启动Hadoop和运行一个Mapreduce的hello world
格式化之后的hadoop,看到jps里面有namenode,datanode【分别是HDFS的老大和小弟】,ResourceManager,Nodemanager【YARN的老大和小弟】,Secondarynode【是老大的秘书】
启动hadoop
start-all.sh 【前面加上./】
里面说this script is deprecated 这个脚本已经过时了,下一次请启动别的 所以,我们倾向于不输入这个,而是分别输入start-dfs.sh和start-yarn.sh来替代它
(有个小问题,需要多次输入密码)
验证集群是否启动成功
jps(不包括jps应该有5个)
NameNode
SecondaryNameNode
DataNode
ResourceManager
NodeManager
还可以通过浏览器的方式验证
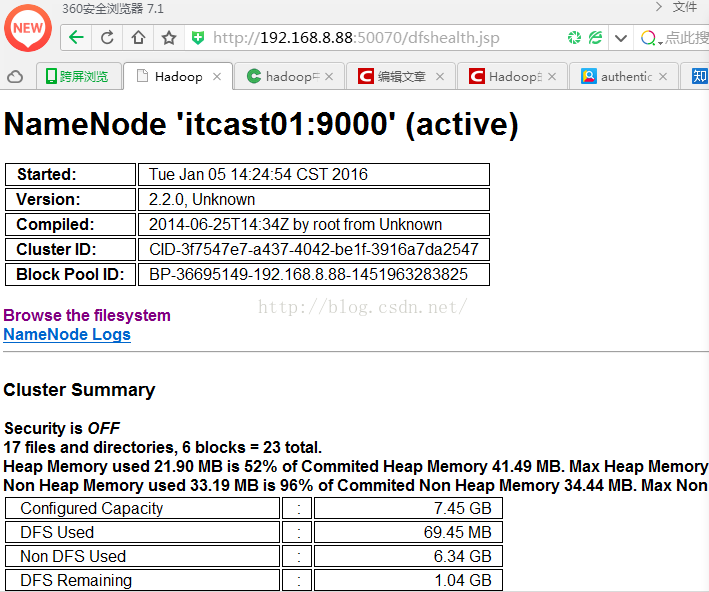
http://192.168.8.88:50070 (hdfs管理界面)
http://192.168.8.88:8088 (mr,YARN管理界面)

在此时,我发现jps里面只有四个【并不是5个】,没有namenode那个项。然后我百度了下,从百度知道里看到这么一句话,
提示都说了,不建议使用这个脚本,使用start-dfs.sh和start-mapred.sh来替代它。这说明脚本的作者或者维护人也觉得这个脚本可能有问题……
你要是有兴趣也可以自己改改……
于是,我发现我分别启动他推荐的那两个,奇迹般地namenode那一项就成功了
在浏览器中能打开看到hadoop让我觉得是一件非常神奇的事情,我在主机的浏览器上可以看到hadoop的进程,
在这个文件中添加linux主机名和IP的映射关系
C:\Windows\System32\drivers\etc
说明一下:这里更改txt文件是无法保存、更改的,需要先右键——属性之后,更改管理txt的权限之后,才能更改和保存。另外,无论是64位还是32位,都在这里更改
测试HDFS
1.上传文件到HDFS
hadoop fs -put /mnt/hgfs/share/jdk-6u45-linux-x64.bin 【此处有空格】hdfs://itcast01:9000/jdk
2.从HDFS下载文件【这里HDFS有点儿像一个网盘啊,可以输入代码来下载,也可以在Windows上直接点击download来下载】
hadoop fs -get hdfs://itcast01:9000/jdk /home/jdkdownload get后面两个,第一个是下载的文件的位置,第二个是保存的位置【如果没有将自动创建】
测试MapReduce和YARN
原话:测试一个类似于大数据里的“hello,world”的程序,就是run一下mapreduce里的wordcount,
hadoop jar hadoop-mapreduce-examples-2.2.0.jar wordcount hdfs://itcast01:9000/words hdfs://itcast01:9000/wcout
wordcount 后面两个分别跟的是前后两个地址,一个是我们要count的文件要查的地址,后面那个是我们保存的地方的地址
这两个最后在浏览器中都可以打开。
点进去那个part-r-0000便是Wordcount的结果
