, -1},
{I_PRED_4x4_DDR, I_PRED_4x4_VR, -1, -1, -1}}},
};
int idx;
int lambda = a->i_lambda;
/*---------------- Try all mode and calculate their score ---------------*/
/* Disabled i16x16 for AVC-Intra compat */
/********************************************************************/
//帧内(I帧)16x16
/*
* 16x16块
*
* +--------+--------+
* | |
* | |
* | |
* + + +
* | |
* | |
* | |
* +--------+--------+
*
*/
/********************************************************************/
if( !h->param.i_avcintra_class )
{
//获得可用的帧内预测模式-针对帧内16x16
//左侧是否有可用数据?上方是否有可用数据?
const int8_t *predict_mode = predict_16x16_mode_available( h->mb.i_neighbour_intra );
/* Not heavily tuned */
static const uint8_t i16x16_thresh_lut[11] = { 2, 2, 2, 3, 3, 4, 4, 4, 4, 4, 4 };
int i16x16_thresh = a->b_fast_intra ? (i16x16_thresh_lut[h->mb.i_subpel_refine]*i_satd_inter)>>1 : COST_MAX;
if( !h->mb.b_lossless && predict_mode[3] >= 0 )
{
h->pixf.intra_mbcmp_x3_16x16( p_src, p_dst, a->i_satd_i16x16_dir );
a->i_satd_i16x16_dir[0] += lambda * bs_size_ue(0);
a->i_satd_i16x16_dir[1] += lambda * bs_size_ue(1);
a->i_satd_i16x16_dir[2] += lambda * bs_size_ue(2);
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[0], a->i_predict16x16, 0 );
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[1], a->i_predict16x16, 1 );
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[2], a->i_predict16x16, 2 );
/* Plane is expensive, so don't check it unless one of the previous modes was useful. */
//模式3:平面(一般不计算,除非前三种模式都没用)
if( a->i_satd_i16x16 <= i16x16_thresh )
{
h->predict_16x16[I_PRED_16x16_P]( p_dst ); ////////////////////16*16亮度预测模式:平面
a->i_satd_i16x16_dir[I_PRED_16x16_P] = h->pixf.mbcmp[PIXEL_16x16]( p_dst, FDEC_STRIDE, p_src, FENC_STRIDE );
a->i_satd_i16x16_dir[I_PRED_16x16_P] += lambda * bs_size_ue(3);
COPY2_IF_LT( a->i_satd_i16x16, a->i_satd_i16x16_dir[I_PRED_16x16_P], a->i_predict16x16, 3 );
}
}
else
{
//遍历所有的可用的Intra16x16帧内预测模式
//最多4种
for( ; *predict_mode >= 0; predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
//帧内预测汇编函数:根据左边和上边的像素计算出预测值
/*
* 帧内预测举例
* Vertical预测方式
* |X1 X2 ... X16
* --+---------------
* |X1 X2 ... X16
* |X1 X2 ... X16
* |.. .. ... X16
* |X1 X2 ... X16
*
* Horizontal预测方式
* |
* --+---------------
* X1| X1 X1 ... X1
* X2| X2 X2 ... X2
* ..| .. .. ... ..
