unserialize的这个问题是由一个emlog论坛用户在使用时报错而发现的 问题表现情况如下: emlog缓存的保存方式是将php的数据对象(数组)序列化(serialize)后以文件的形式存放,
unserialize的这个问题是由一个emlog论坛用户在使用时报错而发现的
问题表现情况如下:
emlog缓存的保存方式是将php的数据对象(数组)序列化(serialize)后以文件的形式存放,读取缓存的时候直接反序列化(unserialize)缓存字符串即可读取数据,关于序列化和反序列化的原理请看我先前的文章《php函数serialize()与unserialize()不完全研究》
我从用户那里取到的缓存的序列化数据为:
a:1:{s:8:"kl_album";a:4:{s:5:"title";s:12:"精彩瞬 间";s:3:"url";s:41:"http://www.kaisay.cn/?plugin=kl_album";s:8:"is_blank";s:7:"_parent";s:4:"hide";s:1:"n";}}
咋一看了解序列化的人都会说,这个数据很正常啊,没什么问题呢。可是直接把这段字符串进行unserialize,返回的值却是个False;
代码
var_dump(unserialize('a:1:{s:8:"kl_album";a:4:{s:5:"title";s:12:"精彩瞬间";s:3:"url";s:41:"http://www.kaisay.cn/?plugin=kl_album";s:8:"is_blank";s:7:"_parent";s:4:"hide";s:1:"n";}}'));
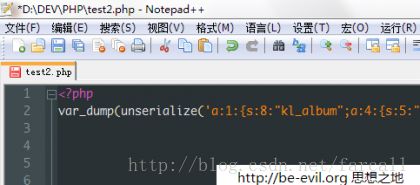
运行结果
问题出在哪里呢?答案是 s:41:"http://www.kaisay.cn/?plugin=kl_album"
序列化字符串中标定该字符串http://www.kaisay.cn/?plugin=kl_album的长度是41,可是我们自己数一下却只有37个字符。就是因为这个问题,导致php反序列化字符串失效。
如果将字符串长度改成37,那么程序就会顺利的反序列化
代码:
var_dump(unserialize('a:1:{s:8:"kl_album";a:4:{s:5:"title";s:12:"精彩瞬 间";s:3:"url";s:37:"http://www.kaisay.cn/?plugin=kl_album";s:8:"is_blank";s:7:"_parent";s:4:"hide";s:1:"n";}}'));

通过google后才发现,这个问题国外已经很多的网友遇到了,在官方手册unserialize函数页面的评论中就有很多网友在讨论和研究这个问题的解决方案。
这种情况发生的原因有多种可能,最大的可能就是在序列化数据的时候的编码和反序列化时的编码不一样导致字符串的长度出现偏差。例如数据库编码latin1和UTF-8字符长度是不一样的。
解决方案:
自己用php来纠正序列化字符串中字符串长度的问题,链接
<?php
$unserialized = preg_replace('!s:(\d+):"(.*?)";!se', "'s:'.strlen('$2').':\"$2\";'", $unserialized );
?>
另外一个网友提出一个在非utf-8情况下的BUG,链接
(\0在C中是字符串的结束符等于chr(0),错误解析后算了2个字符)
$error = preg_replace('!s:(\d+):"(.*?)";!se', "'s:'.strlen('$2').':\"$2\";'", $unserialized );
// 这么写就没事
$works = preg_replace('!s:(\d+):"(.*?)";!se', '"s:".strlen("$2").":\"$2\";"', $unserialized );
// 根据上面的情况我写出的测试例子(注意代码必须用asc格式保存运行)
$test = 's:7:"hahaha'. chr(0) .'";';
echo preg_replace('!s:(\d+):"(.*?)";!se', "'s:'.strlen('$2').':\"$2\";'", $test );
echo '<br>';
echo preg_replace('!s:(\d+):"(.*?)";!se', '"s:".strlen("$2").":\"$2\";"', $test );
echo '<br>';
echo unserialize(preg_replace('!s:(\d+):"(.*?)";!se', "'s:'.strlen('$2').':\"$2\";'", $test ));
echo '<br>';
echo unserialize(preg_replace('!s:(\d+):"(.*?)";!se', '"s:".strlen("$2").":\"$2\";"', $test ));
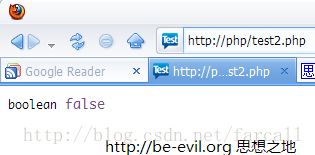
下图是运行结果:很显然chr(0) 变成了 \0
还有一个情况就是单双引号也会出现长度计算错误的问题:链接
<?php
$heightoptionslist = <<<HEIGHTEND
a:3:{s:37:"Hands/inches (eg. 13' 2"HH)";s:6:"option";s:25:"Inches only (eg.39")";s:6:"option";s:24:"Centimeters (eg. 153cms)";s:6:"option";}
HEIGHTEND;
$heightoptionslist = unserialize($heightoptionslist);
echo "<div><pre>\$heightoptionslist = [\n".print_r($heightoptionslist, true)."\n]</pre></div>";
?>
当字符串中带有没有转换的引号的时候,就会出问题了:
<?php
$heightoptionslist = <<<HEIGHTEND
a:3:{s:26:"Hands/inches (eg. 13\' 2\"HH)";s:6:"option";s:20:"Inches only (eg.39\")";s:6:"option";s:24:"Centimeters (eg. 153cms)";s:6:"option";}
HEIGHTEND;
$heightoptionslist = unserialize($heightoptionslist);
echo "<div><pre>\$heightoptionslist = [\n".print_r($heightoptionslist, true)."\n]</pre></div>";
?>
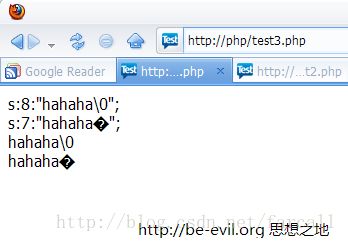
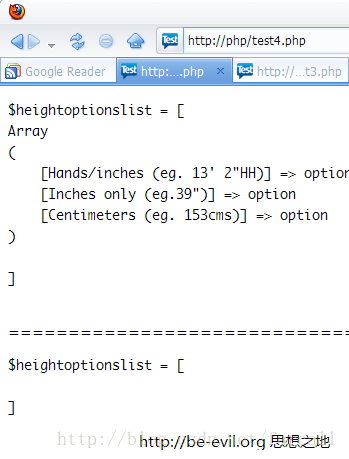
以上两端代码运行结果:
在字符串还有\r字符的时候计算字符串的长度的时候也会出现问题:链接
When dealing with a string which contain "\r", it seems that the length is not evaluated correctly. The following solves the problem for me :
<?php
$unserialized = str_replace("\r","",$unserialized);
unserialize($unserialized);
?>
总结:解决方案
UTF-8
function mb_unserialize($serial_str) {
$serial_str= preg_replace('!s:(\d+):"(.*?)";!se', "'s:'.strlen('$2').':\"$2\";'", $serial_str );
$serial_str= str_replace("\r", "", $serial_str);
return unserialize($serial_str);
}
ASC
function asc_unserialize($serial_str) {
$serial_str = preg_replace('!s:(\d+):"(.*?)";!se', '"s:".strlen("$2").":\"$2\";"', $serial_str );
$serial_str= str_replace("\r", "", $serial_str);
return unserialize($serial_str);
}
希望本文能给所有遇到该问题的朋友一点帮助