【CS231n Winter 2016】
lecture 1

cs131,计算机视觉本科课程,导论。
cs231a,计算机视觉研究生课程,涵盖CV更加广的知识(cs231n主要是vision recognition/image classification) 有志CV者建议学习
cs231n,主要讲CNN用于image classification
历史就不多扯了。。说是几百万年前生物视觉的诞生大幅促进了进化过程,因为捕食者有了眼睛会追,被捕食者有了眼睛会跑blablabla。。。
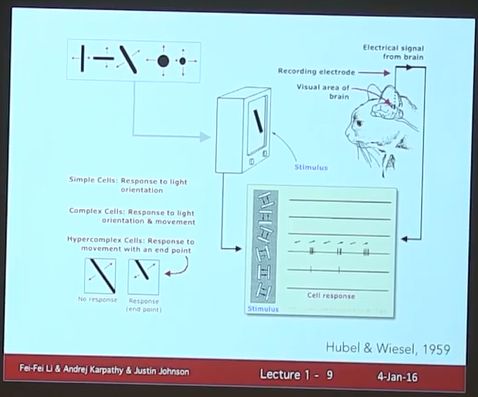
哈佛大学两个人对猫做的实验(nobel prize),意外发现当切换图片时,猫的脑视觉会兴奋,说明V1对边缘和边缘orientation敏感。

1963年,Larry Roberts认为边缘才是关键所在,正是边缘(即使颜色或者方位变化)决定了物体的外形。 他的PhD论文正是关于此,是CV的先驱性的文章
 、
、
但是CV的正式诞生应该是在1966年,当时MIT AI lab(1960’s 早期成立的两个AI实验室,一个是Marvin Minsky创立于MIT,另一个是John McCarthy(麦卡锡,同时也是AI一词的发明者)创立于斯坦福)的一个教授觉得应该用一个夏天来解决计算机视觉的问题了。此处被李飞飞吐槽了,想用一个summer project来解决CV的问题。。
2016年是CV的50岁生日了!

另一个需要记住的人是David Marr(下图)
Huber&Wiesel(1959, Harvard)告诉我们视觉很简单,就是边缘;
David Marr(1970s)则告诉我们人类的视觉系统应该有不同的stages/layers,最终生成复杂的视觉。

David Marr并没有指出类似这种视觉系统的数学模型,但是它的这种stages的思想最终被Deep Learning/CNN所汲取。
此后,循着3D视觉的构造,第一波vision algorithm wave来了。。介绍了几个代表性的工作:
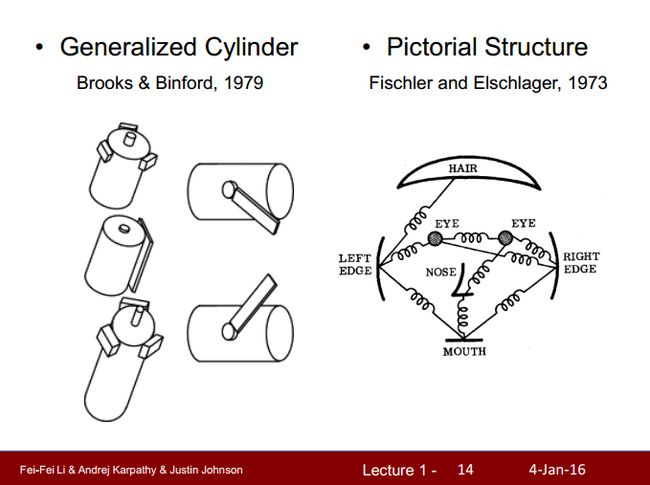
Brooks(1979)认为三维的物体都是由简单的物体(比如圆柱体等)组合来的;Fischler(1973)认为。。。那图啥意思?
再下面这个图,飞飞说是当时很有代表性的一个工作,全文都是使用很简单的edges和shapes来识别物体,用来表明之前的CV确实非常原始。

此后,90年代终于步入彩色图片时代,当时非常非常有影响力的工作不是 how to recognize an object,而是carve out images into sensible parts(举的例子是比如说人一走进教室,看到的不是一堆像素,而是会在人脑中“分割”出黑板,椅子,人头等等,这些sensible parts)
在CV中也被成为perceptual grouping, 是CV,生物学,AI中很基础的问题,至今仍未很好的解决。

