原文地址:http://zhangliliang.com/2014/09/13/paper-note-sppnet/
对应的论文是:http://arxiv.org/pdf/1406.4729v2.pdf
对应的slide:http://research.microsoft.com/en-us/um/people/kahe/eccv14sppnet/sppnet_ilsvrc2014.pdf
作者Kaiming He的主页:http://research.microsoft.com/en-us/um/people/kahe/
思路概述
如下图所示,由于传统的CNN限制了输入必须固定大小(比如AlexNet是224x224),所以在实际使用中往往需要对原图片进行crop或者warp的操作
- crop:截取原图片的一个固定大小的patch
- warp:将原图片的ROI缩放到一个固定大小的patch
无论是crop还是warp,都无法保证在不失真的情况下将图片传入到CNN当中。
- crop:物体可能会产生截断,尤其是长宽比大的图片。
- warp:物体被拉伸,失去“原形”,尤其是长宽比大的图片

Sptial Pyramid Pooling,以下简称SPP,为的就是解决上述的问题,做到的效果为:不管输入的图片是什么尺度,都能够正确的传入网络。
思路很直观,首先发现了,CNN的卷积层是可以处理任意尺度的输入的,只是在全连接层处有限制尺度——换句话说,如果找到一个方法,在全连接层之前将其输入限制到等长,那么就解决了这个问题。
然后解决问题的方法就是SPP了。
从BoW到SPM
SPP的思想来源于SPM,然后SPM的思想来源自BoW。
关于BoW和SPM,找到了两篇相关的博文,就不在这里展开了。
第九章三续:SIFT算法的应用—目标识别之Bag-of-words模型
Spatial Pyramid 小结
最后做到的效果如下图:
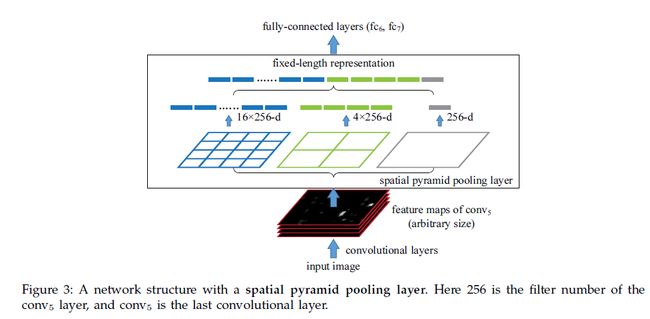
如果原图输入是224x224,对于conv5出来后的输出,是13x13x256的,可以理解成有256个这样的filter,每个filter对应一张13x13的reponse map。
如果像上图那样将reponse map分成4x4 2x2 1x1三张子图,做max pooling后,出来的特征就是固定长度的(16+4+1)x256那么多的维度了。
如果原图的输入不是224x224,出来的特征依然是(16+4+1)x256
直觉地说,可以理解成将原来固定大小为(3x3)窗口的pool5改成了自适应窗口大小,窗口的大小和reponse map成比例,保证了经过pooling后出来的feature的长度是一致的
如何训练网络
理论上说,SPP-net支持直接以多尺度的原始图片作为输入后直接BP即可。实际上,caffe等实现中,为了计算的方便,输入是固定了尺度了的。
所以为了使得在固定输出尺度的情况下也能够做到SPP-net的效果,就需要定义一个新的SSP-layer
作者以输入224x224举例,这时候conv5出来的reponse map为13x13,计算出来的步长如下图所示。