* X16|X16 X16 ... X16
*
* DC预测方式
* |X1 X2 ... X16
* --+---------------
* X17|
* X18| Y
* ..|
* X32|
*
* Y=(X1+X2+X3+X4+...+X31+X32)/32
*
*/
if( h->mb.b_lossless )
x264_predict_lossless_16x16( h, 0, i_mode );
else
h->predict_16x16[i_mode]( p_dst ); ////////////////////16*16亮度预测模式,计算结果存储在p_dst重建帧中
//计算SAD或者是SATD(SATD(transformed)是经过Hadamard变换之后的SAD)
//即编码代价
//数据位于p_dst和p_src
i_satd = h->pixf.mbcmp[PIXEL_16x16]( p_dst, FDEC_STRIDE, p_src, FENC_STRIDE ) +
lambda * bs_size_ue( x264_mb_pred_mode16x16_fix[i_mode] ); ////////////////////计算SAD或者是SATD
//COPY2_IF_LT()函数的意思是“copy if little”。即如果值更小(代价更小),就拷贝。
//宏定义展开后如下所示
//if((i_satd)<(a->i_satd_i16x16))
//{
// (a->i_satd_i16x16)=(i_satd);
// (a->i_predict16x16)=(i_mode);
//}
COPY2_IF_LT( a->i_satd_i16x16, i_satd, a->i_predict16x16, i_mode );
a->i_satd_i16x16_dir[i_mode] = i_satd;//每种模式的代价都会存储
}
}
if( h->sh.i_type == SLICE_TYPE_B )
/* cavlc mb type prefix */
a->i_satd_i16x16 += lambda * i_mb_b_cost_table[I_16x16];
if( a->i_satd_i16x16 > i16x16_thresh )
return;
}
uint16_t *cost_i4x4_mode = (uint16_t*)ALIGN((intptr_t)x264_cost_i4x4_mode,64) + a->i_qp*32 + 8;
/* 8x8 prediction selection */
/********************************************************************/
//帧内(I帧)8x8
/********************************************************************/
if( flags & X264_ANALYSE_I8x8 )
{
ALIGNED_ARRAY_32( pixel, edge,[36] );
x264_pixel_cmp_t sa8d = (h->pixf.mbcmp[0] == h->pixf.satd[0]) ? h->pixf.sa8d[PIXEL_8x8] : h->pixf.mbcmp[PIXEL_8x8];
int i_satd_thresh = a->i_mbrd ? COST_MAX : X264_MIN( i_satd_inter, a->i_satd_i16x16 );
// FIXME some bias like in i4x4?
int i_cost = lambda * 4; /* base predmode costs */
h->mb.i_cbp_luma = 0;
if( h->sh.i_type == SLICE_TYPE_B )
i_cost += lambda * i_mb_b_cost_table[I_8x8];
for( idx = 0;; idx++ )
{
int x = idx&1;
int y = idx>>1;
pixel *p_src_by = p_src + 8*x + 8*y*FENC_STRIDE;
pixel *p_dst_by = p_dst + 8*x + 8*y*FDEC_STRIDE;
int i_best = COST_MAX;
int i_pred_mode = x264_mb_predict_intra4x4_mode( h, 4*idx );
const int8_t *predict_mode = predict_8x8_mode_available( a->b_avoid_topright, h->mb.i_neighbour8[idx], idx );
h->predict_8x8_filter( p_dst_by, edge, h->mb.i_neighbour8[idx], ALL_NEIGHBORS );
if( h->pixf.intra_mbcmp_x9_8x8 && predict_mode[8] >= 0 )
{
/* No shortcuts here. The SSSE3 implementation of intra_mbcmp_x9 is fast enough. */
i_best = h->pixf.intra_mbcmp_x9_8x8( p_src_by, p_dst_by, edge, cost_i4x4_mode-i_pred_mode, a->i_satd_i8x8_dir[idx] );
i_cost += i_best & 0xffff;
i_best >>= 16;
a->i_predict8x8[idx] = i_best;
if( idx == 3 || i_cost > i_satd_thresh )
break;
x264_macroblock_cache_intra8x8_pred( h, 2*x, 2*y, i_best );
}
else
{
if( !h->mb.b_lossless && predict_mode[5] >= 0 )
{
ALIGNED_ARRAY_16( int32_t, satd,[9] );
h->pixf.intra_mbcmp_x3_8x8( p_src_by, edge, satd );
int favor_vertical = satd[I_PRED_4x4_H] > satd[I_PRED_4x4_V];
satd[i_pred_mode] -= 3 * lambda;
for( int i = 2; i >= 0; i-- )
{
int cost = satd[i];
a->i_satd_i8x8_dir[idx][i] = cost + 4 * lambda;
COPY2_IF_LT( i_best, cost, a->i_predict8x8[idx], i );
}
/* Take analysis shortcuts: don't analyse modes that are too
* far away direction-wise from the favored mode. */
if( a->i_mbrd < 1 + a->b_fast_intra )