下面这个是第一个商用的CV算法real-time face detection,2006年用到了照相机中。

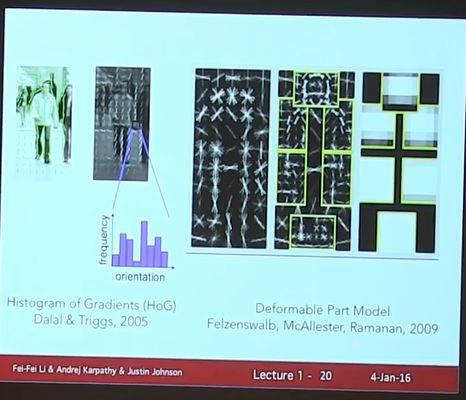
人脸检测之后,另一项工作(SIFT),意思是想要recognize an object,不是非得看到全部,一些关键的parts/features足以使得推断整个物体。事实上当今的DL之所以强大也是因为它学到的features和人类专家设计出的features非常相似。所以这个工作不应被遗忘

almost last model before DL:Deformable Part Model,通过描述每一部分和部分间的位置关系来表示物体
为了领域的发展,需要benchmark, 最知名之一是欧洲的PASCAL VOC

但是20类终归太少,于是Imagenet诞生了!

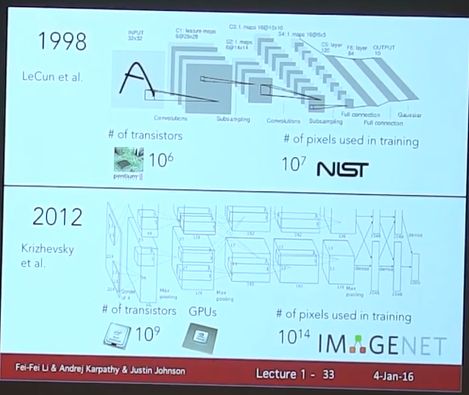
从下图可以看到2012年的惊人提升,正是CNN横空出世之时!(纠正一下,CNN上世纪就诞生了,但是并未大红大紫)

540million的历史就讲到这里。。下面讲课程大纲

cs231n专注于image classification
特别强调了vision recognition并非就是image classification,见下图用语的逻辑,事实上image classification是vision recognition的主要部分,许多vision recognition task都会涉及到,但是除此之外vision recognition还包括了3D modeling,perceptual grouping,segementation…


CNN has become an important tool for object recognition.
从2012年横空出世,2015年ImageNet的冠军MSRA仍然采用了CNN

But, CNN is not invented overnight!
First person who should be remembered is Kunihiko Fukushima who built the neocognitron.
(The neocognitron is a hierarchical, multilayered artificial neural network proposed by Kunihiko Fukushima in the 1980s. It has been used for handwritten character recognition and other pattern recognition tasks, and served as the inspiration for convolutional neural networks. -wiki)
Yann Lecun也是一个很有影响力的科学家,(飞飞说她觉得)他最重要的成果发表于1998年,正值他的导师Hinton发明了反向传播学习算法(如果我没听错的话。。。)他当时工作于Bell lab, which is an amazing place.致力于recognize digits/zip codes
而2012年,在更大的数据驱动以及更强的计算资源的支撑下,Hinton及其学生引领了DL的复兴。
最后再强调一下: The quest for visual intelligence goes far beyond object recognition. There are still lots of cool things leaved to be solve..
For examples, (左上角图)dense labeling of entire scene with perceptual grouping…
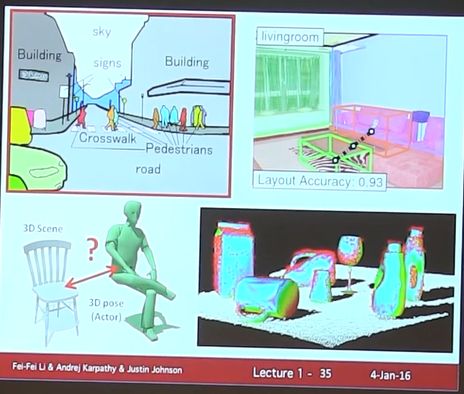
然后,给出下面这幅图是想说,有时候CV不仅仅限于给物体打标签,还会想理解图片中的人在干什么,各个物体之间有什么联系(飞飞表示他们实验室正在做这方面工作)。。


最后,介绍教师团队!

讲到授课理念

怎么给成绩,也贴一下。。

前修要求:

下课咯。。本讲结束!
Lecture 2
上一讲结束后,李飞飞就回家生孩子了。这一讲是Andrej Karpathy讲
语速较快,不过听着还行,当练练听力。
上来就说先把image classifier给搞定了,然后各种渲染classifier is a challengeable task. 举的是猫的例子,在不同的照片角度,光照,猫的姿态,品种等各种“干扰”下,分类器都应该robust. 贴一个图来体会体会,我也是醉了。。

但是现在的分类器已经能够又快又好地解决这个问题了,精度不亚于人类,这节课就来学习。对于image classifier前人已颇有建树,但是需要feature engineering

这节课要学的东西(data-driven算法)则很好的解决了这个麻烦的feature engineering的问题

第一个分类器,KNN

计算距离的方法:
