7.7 赫夫曼树应用解析(叶子到根逆向求每个字符的赫夫曼编码)
赫夫曼树(Huffman):又称最优树,是一类带权路径长度最短的树。带权路径长度最小的二叉树称作
最优二叉树或赫夫曼树。
带权路径的计算:记做WPL是路径长度和节点上权的乘积。
构造赫夫曼树(四步骤):
1、n个权值{w1, w2,w3,…..wn}构造n棵二叉树的集合F{T1, T2, T3,…..Tn},其中每棵二叉树Ti中只有一个带权的根节点Wi,其左右子树均未空。
2、在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根节点的权值为其左、右子树上根结点的权值之和。
3、在F中删除这两棵树,同时将得到的二叉树加入F中。
4、重复(2)、(3),直到F中只含一棵树为止,这便是赫夫曼树。
注意点:
赫夫曼树中没有度为1的结点,一棵有n个子结点的赫夫曼树公有2n-1个结点。可以存储在一个大小为2n-1的一维数组中。
在构成赫夫曼树之后,力求编码从叶子结点出发走一条叶子到根的路径;
而译码从根出发走一条从根到叶子的路径。则对每个结点来说,既需知道双亲的信息,又需知道孩子的信息。
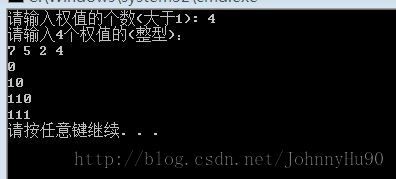
下面程序:
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 |
/***********************************************************/
// 程序名称:HuffmanTree.cpp // 程序目的:设计一个叶子到根逆向求每个字符的赫夫曼编码的程序 // 程序来源:数据结构与算法分析(C语言描述) P-147 // 日期:2013-8-26 21:22:19 /***********************************************************/ #include <stdio.h> #include <stdlib.h> #include <limits.h> #include <string.h> #define Error( str ) FatalError( str ) #define FatalError( str ) fprintf( stderr, "%s\n", str ), exit( 1 ) typedef int ElementType; #define MAXQUEUE 10 typedef struct huffmantree { unsigned int weight; // 权值 unsigned int parent, lchild, rchild; } HTNode, *HuffmanTree; // 动态分配数组存储赫夫曼树 typedef char* *HuffmanCode; // 动态分配数组存储赫夫曼编码表 int Min(HuffmanTree t, int i); void Select(HuffmanTree t, int i, int &s1, int &s2); void HuffmanTreeCoding(HuffmanTree &HT, HuffmanCode &HC, int *w, int n); /************************************************************************/ // 主程序 /************************************************************************/ int main( void) { HuffmanTree HT; HuffmanCode HC; int n; printf( "请输入权值的个数(大于1): "); scanf( "%d", &n); int* w; w = ( int*)malloc(n * sizeof( int)); printf( "请输入%d个权值的(整型): \n", n); for ( int i= 0; i <= n- 1; i++) scanf( "%d", w+i); HuffmanTreeCoding(HT, HC, w, n); for ( int i= 1; i <=n; i++) puts(HC[i]); return 0; } /************************************************************************/ // 获得totalNode个结点中权值最小的结点的序号 /************************************************************************/ int Min(HuffmanTree t, int totalNodes) { // 返回totalNodes个结点中权值最小的根结点序号 int minIndex = 0; unsigned int unWeight = UINT_MAX; // 无符号整型最大值 for ( int i= 1; i <= totalNodes; i++) { if (t[i].weight < unWeight && t[i].parent == 0) // t[i]为根结点 { unWeight = t[i].weight; minIndex = i; } } t[minIndex].parent = 1; // 给选中的根节点双亲赋1,避免第2次查找改点 return minIndex; } /************************************************************************/ // 选择权值最小的树的根结点的序号 /************************************************************************/ void Select(HuffmanTree t, int minIndex, int &minIndex1, int &minIndex2) { minIndex1 = Min(t, minIndex); minIndex2 = Min(t, minIndex); int tempIndex; if (minIndex1 > minIndex2) { tempIndex = minIndex1; minIndex1 = minIndex2; minIndex2 = tempIndex; } return; } /************************************************************************/ // 求解赫夫曼编码 /************************************************************************/ void HuffmanTreeCoding(HuffmanTree &HT, HuffmanCode &HC, int* w, int n) { // w存放n个字符的权值(均>0), 构造赫夫曼树,求出n个字符的赫夫曼编码HC if (n <= 1) return; int nNodes; // 总结点和 int nodeIndex; // 根结点序号 nNodes = 2 * n - 1; HT = (HuffmanTree)malloc( sizeof(HTNode) * (nNodes+ 1) ); // 0号单元未用 HuffmanTree pTree; pTree = HT+ 1; for (nodeIndex= 1; nodeIndex <= n; ++nodeIndex,++pTree, ++w) { pTree->weight = *w; pTree->parent = 0; pTree->lchild = 0; pTree->rchild = 0; } for ( ; nodeIndex <= nNodes; ++nodeIndex, ++pTree) (*pTree).parent = 0; // 创建赫夫曼树 int minIndex1, minIndex2; for (nodeIndex = n+ 1; nodeIndex <= nNodes; nodeIndex++) // 循环n-1次 { // 在HT[1~nodeIndexs-1]中选择parent为0且weight最小的两个结点,其序号分别为minIndex1,minIndex2 Select(HT, nodeIndex- 1, minIndex1, minIndex2); HT[minIndex1].parent = HT[minIndex2].parent = nodeIndex; HT[nodeIndex].lchild = minIndex1; HT[nodeIndex].rchild = minIndex2; HT[nodeIndex].weight = HT[minIndex1].weight + HT[minIndex2].weight; } // 从叶子到根逆向求每个字符的赫夫曼编码 HC = (HuffmanCode)malloc( (n+ 1)* sizeof( char*)); // 分配n个字符编码的头指针向量([0]不用) char* codingSize; codingSize = ( char*)malloc( sizeof( char) * n); // 分配求编码的工作空间 codingSize[n- 1] = '\0'; // 编码结束符 for (nodeIndex = 1; nodeIndex <= n; nodeIndex++) { // 逐个字符求赫夫曼编码 int pos; unsigned int c, f; pos = n - 1; // 编码结束位置 for (c=nodeIndex, f=HT[nodeIndex].parent; f != 0; c=f, f = HT[f].parent) { // 从叶子到根逆向求编码 if (HT[f].lchild == c) codingSize[--pos] = '0'; else codingSize[--pos] = '1'; HC[nodeIndex] = ( char*)malloc((n - pos) * sizeof( char)); // 为第i个字符编码分配空间 strcpy(HC[nodeIndex], &codingSize[pos]); // 从codingSize复制编码串到HC } } free(codingSize); // 释放工作区间 return; } |