predict_mode = intra_analysis_shortcut[a->b_avoid_topright][predict_mode[8] >= 0][favor_vertical];
else
predict_mode += 3;
}
for( ; *predict_mode >= 0 && (i_best >= 0 || a->i_mbrd >= 2); predict_mode++ )
{
int i_satd;
int i_mode = *predict_mode;
if( h->mb.b_lossless )
x264_predict_lossless_8x8( h, p_dst_by, 0, idx, i_mode, edge );
else
h->predict_8x8[i_mode]( p_dst_by, edge );
i_satd = sa8d( p_dst_by, FDEC_STRIDE, p_src_by, FENC_STRIDE );
if( i_pred_mode == x264_mb_pred_mode4x4_fix(i_mode) )
i_satd -= 3 * lambda;
COPY2_IF_LT( i_best, i_satd, a->i_predict8x8[idx], i_mode );
a->i_satd_i8x8_dir[idx][i_mode] = i_satd + 4 * lambda;
}
i_cost += i_best + 3*lambda;
if( idx == 3 || i_cost > i_satd_thresh )
break;
if( h->mb.b_lossless )
x264_predict_lossless_8x8( h, p_dst_by, 0, idx, a->i_predict8x8[idx], edge );
else
h->predict_8x8[a->i_predict8x8[idx]]( p_dst_by, edge );
x264_macroblock_cache_intra8x8_pred( h, 2*x, 2*y, a->i_predict8x8[idx] );
}
/* we need to encode this block now (for next ones) */
x264_mb_encode_i8x8( h, 0, idx, a->i_qp, a->i_predict8x8[idx], edge, 0 );
}
if( idx == 3 )
{
a->i_satd_i8x8 = i_cost;
if( h->mb.i_skip_intra )
{
h->mc.copy[PIXEL_16x16]( h->mb.pic.i8x8_fdec_buf, 16, p_dst, FDEC_STRIDE, 16 );
h->mb.pic.i8x8_nnz_buf[0] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] );
h->mb.pic.i8x8_nnz_buf[1] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] );
h->mb.pic.i8x8_nnz_buf[2] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] );
h->mb.pic.i8x8_nnz_buf[3] = M32( &h->mb.cache.non_zero_count[x264_scan8[10]] );
h->mb.pic.i8x8_cbp = h->mb.i_cbp_luma;
if( h->mb.i_skip_intra == 2 )
h->mc.memcpy_aligned( h->mb.pic.i8x8_dct_buf, h->dct.luma8x8, sizeof(h->mb.pic.i8x8_dct_buf) );
}
}
else
{
static const uint16_t cost_div_fix8[3] = {1024,512,341};
a->i_satd_i8x8 = COST_MAX;
i_cost = (i_cost * cost_div_fix8[idx]) >> 8;
}
/* Not heavily tuned */
static const uint8_t i8x8_thresh[11] = { 4, 4, 4, 5, 5, 5, 6, 6, 6, 6, 6 };
if( a->b_early_terminate && X264_MIN(i_cost, a->i_satd_i16x16) > (i_satd_inter*i8x8_thresh[h->mb.i_subpel_refine])>>2 )
return;
}
/* 4x4 prediction selection */
/********************************************************************/
//帧内(I帧)4x4
/*
* 16x16 宏块被划分为16个4x4子块
*
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
* | | | | |
* +----+----+----+----+
*
*/
/********************************************************************/
if( flags & X264_ANALYSE_I4x4 )
{
int i_cost = lambda * (24+16); /* 24from JVT (SATD0), 16 from base predmode costs */
int i_satd_thresh = a->b_early_terminate ? X264_MIN3( i_satd_inter, a->i_satd_i16x16, a->i_satd_i8x8 ) : COST_MAX;
h->mb.i_cbp_luma = 0;
if( a->b_early_terminate && a->i_mbrd )
i_satd_thresh = i_satd_thresh * (10-a->b_fast_intra)/8;
if( h->sh.i_type == SLICE_TYPE_B )
i_cost += lambda * i_mb_b_cost_table[I_4x4];
//循环所有的4x4块
for( idx = 0;; idx++ )
{
//编码帧中的像素
//block_idx_xy_fenc[]记录了4x4小块在p_fenc中的偏移地址
pixel *p_src_by = p_src + block_idx_xy_fenc[idx];
//重建帧中的像素
//block_idx_xy_fdec[]记录了4x4小块在p_fdec中的偏移地址
pixel *p_dst_by = p_dst + block_idx_xy_fdec[idx];
int i_best = COST_MAX;
int i_pred_mode = x264_mb_predict_intra4x4_mode( h, idx );
//获得可用的帧内预测模式-针对帧内4x4
//左侧是否有可用数据?上方是否有可用数据?
