Spark中的序列化机制
Spark中的序列化机制
GitHub
标签: Spark Kryo
在写Spark的应用时,尝尝会碰到序列化的问题。例如,在Driver端的程序中创建了一个对象,而在各个Executor中会用到这个对象 —— 由于Driver端代码与Executor端的代码运行在不同的JVM中,甚至在不同的节点上,因此必然要有相应的序列化机制来支撑数据实例在不同的JVM或者节点之间的传输。
什么时候需要调用序列化?
先来看一个自定义的类
package cn.gridx.spark.examples.serialization;
import org.apache.hadoop.hbase.util.Bytes;
public class UnserializableJavaClass {
public String ms;
public byte[] bytes;
public int n;
public UnserializableJavaClass() {
ms = "Uninitialized String";
bytes = null;
n = 0;
}
public UnserializableJavaClass(String s, byte[] bytes, int n) {
ms = s;
this.bytes = bytes.clone();
this.n = n;
}
public String getMs() {
return this.ms ;
}
public byte[] getBytes() { return this.bytes; }
public int getInt() { return this.n ; }
public String toString() { return "ms=" + ms + "\nbytes="
+ Bytes.toStringBinary(bytes) + "\nn=" + n + "\n"; }
public void setInt(int n) { this.n = n; }
}下面给出几种Spark中对UnserializableJavaClass的用法,看看怎样使用会涉及到对该类的序列化。
Example 1:
val conf = new SparkConf().setAppName("Test Serialization")
val sc = new SparkContext(conf)
val javaObj = new UnserializableJavaClass("I'm `UnserializableJavaClass`", Bytes.toBytes("Hello `UnserializableJavaClass`"), 1010)
val rdd = sc.parallelize(1 to 10, 4)
rdd.map(i => new UnserializableJavaClass("I'm `UnserializableJavaClass`", Bytes.toBytes("Hello `UnserializableJavaClass`"), i*100))
.map(x => { x.setInt(javaObj.n + 1); x })
.collect
.foreach(println)
sc.stop运行结果:
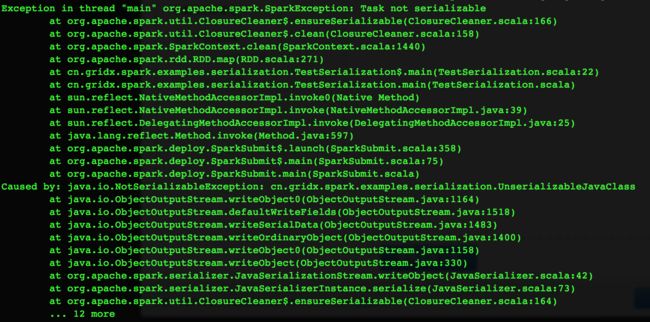
解释:在这行 map(x => { x.setInt(javaObj.n + 1); x }) 中,闭包中引用了Driver端创建的实例javaObj,因此需要将该实例序列化后通过网络传输至各个Executor。
如果把上例中稍加修改:
Example 2
··· ···
rdd.map(i => new UnserializableJavaClass("I'm `UnserializableJavaClass`", Bytes.toBytes("Hello `UnserializableJavaClass`"), i*100))
.map(x => { x.setInt(javaObj.n + 1); x }) // 这里改一下
.collect
.foreach(println)即将Example 1中的map(x => { x.setInt(javaObj.n + 1); x }) 换成 map(x => { x.setInt(x.n + 1); x }),那么,就可以正常地运行结束。
解释:在 map(x => { x.setInt(x.n + 1); x }) 中,Executor没有引用到Driver的实例,因此javaObj不需要被从Driver传输到Executor,因而不需要将其序列化。
Example 3:
什么样的数据类型能够直接被Spark序列化
先来看一个例子,在这个例子中,我们自定义了一个名为UnserializableClass 的类,并将其用在了Spark中。
package cn.gridx.spark.examples.serialization;
public class UnserializableClass {
public String ms;
public UnserializableClass() {
ms = "Uninitialized String";
}
public UnserializableClass(String s) {
ms = s;
}
public String addPrefix(String s) {
return ms + ":" + s;
}
public String getMs() { return ms; }
}
下面在一个Spark程序中使用该类的实例
// Driver
def main(args: Array[String]) {
val conf = new SparkConf()
.setAppName("Test Spark Serialization")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(1 to 10, 4)
val obj = new UnserializableClass("Hello")
rdd.map(i => obj.addPrefix(i.toString))
.collect
.foreach(println)
sc.stop
}
运行后,报异常:
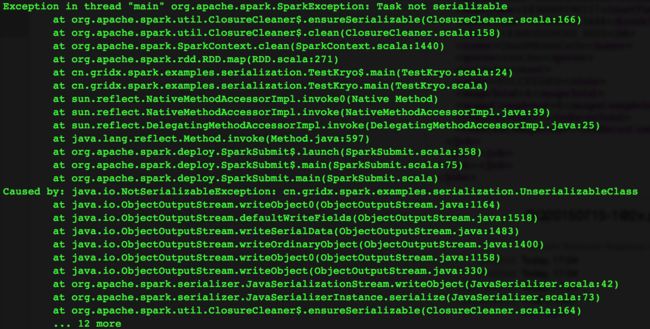
可见,对于自己定义的普通类,Spark是无法直接对其序列化的。
根据 Tuning Spark,Spark可以使用Java的序列化框架。『只要一个class实现了java.io.Serializable接口,那么Spark就能使用Java的ObjectOutputStream来序列化该类』。
验证:令 UnserializableClass 的声明实现接口 java.io.Serializable,但是类 UnserializableClass 的定义不做任何修改,即:
package cn.gridx.spark.examples.serialization;
public class UnserializableClass implements java.io.Serializable{
··· ···
··· ···
}Spark的Driver端代码不做任何修改,此时重新运行Driver程序,可以正常运行结束。
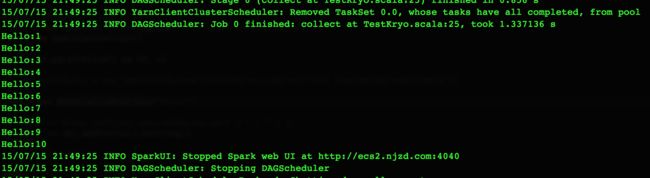
除了Java序列化之外,还有什么其他选择?
上面说了,『只要一个class实现了java.io.Serializable接口,那么Spark就能使用Java的ObjectOutputStream来序列化该类』。
那么问题来了
- 很多第三方的class没有实现 java.io.Serializable* 接口,我们也无法去改变这些第三方class的定义;
- Java的序列化框架效率很低,很慢,性能很差。
实际上,Spark还支持另一种序列化框架 —— Kryo 。 Kryo是一个高效的序列化框架(可以比Java的序列化快10倍以上)。但是Kryo并不能支持所有的Serilizable class,因此需要在使用Kryo前对目标类进行注册(register)。