Nutch2.3.1 新闻分类爬虫
Contents
- 项目介绍
- 配置文件
- 本地抓取
- 分布式环境配置
- 开发环境配置
- solr 4.10.3配置
- hadoop2.5.2安装部署
- 项目下载地址
- 联系作者
项目介绍
本项目基于https://github.com/xautlx/nutch-ajax.git,xautlx的nutch-ajax项目功能很强大,本项目在此基础上,对nutch-ajax项目做了一些精简和优化,对Nutch版本进行升级,引入Mybatis进行数据存储层处理,使用清华大学自然语言处理实验室推出的中文文本分类工具包来做文本分类的工作,形成一个可以对新闻进行分类的爬虫。在解决了一些jar包冲突问题后,使得本项目可以在ide、单机、伪分布式、完全分布式环境下都可以运行。对本项目中的训练模型文件进行替换,可以很容易实现一个分布式主题爬虫系统。对xautlx在我开发过程中提供的帮助在此一并谢过。
配置文件
下载下来代码后进入apache-nutch-2.3.1目录,项目默认的mongodb、mysql、solr都是本地配置的,如果不是在本地配置的,则需要修改配置文件。
mongodb的配置文件在conf/gora.properties中,如果mongodb不是在本地配置的,则把localhost换成mongodb所在机器的ip即可
############################
# MongoDBStore properties #
############################
gora.datastore.default=org.apache.gora.mongodb.store.MongoStore
gora.mongodb.override_hadoop_configuration=false
gora.mongodb.mapping.file=/gora-mongodb-mapping.xml
gora.mongodb.servers=localhost:27017
gora.mongodb.db=nutchFocuse
#gora.mongodb.login=login
#gora.mongodb.secret=secretmysql配置项在conf/mybatis-config.xml中,修改为你自己的mysql配置即可
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/nutchClassify"/>
<property name="username" value="lq"/>
<property name="password" value="123456"/>
</dataSource>solr的配置在conf/nutch-site.xml文件中,如果把“solr.server.url”属性配置为空,则不进行索引
<!--可基于Solr实际配置运行地址配置此参数-->
<property>
<name>solr.server.url</name>
<value>http://localhost:8080/solr</value>
</property>在conf目录下新增了svmmodel文件夹,主要用于存储THUCTC训练的分词模型。
新增crawl-data-mapper.xml文件,为mybatis的mapper.xml文件
新增mybatis-config.xml文件,用于配置mybatis的数据源
本地抓取
修改完配置后,直接ant clean,ant,第一次ant时间会很长,耐心等待就好

ant成功后如下图所示:
我设置的种子URL是一些与体育相关的主题新闻网站,urls/seed.txt文件内容如下
#新浪体育
http://sports.sina.com.cn/
#搜狐体育
http://sports.sohu.com/
#腾讯体育
http://sports.qq.com/
#网易体育
http://sports.163.com/
然后输入
lq-pcdeMacBook-Pro:apache-nutch-2.3.1 lq$ runtime/local/bin/crawl urls test 1开始本地抓取。抓取截图如下,开始抓取:

抓取结束:

