RNNs学习总结
递归神经网络(recurrent neural networks,RNNs)
RNNs的应用主要有两个方面:(1)根据真实世界中发生的相似度对任意的句子进行评分,从而提供一种对语法和语义的正确性进行测量方法,这种模型可以用于机器翻译系统中。(2)预测下一个将要出现的文本,这个应用的价值相对较低。
一、RNNs介绍
在传统的神经网络中,常常假设输入(与输出)之间是互相独立的,然而这在很多应用中是不切实际的,比如要想预测下一个将要出现的文本,那么上下文的作用就不容忽视。RNNs的设计思想就是想要利用这种上下文之间连续的信息,RNNs中的recurrent的含义就是指它对序列中的每个元素都执行相同的任务,一个典型的RNNs和它的展开形式如下图所示。
其中,右边是左边的展开形式,这里假设x是输入的句子,Xt是第t个时刻的输入,假设句子采用的是one-hot vector编码形式。
【注:one-hot vector是NLP(自然语言编码)在单词的表示方法中最简单的一种编码形式,每个单词表示为一个向量,只有它本身对应的位置为1,其他位置均为0,这个表示方法的缺点很明显,向量的长度与要表示的所有单词的种类相同,如果新的单词来了向量还有调整,并且整个矩阵非常庞大,更重要的是,它没有办法建立起单词之间的关系。当然还有其他的表示方法,如word2Vec等,当然使用好的表示方法也可以提高RNNs的效率。】
St是隐含层第t个时刻的状态,计算公式为
其中f是一个非线性函数,如tanh、ReLU等。
Ot是第t个时刻的输出,如果要用RNNs预测下一个单词,可以使用softmax分类器,则此时的函数为
![]()
二、RNNs的运行流程
(1)采用一种编码形式对训练样本集进行编码表示,例如one-hot vector,得到输入输出的矩阵。如果此时算法的目的是预测下一个单词,那么对每一个样本word,它所对应的输出就是在这个句子中它紧邻的下一个单词。(这时有个问题,就是句子的第一个单词和最后一个单词分别没有输入与输出对应,此时可以采用的方式是专门设置两个值来表示句子开始和句子结束,例如,可以认为句子的第一个单词所对应的输入为0,句子的最后一个单词的输出为1。)
【注:在对收集的文本样本集进行处理是一个非常复杂的过程,包括对样本进行分词、将词语与编号进行对应、去掉稀有词汇等,这里不再赘述。】
(2)初始化U、W、V,对RNNs进行前向传播训练,公式如下。
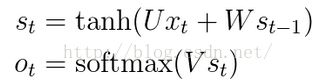
(3)根据预测值和真实值得到损失函数loss。一种常用的损失函数是cross-entropyloss,假设真实输出为y,预测为o,一共含有N个训练样本,则损失函数为
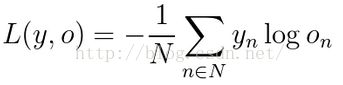
(4)根据损失函数,使用SGD和Backpropagation Through Time (BPTT)对网络进行训练,注意这里不是简单地使用BP算法,因为每一步输出的梯度不仅与当前的计算有关,还与之前的步骤有关。BPTT在RNNs中起到了非常重要的作用,介绍可以点击这里)
三、RNNs的特点
从以上分析可以看出:
(1)RNNs在前向传播的每个步骤中进行的是完全相同的计算步骤,只是输入改变了而已,因此这大大减少了需要学习的参数。
(2)RNNs在计算当前步骤的输出时,和以前的计算也有关,因此RNNs依赖于过去抓取的特征,因此它能学习到单词前后之间的序列的关联性。
(3)RNNs只能关联之前的步骤,而对于几个步骤之前的单词就无法学习到它们之间的联系,因此RNNs并不能综合概况产生特别有意义的文本,这也就限制了它的发展。
(4)BPTT具有消失梯度(vanishing gradient problem)的问题,W矩阵恰当的初始化可以减轻消失梯度的影响,还有一个较好的方法是用ReLU来代替tanh或者sigmoid函数。
【注:消失梯度问题在2013年的文章《On the difficulty of training recurrent neural networks》中有详细介绍,里面也谈到算法中也有膨胀梯度(exploding gradient problem)的问题,不过可以采用预定义的门槛剪辑梯度的方法来解决膨胀梯度问题,因此不再以此为重点。文章的下载的网址点击这里】
在RNNs的改进算法中,LSTM和GRU算法可以很好的解决消失梯度的问题,并能有效地学习到更长范围的关联性,这两种算法目前的发展较为关注。四、RNNs的改进算法
1、Bidirectional RNNs (双向RNNs网络)
文章:《Bidirectional Recurrent Neural Networks》
