MapReduce中的分区方法Partitioner
问题导读:
1.Partitioner分区类的作用是什么?
2.getPartition()三个参数分别是什么?
3.numReduceTasks指的是设置的Reducer任务数量,默认值是是多少?
扩展:

1.Partitioner分区类的作用是什么?
2.getPartition()三个参数分别是什么?
3.numReduceTasks指的是设置的Reducer任务数量,默认值是是多少?
扩展:
如果不同类型的数据被分配到了同一个分区,输出的数据是否还是有序的?
在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中;按照性别划分的话,需要把同一性别的数据放到一个文件中。我们知道最终的输出数据是来自于Reducer任务。那么,如果要得到多个文件,意味着有同样数量的Reducer任务在运行。Reducer任务的数据来自于Mapper任务,也就说Mapper任务要划分数据,对于不同的数据分配给不同的Reducer任务运行。Mapper任务划分数据的过程就称作Partition。负责实现划分数据的类称作Partitioner。
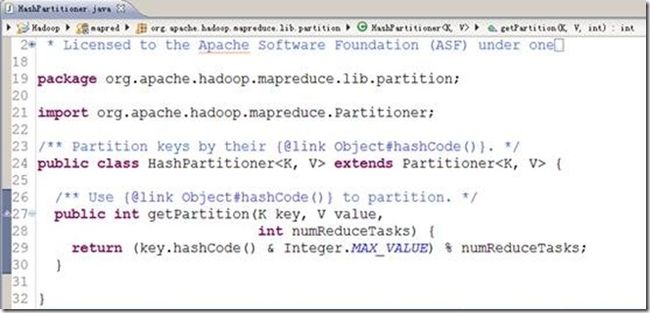
在我们前面讲过的例子中,始终没有提到分区,那是因为框架内置了分区类,称作HashPartitioner。我们看一下源码,如图6-6
图6-6
在图6-6中,HashPartitioner是处理Mapper任务输出的,getPartition()方法有三个形参,key、value分别指的是Mapper任务的输出,numReduceTasks指的是设置的Reducer任务数量,默认值是1。那么任何整数与1相除的余数肯定是0。也就是说getPartition(…)方法的返回值总是0。也就是Mapper任务的输出总是送给一个Reducer任务,最终只能输出到一个文件中。
据此分析,如果想要最终输出到多个文件中,在Mapper任务中对数据应该划分到多个区中。那么,我们只需要按照一定的规则让getPartition(…)方法的返回值是0,1,2,3…即可。
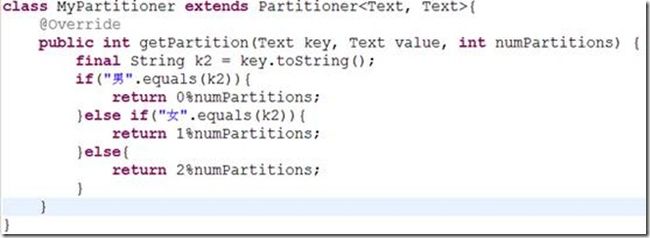
假设我们按照性别分区,那么可以覆盖Partitioner类的getpartition(…)方法,代码如图6-7
图6-7
在图6-7中,我们分别使用0、1、2与numPartitions相除。如果想把数据分到三个不同的输出中,意味着numPartitions的值是3。这样,0%3、1%3、2%3的值才是三个不同的。那么,我们怎么使用哪?只需要在驱动中进行两个操作即可,如图6-8
图6-8
在图6-8中,我们使用了自定义的分区类,并且制定了numReduceTasks。这里的numReduceTasks在内部就把值赋给了分区类中形式参数numPartitions。