最后打开solr界面可以查询到刚才添加的索引,通过设置查询条件可以对新闻的类别和内容进行索引,如下图所示:
不设置查询条件,查询所有记录

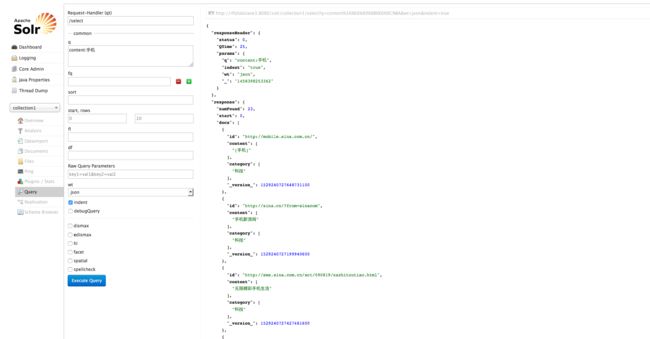
设置查询条件:content:手机
设置查询条件:category:财经
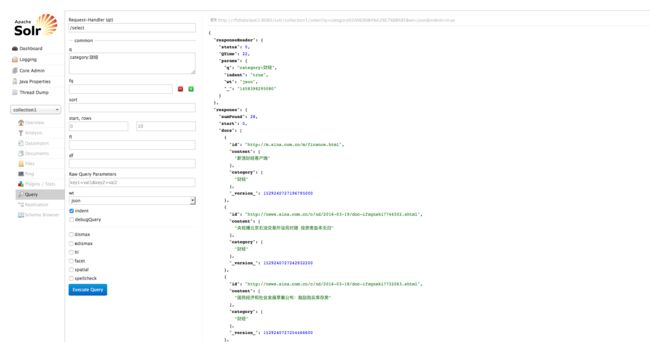
由于分类选择的语料(训练集)是新浪新闻RSS订阅频道2005~2011年间的历史数据,已经比较老了,所以用来对现在的新闻分类效果可能不是很好。具体可以参见THUCTC:http://thuctc.thunlp.org/
如果不需要使用索引,把conf/nutch-site.xml中的solr.server.url,设置为空即可抓取过程中,url使用mongodb存储,数据库配置参见apache-nutch-2.3.1/conf/gora.properties抓取的内容使用mysql存储,具体配置参见conf/nutch-site.xml文件以jdbc.开头的属性
mysql建表语句:
CREATE DATABASE nutchClassify DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
CREATE TABLE `crawl_data` ( `url` text NOT NULL, `content` varchar(255) NOT NULL, `category` varchar(45) NOT NULL, `fetch_time` varchar(45) NOT NULL, `id` varchar(255) NOT NULL, `relevance_score` double NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Mysql数据库截图,由于给的都是跟体育相关的优秀种子网站,所以分类效果还是很不错的。
分布式环境配置
如果网页的爬取过程中不需要ajax支持,那么直接运行是没有问题的,修改conf/nutch-site.xml中的plugin.includes属性使用nutch自带的插件protocol-http。每次修改配置文件后,需要重新ant打包。如果要支持ajax,就要对hadoop进行修改。因为selenium和htmlunit需要httpclient4.3,httpcore-4.3以上的版本,然而apach-nutch-2.3.1官方建议使用的是Apache Hadoop 1.2.1 and 2.5.2,这两个我都试过,用1.2.1需要修改更多的jar包,包括升级log4j等,不建议使用hadoop-1.2.1,目前我使用的是hadoop-2.5.2,它自带的是httpclient-4.2.5.jar,httpcore-4.2.5.jar,分布式环境运行的时候会加载hadoop-2.5.2/share/hadoop/common/lib这下面的jar包,这样会出现很多稀奇古怪的错误,由于我对hadoop本身没有任何研究,所以我索性将hadoop-2.5.2/share/hadoop/common/lib下的httpclient和httpcore进行升级,升级为对应selenium和htmlunit需要的httpclient和httpcore版本。
正如官网所说,建议所有的开发者和用户都升级到2.3.1,这点我很能理解,因为之前的2.3别说分布式了,就算是单机脚本都很难跑起来,bug多的飞起。
分布式抓取前首先把种子url目录加入hdfs
lq@RfidLabMaster:~/Nutch-NewsClassify/apache-nutch-2.3.1$ hdfs dfs -rm -r /urls/seed.txt运行分布式命令:
nohup runtime/deploy/bin/crawl /urls test 1 > crawlLog 2>&1 &一段时间后出现”Done”,表示执行完毕,也可以通过查看crawlLog文件看当前执行的情况
lq@RfidLabMaster:~/Nutch-NewsClassify/apache-nutch-2.3.1$
[1]+ Done nohup runtime/deploy/bin/crawl /urls test 1 > crawlLog 2>&1可以通过访问链接:http://rfidlabmaster:50070/logs/userlogs/ 来查询运行日志
开发环境配置
下载下来代码后进入apache-nutch-2.3.1目录,
修改配置文件,conf/nutch-site.xml把以下内容取消注释
<property>
<name>plugin.folders</name>
<value>./src/plugin</value>
</property>然后在该目录下执行ant clean,ant,ant eclipse,然后打开intellij idea import Project->选择apache-nutch-2.3.1目录->import project from external model(选择eclipse),之后一路next即可。
用idea打开工程后需要调整依赖顺序
1.前三个依赖顺序为conf,Module source,1.8(jdk)