BRNNs的设计思想是在时间t的输出不仅仅与序列中之前的元素的有关,还与后面的元素有关。例如在预测一个句子中缺失的值时,要综合考虑前面和后面的文本。BRNNs的结果非常简单,如下图所示,它就像是两个RNNs叠加在一起组成的。它的输出是由两个RNNs的隐含层共同决定的。BRNN的结构使得它能够同时在两个时间方向上对网络进行训练,BRNNs的训练时间与其他RNNs的改进算法不相上下,BRNNs不需要对数据分布进行明确的假设,就可以有效的预测整个符合序列的条件后验概率。
2、Deep (Bidirectional)RNNs
文章:《SPEECH RECOGNITION WITH DEEP RECURRENT NEURAL NETWORKS》
Deep RNNs与BRNNs的结构相似,只是在每个步骤中含有多个层,在实践中,这提供了一个更高的学习能力,但同时也需要大量的训练数据。它的结构如下图所示。
3、LSTM Networks(Long Short Term Memory networks)
文章:《LONG SHORT-TERM MEMORY》
介绍比较详细的一个网址:点击打开链接
LSTMs在结构上与RNNs没有特别的不同,但它使用了不同的函数来计算隐层的状态,它比RNNs出色的地方在于它具有学习到“long-term dependencies”的能力。
简单地来说,传统的RNNs的结构是下图这样的:
LSTMs的结构是这样的:
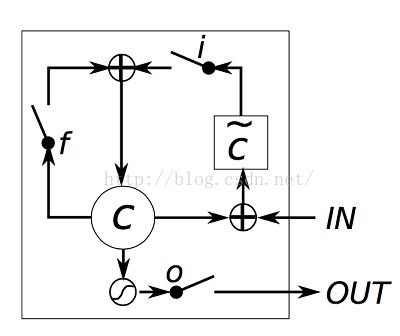
图中的标记含义为:

从中可以看出,LSTMs只是将其中的计算函数进行了改进,若对于应用层面来讲,只需要将整个计算过程视为是一个黑盒,只关心其输入输出和需要设置的参数就可以,若对于研究内部机理的层面来讲,可以参考上面提供的网址。
LSTMs的黑盒内的计算公式如下所示。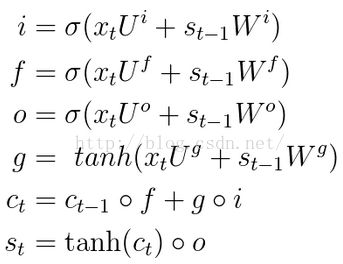
LSTM中的门槛设置:
4、GRU(Gated Recurrent Unit Recurrent Neural Networks)
文章:《Learning Phrase Representations using RNN Encoder–Decoder forStatistical Machine Translation》
GRU的设计思想与LSTM的很像,只是计算公式不同:
GRU含有两个门槛,一个重置门槛r和一个更新门槛z,r决定了如何将新到来的输入与之前的相结合,z定义了之前的计算如何保持。如果将r设置为全1而z甚至为全0,那GRU就变成了最普通的RNNs。
GRU中的门槛设置:
对于LSTMs和GRU的区别可以参考文章:《Empirical Evaluation of GatedRecurrent Neural Networks on Sequence Modeling》
五、RNNs的应用领域
RNNs被广泛应用于NLP任务中,其中应用最为广泛的是LSTMs算法。RNNs在NLP中的应用主要有以下几个方面:
(1)LanguageModeling and Generating Text
下面是相关的三篇文章:
《Recurrent neuralnetwork based language model》
《Extensions ofRecurrent neural network based language model》
《Generating Textwith Recurrent Neural Networks》
(2)MachineTranslation
机器翻译就是将一种语言的语句翻译为另外一种语言的语句。与语言建模不同的是,它是在句子完全输入之后才开始进行。
下面是相关的文章:
《A RecursiveRecurrent Neural Network for Statistical Machine Translation》
《Sequence toSequence Learning with Neural Networks》
《Joint Languageand Translation Modeling with Recurrent Neural Networks》
(3)SpeechRecognition
语音识别是指当输入一个声波的声音信号序列,可以预测出一系列的语音片段和它们对应的概率值。
下面是相关的文章:
《TowardsEnd-to-End Speech Recognition with Recurrent Neural Networks》
(4)GeneratingImage Descriptions
RNNs已经和CNN一起被用来对无标签的图片添加描述,可以查看网站:点击打开链接
