BOF——Bag-of-Featrures
本文主要介绍:BOF(Bag-of-Featrures)的原理及其应用。
1.1 引言
文档分类领域有一种模型称为词袋(Bag of words)模型,它是自然语言处理与信息检索过程中的一种简化模型。在这种模型中,文本(段落或文档)被视为忽略了语法甚至语序的无序词汇集合。文本中每个单词的出现都是独立的,不依赖于其他词是否出现。词袋模型对文档分类有着重要的作用,它提出了一种基于统计的文档描述思想,这种思想首先将训练集文档中的词汇进行训练,产生含有独一无二的单词的字典。然后使用字典对目标文档进行处理,统计字典中单词在文档中出现的频率,以此构建出能够描述整个文档的描述向量(注:其中,与主题相关的词一般在文档中出现频率较高,因此可以根据词的频率,对文档进行归类)。之后就可以在此向量基础上对文档进行检索或分类操作。词袋模型虽然简单,但是高效。在文本分类中,词袋模型与 SVM 分类器、朴素贝叶斯分类器结合能得到非常好的分类效果。
1.2 算法原理
图像可以视为一种文档对象,图像中不同的局部区域或其特征可看做构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,就能够把文本检索及分类的方法用到图像分类及检索中去。
Bag-of-Features模型仿照文本检索领域的Bag-of-Words方法,把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心被看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看当为一种特征量化过程,可理解为:码字表示聚类中心的特征矢量,如该类的平均矢量等)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),对应一个码书(code book)(可理解为:码书是所有聚类中心特征矢量的集合),即码字的集合,词典中所含词的个数反映了词典的大小。
图像中的每个特征都将被映射到视觉词典的某个词上,这种映射可以通过计算特征间的距离去实现,然后统计每个视觉词的出现次数或频率,图像可描述为一个维数相同的直方图向量,即Bag-of-Features,如下图所示,可用直方图向量来表示或表达图像:

由上图可知,对同一词典,不同图像得到的直方图不同,因此可以用直方图向量来表示图像。
视觉词汇计算示意图:
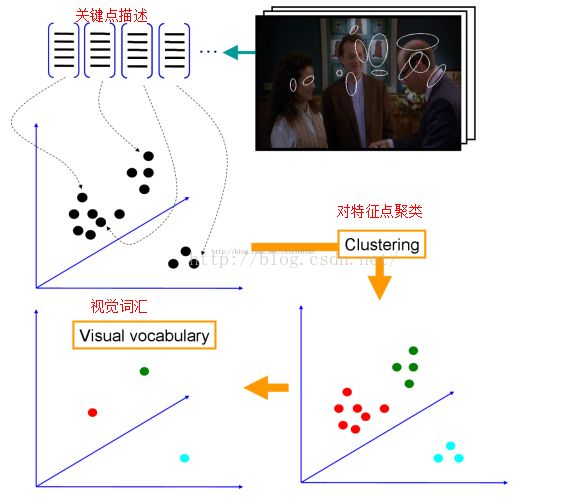
理解:
1)视觉词汇的确定:
计算训练图像中所有图像的关键点和描述,然后在特征空间对关键点聚类,生成类心,每个类心为一个视觉词汇,类心的数目即视觉词典中视觉词汇的个数(训练和聚类过程与图像库中图像的种类无关,只是为了得到一个能表述所有图像特征的视觉词典,该过程类似文档分类中,对相同或相似词汇进行合并,得到一个单词字典)。
2)视觉词汇个数的影响:
视觉词汇的个数即视觉词典的大小,词典大小的选择也是问题,词典过大,单词缺乏一般性,对噪声敏感,计算量大,图象直方图向量的维数高;词典太小,单词区分性能差,对相似的目标特征无法表示。
3)词汇个数的确定问题:
使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。有方法是在海量图片中抽取部分训练集分类,使用朴素贝叶斯分类的方法对图库中其余图片进行自动分类。另外,由于图片爬虫在不断更新后台图像集,重新聚类的代价显而易见。
1.3 应用
1.3.1图像分类
Bag-of-Features更多地是用于图像分类或对象识别,图像分类和识别过程如下:
训练过程:提取训练集中所有图像的局部特征或关键点描述,然后进行聚类,得到视觉词汇,所有的视觉词汇构成视觉词典,并根据视觉词典计算训练图像的直方图向量,即BOF特征,根据训练集中每类图像的BOF特征,训练分类器,得到对象或场景的分类模型;
分类过程:对于待测图像,提取局部特征或关键点描述,计算待测图像特征与词典中每个码字(视觉词汇)的特征距离,即将每个特征都将被映射到视觉词典中点的某个词上,统计每个视觉词汇的频率,得到的直方图向量即为待测图像的Bag-of-Features特征;把待测图像特征输入分类器,判定其类别。如下图所示:
