【3-4】hadoop序列化
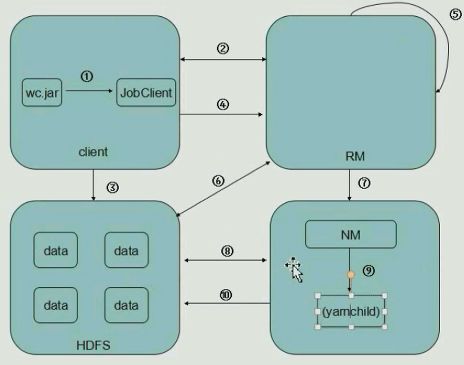
①客户端提交一个mapreduce的jar包给JobClient;②JobClient通过RPC通信(得到RM里进程的代理对象)发送一个请求给RM,告诉RM,我要提交一个mapreduce任务,RM给你个ID,再给你个存放jar包的路径(前缀)。客户端拿到这两个信息,将老大给他的存放jar包的路径作为前缀,将jobID作为后缀,将这两个路径拼接起来,作为一个唯一确定的存放jar包的路径。【为了避免重复】③client得到这个路径之后,有FileSystem工具类,将jar包写入到HDFS里了,【HDFS压力不大的原因是因为它写了3份(其实是10份),nodemanager小弟去读取数据时压力不大】。
④现在,客户端把jobID,和jar包存放的地址(和一些配置信息)通过RPC方法再提交给RM,⑤RM接受到你的信息了(保存的是这个作业的描述信息),之后,把信息初始化,再把这个任务详情放在它的调度器里面。(有先进先出调度器,是一个队列【这是hadoop默认调度器】;还有公平调度器,第一个任务执行一会儿,第二个任务执行一会儿。。以此类推)。
⑥RM看一眼数据量多大,决定起多少个mapper和多少个reducer,mapper的数量由数据量决定的(inputsplit),然后把任务放在调度器里面。
⑦之后,小弟通过心跳机制来申请任务,⑧领到任务之后,跑到HDFS来下取jar包,之后,⑨NM会另外启动一个子进程Java进程yarnchild(独立于NM,运行map task【读取hdfs数据,解析成新的key,value之后再交给reduce任务,reduce计算完成后⑩再写回hdfs】,再运行reduce task)
以上是mapreduce的原理。接下来,讲序列化

Q:为什么hadoop没有用默认的jdk序列化机制?
A:比如我们有一个抽象类animal,有一个子类monkey,monkey继承了animal,animal有许多属性,比如年龄,等等,monkey里面也有许多属性,monkey里面也有一些animal的属性,如果我用jdk里面的序列化,我应该monkey = m new monkey();然后把这个monkey通过object outputstream,可以把这个对象写入到一个文件里,这个文件既保存了monkey的属性又保存了animal的属性,还保存了它的继承结构。现在相当于我把它序列化写入到磁盘了,但是如果我们反序列化之后,还是一个monkey对象,它还保存着这种继承对象【animal的子类】。而我们hadoop,我们不需要保存这种继承结构,很冗余,我们只需要数据进行传递,因此没有使用jdk的序列化机制,用hadoop自己的序列化机制,可以快速读写。
序列化:对象放在内存里面,然后写入到一个字节流里面。
反序列化:将字节流【误?】里面的内容读出来给对象赋值。
hadoop序列化特点:
紧凑;快速,因为功能少,占用空间小;可扩展(以前写的程序不用变,接口就可以);互操作(支持多种语言);
hadoop的序列化格式:Writable(我们写Wordcount的时候,有个Long Writable)
我们要Long Writable它实现了什么,在eclipse里面找到之前写过的某一个LongWritable类,按住Ctrl点进去,即可看到类的源码,可以看到,
![]()
longwritable实现了Writablecomparable,既可序列化也可比较,
这个Writablecomparable接口继承了Writable和comparable的接口,
comparable接口是Java.lang里的,
Writable是一个接口,定义了两个方法,一个是write,一个是readFields
以前我们都用Long Writable,Text,现在我们自己定义一个
我们写一个程序:一个手机号在一段时间内产生了多少流量。