const int8_t *predict_mode = predict_4x4_mode_available( a->b_avoid_topright, h->mb.i_neighbour4[idx], idx );
if( (h->mb.i_neighbour4[idx] & (MB_TOPRIGHT|MB_TOP)) == MB_TOP )
/* emulate missing topright samples */
MPIXEL_X4( &p_dst_by[4 - FDEC_STRIDE] ) = PIXEL_SPLAT_X4( p_dst_by[3 - FDEC_STRIDE] );
if( h->pixf.intra_mbcmp_x9_4x4 && predict_mode[8] >= 0 )
{
/* No shortcuts here. The SSSE3 implementation of intra_mbcmp_x9 is fast enough. */
i_best = h->pixf.intra_mbcmp_x9_4x4( p_src_by, p_dst_by, cost_i4x4_mode-i_pred_mode );
i_cost += i_best & 0xffff;
i_best >>= 16;
a->i_predict4x4[idx] = i_best;
if( i_cost > i_satd_thresh || idx == 15 )
break;
h->mb.cache.intra4x4_pred_mode[x264_scan8[idx]] = i_best;
}
else
{
if( !h->mb.b_lossless && predict_mode[5] >= 0 )
{
ALIGNED_ARRAY_16( int32_t, satd,[9] );
h->pixf.intra_mbcmp_x3_4x4( p_src_by, p_dst_by, satd );
int favor_vertical = satd[I_PRED_4x4_H] > satd[I_PRED_4x4_V];
satd[i_pred_mode] -= 3 * lambda;
i_best = satd[I_PRED_4x4_DC]; a->i_predict4x4[idx] = I_PRED_4x4_DC;
COPY2_IF_LT( i_best, satd[I_PRED_4x4_H], a->i_predict4x4[idx], I_PRED_4x4_H );
COPY2_IF_LT( i_best, satd[I_PRED_4x4_V], a->i_predict4x4[idx], I_PRED_4x4_V );
/* Take analysis shortcuts: don't analyse modes that are too
* far away direction-wise from the favored mode. */
if( a->i_mbrd < 1 + a->b_fast_intra )
predict_mode = intra_analysis_shortcut[a->b_avoid_topright][predict_mode[8] >= 0][favor_vertical];
else
predict_mode += 3;
}
if( i_best > 0 )
{
for( ; *predict_mode >= 0; predict_mode++ )//遍历所有Intra4x4帧内模式,最多9种
{
int i_satd;
int i_mode = *predict_mode;
if( h->mb.b_lossless )
x264_predict_lossless_4x4( h, p_dst_by, 0, idx, i_mode );
else
h->predict_4x4[i_mode]( p_dst_by ); ////////////////////帧内预测汇编函数-存储在重建帧中
//计算SAD或者是SATD(SATD(Transformed)是经过Hadamard变换之后的SAD)
//即编码代价
//p_src_by编码帧,p_dst_by重建帧
i_satd = h->pixf.mbcmp[PIXEL_4x4]( p_dst_by, FDEC_STRIDE, p_src_by, FENC_STRIDE ); ////////////////////计算SAD或者是SATD
if( i_pred_mode == x264_mb_pred_mode4x4_fix(i_mode) )
{
i_satd -= lambda * 3;
if( i_satd <= 0 )
{
i_best = i_satd;
a->i_predict4x4[idx] = i_mode;
break;
}
}
//COPY2_IF_LT()函数的意思是“copy if little”。即如果值更小(代价更小),就拷贝。
//宏定义展开后如下所示
//if((i_satd)<(i_best))
//{
// (i_best)=(i_satd);
// (a->i_predict4x4[idx])=(i_mode);
//}
//看看代价是否更小
//i_best中存储了最小的代价值
//i_predict4x4[idx]中存储了代价最小的预测模式(idx为4x4小块的序号)
