machine learing week 10, 随机梯度下降 批量梯度下降 确定训练模型的数据规模 判断梯度下降是否收敛
1.1大型数据集的学习
如果我们有一个低偏差的模型,增加数据集的规模可以帮助你获得更好的结果。
我们应该怎样应对一个有100万条记录的训练集?
以线性回归模型为例,每一次梯度下降迭代,我们都需要计算训练集的误差的平方和,如果我们的学习算法需要有20次迭代,这便已经是非常大的计算代价。
首先应该做的事是去检查一个这么大规模的训练集是否真的必要,也许我们只用1000个训练集也能获得较好的效果,我们可以绘制学习曲线来帮助判断。
1、如何确定训练一个模型应该用多少训练数据呢?上亿,还是上千。
方法:画出该模型的代价函数关于训练数据规模的学习曲线。
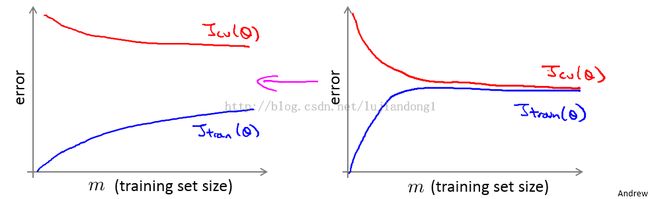
解释:如果画出的学习曲线是这中高方差的学习曲线,J_train(θ)是训练目标的学习曲线,Jcv(θ)是验证的学习曲线,那么,显然当训练规模增大时,验证的学习曲线会逼近训练目标的学习曲线。

解释:如果在m比较小时,验证的学习曲线就逼近训练目标的学习曲线,是属于高偏差的学习算法。那么再增加训练数据的规模就没什么用处了。此时,应该采取的策略是,增加特征,增加隐层的结点.....
让两天曲线由如下的右图变为左图:
1.2随机梯度下降法(Stochastic Gradient Descent)
如果我们一定需要一个大规模的训练集,我们可以尝试使用随机梯度下降法来代替批量梯度下降法。
在随机梯度下降法中,我们定义代价函数为一个单一训练实例的代价:

随机梯度下降算法为:
首先对训练集随机“洗牌”(对训练集进行随机排列,打散了),然后:

随机梯度下降算法在每一次计算之后便更新参数Θ,而不需要首先将所有的训练集求和,在梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但是这样的算法存在的问题是,不是每一步都是朝着“正确”的方向迈出的。因此算法虽然会逐渐走向全局最小值的位置,但是可能无法站到那个最小值的那一点,而是在最小值点附近徘徊。

1.3微型批量梯度下降(Mini-Batch Gradient Descent
微型批量梯度下降算法是介于批量梯度下降算法和随机梯度下降算法之间的算法,每计算常数b次训练实例,便更新一次参数Θ。

通常我们会令b在2-100之间。这样做的好处在于,我们可以用向量化的方式来循环b个训练实例,如果我们用的线性代数函数库比较好,能够支持平行处理,那么算法的总体表现将不受影响(与随机梯度下降相同)。
1.4随机梯度下降收敛(Stochastic Descent Convergence)
在批量梯度下降中,我们可以令代价函数J为迭代次数的函数,绘制图表,根据图表来判断梯度下降是否收敛。但是,在大规模的训练集的情况下,这是不现实的,因为计算代价太大了。
在随机梯度下降中,我们在每一次更新Θ之前都计算一次代价,然后每X次迭代后,求出这X次对训练实例计算代价的平均值,然后绘制这些平均值与X次迭代的次数之间的函数图表。
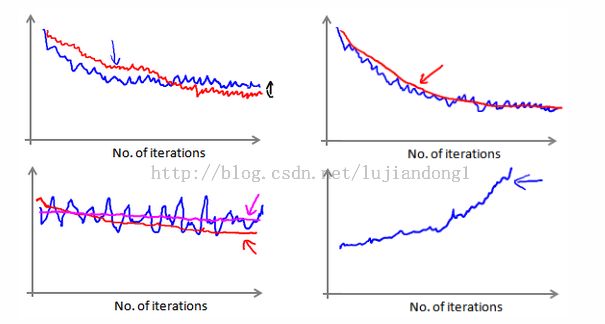
当我们绘制这样的图表时,可能会得到一个颠簸不平但是不会明显减少的函数图像(如上面左下图中蓝线所示)。我们可以增加X来使得函数更加平缓,也许便能看出下降的趋势了(如上面左下图中红线所示);或者可能函数图表仍然是颠簸不平且不下降的(如洋红色线所示),那么我们的模型本身可能存在一些错误。
如果我们得到的曲线如上面右下方所示,不断地上升,那么我们可能会需要选择一个较小的学习率α。
我们也可以令学习率随着迭代次数的增加而减小,例如令:
随着我们不断地靠近全局最小值,通过减小学习率,我们迫使算法收敛而非在最小值附近徘徊。
但是通常我们不需要这样做便能有非常好的效果了,对α进行调整所耗费的计算通常不值得。