具体的计算方法,看一眼2.3的Single-size training部分就明白了。
如果输入改成180x180,这时候conv5出来的reponse map为10x10,类似的方法,能够得到新的pooling参数。
两种尺度下,在SSP后,输出的特征维度都是(9+4+1)x256,之后接全连接层即可。
训练的时候,224x224的图片通过随机crop得到,180x180的图片通过缩放224x224的图片得到。之后,迭代训练,即用224的图片训练一个epoch,之后180的图片训练一个epoth,交替地进行。
如何测试网络
作者说了一句话:Note that the above single/multi-size solutions are for training only. At the testing stage, it is straightforward to apply SPP-net on images of any sizes.
笔者觉得没有那么简单吧,毕竟caffe对于test网络也是有固定尺度的要求的。
实验
之后是大量的实验。
分类实验
如下图,一句话概括就是,都有提高。
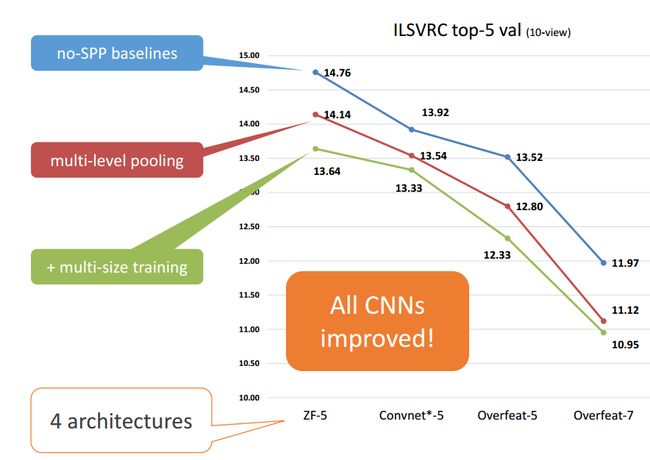
一些细节:
- 为了保证公平,test时候的做法是将图片缩放到短边为256,然后取10crop。这里的金字塔为{6x6 3x3 2x2 1x1}(笔者注意到,这里算是增加了特征,因为常规pool5后来说,只有6x6;这里另外多了9+4+1个特征)
- 作者将金字塔减少为{4x4 3x3 2x2 1x1},这样子,每个filter的feature从原来的36减少为30,但依然有提高。(笔者认为这个还是保留意见比较好)
- 其实这部分的实验比较多,详见论文,不在这里写了。
- 在ILSVRC14上的cls track,作者是第三名
定位实验
这里详细说说笔者较为关心的voc07上面的定位实验
用来对比的对象是RCNN。
方法简述:
- 提取region proposal部分依然用的是selective search
- CNN部分,结构用的是ZF-5(单尺度训练),金字塔用了{6x6 3x3 2x2 1x1},共50个bin
- 分类器也是用了SVM,后处理也是用了cls-specific regression
所以主要差别是在第二步,做出的主要改进在于SPP-net能够一次得到整个feature map,大大减少了计算proposal的特征时候的运算开销。
具体做法,将图片缩放到s∈{480,576,688,864,1200}的大小,于是得到了6个feature map。尽量让region在s集合中对应的尺度接近224x224,然后选择对应的feature map进行提取。(具体如何提取?后面的附录会说)
最后效果如图:

准确率从58.5提高到了59.2,而且速度快了24x
如果用两个模型综合,又提高了一点,到60.9

附录
如何将图像的ROI映射到feature map?
说实话,笔者还是没有完全弄懂这里的操作。先记录目前能够理解的部分。
总体的映射思路为:In our implementation, we project the corner point of a window onto a pixel in the feature maps, such that this corner point (in the image
domain) is closest to the center of the receptive field of that pixel.
略绕,我的理解是:
- 映射的是ROI的两个角点,左上角和右下角,这两个角点就可以唯一确定ROI的位置了。
- 将feature map的pixel映射回来图片空间
- 从映射回来的pixel中选择一个距离角点最近的pixel,作为映射。
如果以ZF-5为例子,具体的计算公式为:

这里有几个变量
- 139代表的是感受野的直径,计算这个也需要一点技巧了:如果一个filter的kernelsize=x,stride=y,而输出的reponse map的长度是n,那么其对应的感受野的长度为:n+(n-1)*(stride-1)+2*((kernelsize-1)/2)

- 16是effective stride,这里笔者理解为,将conv5的pixel映射到图片空间后,两个pixel之间的stride。(计算方法,所有stride连乘,对于ZF-5为2x2x2x2=16)
- 63和75怎么计算,还没有推出来。。。。囧