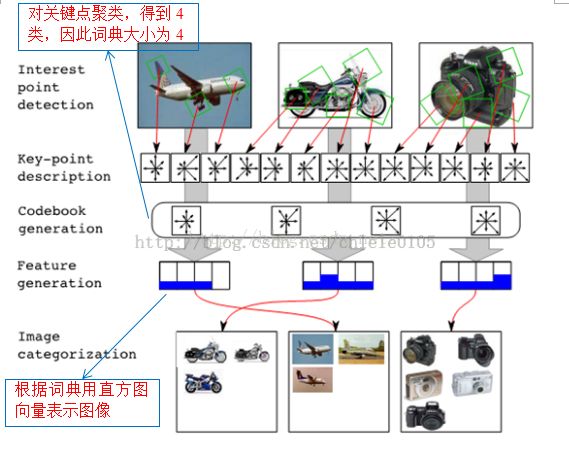
1.3.2 图像检索
Bag-of-words在CV中的应用首先出现在Andrew Zisserman[6]中为解决对视频场景的搜索,其提出了使用Bag-of-words关键点投影的方法来表示图像信息。后续更多的研究者归结此方法为Bag-of-Features,并用于图像分类、目标识别和图像检索。在Bag-of-Features方法的基础上,Andrew Zisserman进一步借鉴文本检索中TF-IDF模型(Term Frequency一Inverse Document Frequency)来计算Bag-of-Features特征向量。接下来便可以使用文本搜索引擎中的反向索引技术对图像建立索引,高效的进行图像检索。
BOF图像检索算法流程:
1.首先,我们用surf算法生成图像库中每幅图的特征点及描述符。(surf算法是关键点计算和描述算法,作用和SIFT相似)。
2.再用k-means算法对图像库中的特征点进行训练,生成类心。
3.生成每幅图像的BOF,具体方法为:判断图像的每个特征点与哪个类心最近,最近则放入该类心,最后将生成一列频数表,即初步的无权BOF(直方图向量)。
4.通过tf-idf对频数表加上权重,生成最终的bof。(因为每个类心对图像的影响不同。比如超市里条形码中的第一位总是6,它对辨别产品毫无作用,因此权重要减小)。
5.对待处理图像也进行3.4步操作,生成该图的直方图向量BOF。
6.将待处理图像的Bof向量与图像库中每幅图的Bof向量求夹角,夹角最小的即为匹配对象。
说明:
1.TF-IDF是一种用于信息检索的常用加权技术,在文本检索中,用以评估词语对于一个文件数据库中的其中一份文件的重要程度。词语的重要性随着它在文件中出现的频率成正比增加,但同时会随着它在文件数据库中出现的频率成反比下降:
TF的主要思想是:如果某个关键词在一篇文章中出现的频率高,说明该词语能够表征文章的内容,该关键词在其它文章中很少出现,则认为此词语具有很好的类别区分度,对分类有很大的贡献。
IDF的主要思想是:如果文件数据库中包含词语A的文件越少,则IDF越大,则说明词语A具有很好的类别区分能力。
词频(Term Frequency,TF)指的是一个给定的词语在该文件中出现的次数。如:tf = 0.030 ( 3/100 )表示在包括100个词语的文档中, 词语'A'出现了3次。
逆文档频率(Inverse Document Frequency,IDF)是描述了某一个特定词语的普遍重要性,如果某词语在许多文档中都出现过,表明它对文档的区分力不强,则赋予较小的权重;反之亦然。如:idf = 13.287 ( log (10,000,000/1,000) )表示在总的10,000,000个文档中,有1,000个包含词语'A'。最终的TF-IDF权值为词频与逆文档频率的乘积。
1.4拓展
1. 直方图相似性度量
每个图像可以用直方图向量来表示,两幅图像是否相同或相似,以及它们的相似程度,可以用直方图相似性度量函数来确定,度量函数有多种,可以选择不同的核函数来表示,如:线型核,塌方距离测度核,直方图交叉核(The Pyramid Match Kernel)等的选择。
2.空间信息
将图像表示成一个无序局部特征集的特征包方法,丢掉了所有的关于空间特征布局的信息,在描述性上具有一定的有限性。为此, Schmid[2]提出了基于空间金字塔的Bag-of-Features(Spatial Pyramid Matching)。
3.用分量差进行图像描述
Jégou[7]提出VLAD(vector of locally aggregated descriptors),其方法是如同BOF先建立出含有k个visual word的codebook,而不同于BOF将一个local descriptor用NN分类到最近的visual word中,VLAD所采用的是计算出local descriptor和每个visual word(c i)在每个分量上的差距,将每个分量的差距形成一个新的向量来代表图片。