2.将parse-lq调整到lucene开头的jar包之前

3.需要对哪个plugin进行开发,就选中plugin/src下的java文件夹,然后右键Mark Directory As –>Sources Root,完成以上步骤就可以开始愉快的进行开发了。
4.由于nutch2.x后取消了crawl类,我把crawl脚本“直译”成了一个java类来方便调试,org.apache.nutch.crawl.Crawl.java
solr 4.10.3配置
- 下载安装solr
在我的home目录(/home/lq)已经安装了apache-tomcat-8.0.29,在/home/lq目录下下输入
wget archive.apache.org/dist/lucene/solr/4.10.3/solr-4.10.3.tgz输出如下所示
[lq@lq-ALiYun ~]$ ls -l
总用量 40
drwxr-xr-x 9 lq lq 4096 2月 13 05:49 apache-tomcat-8.0.29
-rw-rw-r-- 1 lq lq 34420 3月 3 17:43 deploy.log
[lq@lq-ALiYun ~]$ pwd
/home/lq
[lq@lq-ALiYun ~]$ wget archive.apache.org/dist/lucene/solr/4.10.3/solr-4.10.3.tgz
--2016-03-18 21:13:08-- http://archive.apache.org/dist/lucene/solr/4.10.3/solr-4.10.3.tgz
正在解析主机 archive.apache.org (archive.apache.org)... 192.87.106.229, 140.211.11.131, 2001:610:1:80bc:192:87:106:229
正在连接 archive.apache.org (archive.apache.org)|192.87.106.229|:80... 已连接。
已发出 HTTP 请求,正在等待回应... 200 OK
长度:150010621 (143M) [application/x-tar]
正在保存至: “solr-4.10.3.tgz”
100%[====================================================================================================================================>] 150,010,621 46.2KB/s 用时 2h 36m
2016-03-18 23:49:25 (15.6 KB/s) - 已保存 “solr-4.10.3.tgz” [150010621/150010621])下载完成后
tar -zxvf solr-4.10.3.tgz
cp solr-4.10.3/example/webapps/solr.war ~/apache-tomcat-8.0.29/webapps/重新启动一次tomcat,在apache-tomcat-8.0.29/webapps/会生成一个solr文件夹,然后把刚才拷贝的war包删除
[lq@lq-ALiYun ~]$ ~/apache-tomcat-8.0.29/bin/startup.sh
[lq@lq-ALiYun ~]$ rm apache-tomcat-8.0.29/webapps/solr.war 修改~/apache-tomcat-8.0.29/webapps/solr/WEB-INF/web.xml文件中的以下内容,修改前:
<!--
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/put/your/solr/home/here</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
-->修改后
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/home/lq/solr-4.10.3/example/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>复制jar包
cp -r solr-4.10.3/example/lib/ext/. apache-tomcat-8.0.29/webapps/solr/WEB-INF/lib/然后访问
http://机器ip:8080/solr,如下图即安装成功
- 中文分词器
下载中文分词器 链接:http://git.oschina.net/wltea/IK-Analyzer-2012FF 下载玩后复制jar包和词典文件,如果没有classes文件夹就手动创建一个
cp IK-Analyzer-2012FF/dist/IKAnalyzer2012_FF.jar apache-tomcat-8.0.29/webapps/solr/WEB-INF/lib/
cp IK-Analyzer-2012FF/dist/IKAnalyzer.cfg.xml apache-tomcat-8.0.29/webapps/solr/WEB-INF/classes/
cp IK-Analyzer-2012FF/dist/IKAnalyzer.cfg.xml apache-tomcat-8.0.29/webapps/solr/WEB-INF/classes/修改solr-4.10.3/example/solr/collection1/conf/schema.xml配置文件,
添加分词器:
<!-- 自定义添加IK Analyzer 分词插件-->
<fieldType name="text" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>重启tomcat,重新进入solr界面,选择collection1->Analysis,Analyse Fieldname / FieldType选为text_ik,随便输入一句话,测试中文分词效果。如下图:
要使用本项目进行索引的话,还需要配置
<field name="fetch_time" type="string" indexed="false" stored="false" multiValued="true"/>修改content和category的属性如下
<field name="category" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<field name="content" type="text_ik" indexed="true" stored="true" multiValued="true"/>
<field name="relevance_score" type="double" indexed="true" stored="true" />如果solr默认的查找元素为text,则需要copyField到text上用于搜索
<copyField source="category" dest="text"/>
<copyField source="relevance_score" dest="text"/>修改配置后需要重启solr服务器 或者在网页上点击Core Admin->Reload按钮才能生效
要想删除索引,可以直接清除data目录下的内容
rm -r solr-4.10.3/example/solr/collection1/data/*hadoop2.5.2安装部署
Hadoop 2.5.2分布式集群配置:http://blog.csdn.net/lqleo323/article/details/50803799
项目下载地址
https://github.com/LQZYC/Nutch-NewsClassify
联系作者
- CSDN
All copyright reserved