Machine Learning 学习笔记Week3 (续)——如何避免overfitting
我们首先提出一个例子:对于下图,如何找出它的hypothesis function?
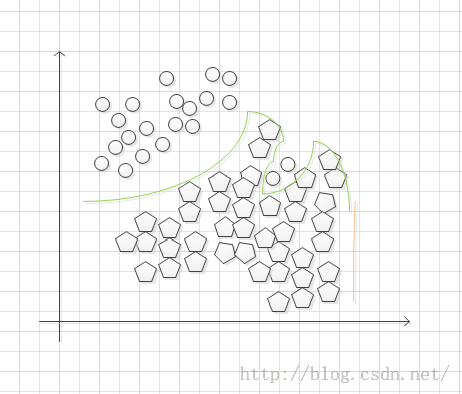
可以看到左图中分类曲线将五边形和圆完全分开了,右图中训练集数据全部在拟合的曲线上。虽然看起来,对于训练集数据来说,这种回归似乎接近百分之百正确,但是其hypothesis function如此的诡异。以至于,对于一个新的输入数据,预测其输出将会显得十分奇怪。这就是因为过拟合造成的原因。
Regularization就是用来解决Overfitting的问题的。
当hypothesis function进行拟合时,要么由于hypothesis function过于简单使用了太少的输入特征(1),而造成的high bias(高方差)也就是underfitting;要么就是由于训练时使用了太多的输入特征造成的太多不必要的和数据无关的弯曲和角度(3)形成了overfitting。这中hypothesis function虽然在样本训练集上表现的非常好,但是将其泛化到一般的输入时,不难想象其表现的非常差。
本文主要介绍如何使用Regularization解决overfitting的问题。
解决思路有两种:
1、减少特征数
a、人工选择需要保留的特征
b、使用模型自动选择需要保留的特征(后面的课程会有介绍的)
2、正则化(Regularization)
保留所有的特征,但是将它们的参数变小
当我们有很多稍微有用的特征时,正则化非常有效。
Cost Function
当hypothesis function遇到overfitting的问题时,我们可以通过增加其中一些项的cost从而减少这些项的权重。
也就是说:
如果我们想这个hypothesis function更接近于表现良好的二次函数,那么我们将会向消除和![]() 的影响,但是同时为了保留这些特征,我们可以修改我们的hypothesis function成如下形式:
的影响,但是同时为了保留这些特征,我们可以修改我们的hypothesis function成如下形式:
现在我们在cost function的末尾增加了额外的两项来加大![]() 和
和![]() ,现在为了使cost function接近0,我们必须减小
,现在为了使cost function接近0,我们必须减小![]() 和
和![]() 的值接近0,这样才能减小hypothesis function中和
的值接近0,这样才能减小hypothesis function中和![]() 的值。
的值。
通常我们采用以下形式以求和的形式正则化所有的参数:
其中被称为正则化参数,它决定了参数膨胀的cost。
显然不难想象,使用了正则化后,我们可以平滑hypothesis function减轻overfitting。但是不难想象,一旦lambda选择过大,那么hypothesis function被过度平滑,从而导致underfitting。
Regularized Linear Regression
梯度下降法:
我们将梯度下降法中的![]() 和其他的参数分离开来,进行不同的处理,由前面可知,
和其他的参数分离开来,进行不同的处理,由前面可知,![]() 一直是常数1因此我们不想对它进行惩罚。
一直是常数1因此我们不想对它进行惩罚。
其中项![]() 就体现了正则化。
就体现了正则化。
Normal Equation
求解线性回归的第二种方法就是Normal Equation来求解。
在正则化前,参数解为
![]()
正则化后,参数解为
L矩阵的大小为(n+1)*(n+1),同时,我们之前提过,当m<=n时,那么就不可逆,但是一旦我们加入![]() 后,它就变得可逆了。
后,它就变得可逆了。
Recularized Logistic Regression
使用的方法任然是梯度下降方法。
和线性回归相似:
未使用正则化前:
使用正则化惩罚参数后,同样的参数![]() 单独处理,不进行惩罚:
单独处理,不进行惩罚:
梯度下降法求解后:
不难发现,这个和线性回归中的结果是一样的。