COPY2_IF_LT( i_best, i_satd, a->i_predict4x4[idx], i_mode );
}
}
//累加各个4x4块的代价(累加每个块的最小代价)
i_cost += i_best + 3 * lambda;
if( i_cost > i_satd_thresh || idx == 15 )
break;
if( h->mb.b_lossless )
x264_predict_lossless_4x4( h, p_dst_by, 0, idx, a->i_predict4x4[idx] );
else
h->predict_4x4[a->i_predict4x4[idx]]( p_dst_by );
/*
* 将mode填充至intra4x4_pred_mode_cache
*
* 用简单图形表示intra4x4_pred_mode_cache如下。数字代表填充顺序(一共填充16次)
* |
* --+-------------------
* | 0 0 0 0 0 0 0 0
* | 0 0 0 0 1 2 5 6
* | 0 0 0 0 3 4 7 8
* | 0 0 0 0 9 10 13 14
* | 0 0 0 0 11 12 15 16
*
*/
h->mb.cache.intra4x4_pred_mode[x264_scan8[idx]] = a->i_predict4x4[idx];
}
/* we need to encode this block now (for next ones) */
x264_mb_encode_i4x4( h, 0, idx, a->i_qp, a->i_predict4x4[idx], 0 );
}
if( idx == 15 )//处理最后一个4x4小块(一共16个块)
{
//开销(累加完的)
a->i_satd_i4x4 = i_cost;
if( h->mb.i_skip_intra )
{
h->mc.copy[PIXEL_16x16]( h->mb.pic.i4x4_fdec_buf, 16, p_dst, FDEC_STRIDE, 16 );
h->mb.pic.i4x4_nnz_buf[0] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 0]] );
h->mb.pic.i4x4_nnz_buf[1] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 2]] );
h->mb.pic.i4x4_nnz_buf[2] = M32( &h->mb.cache.non_zero_count[x264_scan8[ 8]] );
h->mb.pic.i4x4_nnz_buf[3] = M32( &h->mb.cache.non_zero_count[x264_scan8[10]] );
h->mb.pic.i4x4_cbp = h->mb.i_cbp_luma;
if( h->mb.i_skip_intra == 2 )
h->mc.memcpy_aligned( h->mb.pic.i4x4_dct_buf, h->dct.luma4x4, sizeof(h->mb.pic.i4x4_dct_buf) );
}
}
else
a->i_satd_i4x4 = COST_MAX;
}
}
总体说来x264_mb_analyse_intra()通过计算Intra16x16,Intra8x8,Intra4x4这3中帧内预测模式的代价,比较后得到最佳的帧内预测模式。该函数的大致流程如下:
(1)、进行Intra16X16模式的预测
a)、调用predict_16x16_mode_available()根据周围宏块的情况判断其可用的预测模式(主要检查左边和上边的块是否可用)。
b)、循环计算4种Intra16x16帧内预测模式:
i.调用predict_16x16[]()汇编函数进行Intra16x16帧内预测
ii.调用x264_pixel_function_t中的mbcmp[]()计算编码代价(mbcmp[]()指向SAD或者SATD汇编函数)。
c)、获取最小代价的Intra16x16模式。
(2)、进行Intra8x8模式的预测
(3)、进行Intra4X4块模式的预测
a)、循环处理16个4x4的块:
i.调用x264_mb_predict_intra4x4_mode()根据周围宏块情况判断该块可用的预测模式。
ii.循环计算9种Intra4x4的帧内预测模式:
1)、调用predict_4x4 []()汇编函数进行Intra4x4帧内预测
2)、调用x264_pixel_function_t中的mbcmp[]()计算编码代价(mbcmp[]()指向SAD或者SATD汇编函数)。
iii.获取最小代价的Intra4x4模式。
b)、将16个4X4块的最小代价相加,得到总代价。
(4)、将上述3中模式的代价进行对比,取最小者为当前宏块的帧内预测模式。
![]() 此处帧内预测分析的较为简单,只是给出了大概,其实,想要具体的深入学会某一个算法就必须自己亲力亲为,将算法推导一下,再经过无数次编程调试、测试、验证才能最终转化为自己的知识。
此处帧内预测分析的较为简单,只是给出了大概,其实,想要具体的深入学会某一个算法就必须自己亲力亲为,将算法推导一下,再经过无数次编程调试、测试、验证才能最终转化为自己的知识。