(四)洞悉linux下的Netfilter&iptables:包过滤子系统iptable_filter
今天我们讨论一下防火墙的数据包过滤模块iptable_filter的设计原理及其实现方式。
内核中将filter模块被组织成了一个独立的模块,每个这样独立的模块中都有个类似的init()初始化函数。编写完该函数后,用module_init()宏调用初始化函数;同样当模块被卸载时调用module_exit()宏将该模块卸载掉,该宏主要调用模块的“析构”函数。这当中就牵扯到内核ko模块的一些知识,但这并不妨碍我们理解。
整个filter模块就一百多行代码,但要将其理解清楚还是需要一些功夫。我们首先来看一下filter模块是如何将自己的钩子函数注册到netfilter所管辖的几个hook点的。
| static int __init iptable_filter_init(void) { int ret; if (forward < 0 || forward > NF_MAX_VERDICT) { printk("iptables forward must be 0 or 1\n"); return -EINVAL; } /* Entry 1 is the FORWARD hook */ initial_table.entries[1].target.verdict = -forward - 1;
/* Register table */ ret = ipt_register_table(&packet_filter, &initial_table.repl); if (ret < 0) return ret;
/* Register hooks */ ret = nf_register_hooks(ipt_ops, ARRAY_SIZE(ipt_ops)); if (ret < 0) goto cleanup_table; return ret;
cleanup_table: ipt_unregister_table(&packet_filter); return ret; } |
这里我只看关键部分,根据上面的代码我们已经知道。filter模块初始化时先调用ipt_register_table向Netfilter完成filter过滤表的注册,然后调用ipt_register_hooks完成自己钩子函数的注册,就这么简单。至于这两个注册的动作分别都做了哪些东西,我们接下来详细探究一下。
注册过滤表:ipt_register_table(&packet_filter, &initial_table.repl);
Netfilter在内核中为防火墙系统维护了一个结构体,该结构体中存储的是内核中当前可用的所有match,target和table,它们都是以双向链表的形式被组织起来的。这个全局的结构体变量static struct xt_af *xt定义在net/netfilter/x_tables.c当中,其结构为:
| struct xt_af { struct mutex mutex; struct list_head match; //每个match模块都会被注册到这里 struct list_head target; //每个target模块都会被注册到这里 struct list_head tables; //每张表都被被注册到这里 struct mutex compat_mutex; }; |
其中xt变量是在net/netfilter/x_tables.c文件中的xt_init()函数中被分配存储空间并完成初始化的,xt分配的大小以当前内核所能支持的协议簇的数量有关,其代码如下:

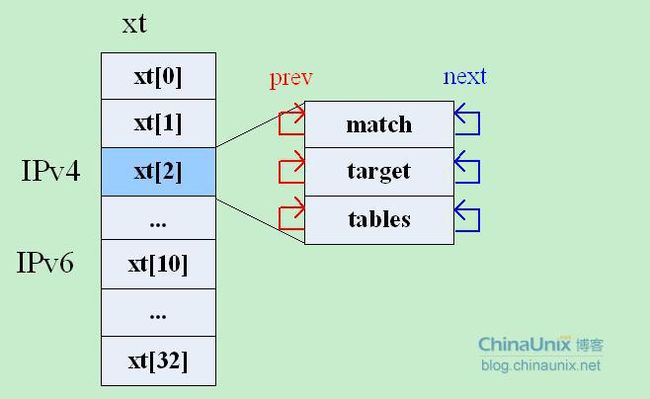
每注册一张表,就会根据该表所属的协议簇,找到其对应的xt[]成员,然后在其tables双向链表中挂上该表结构即完成了表的注册。接下来我们再看一下Netfilter是如何定义内核中所认识的“表”结构的。
关于表结构,内核中有两个结构体xt_table{}和xt_table_info{}来表示“表”的信息。
struct ipt_table{}的结构体类型定义在中,它主要定义表自身的一些通用的基本信息,如表名称,所属的协议簇,所影响的hook点等等。
| struct xt_table //其中#define ipt_table xt_table { struct list_head list; char name[XT_TABLE_MAXNAMELEN]; //表的名字 unsigned int valid_hooks; //该表所检测的HOOK点 rwlock_t lock; //读写锁 void *private; //描述表的具体属性,如表的size,表中的规则数等 struct module *me; //如果要设计成模块,则为THIS_MODULE;否则为NULL int af; //协议簇 ,如PF_INET(或PF_INET) }; |
而每张表中真正和规则相关的信息,则由该结构的的private属性来指向。从2.6.18版内核开始,该变量被改成了void*类型,目的是方便日后对其进行扩充需要。通常情况下,private都指向一个xt_table_info{}类型的结构体变量。
struct xt_table_info{}的结构体类型定义在< include/linux/netfilter/x_tables.h >中。
| struct xt_table_info { unsigned int size; //表的大小,即占用的内存空间 unsigned int number; //表中的规则数 unsigned int initial_entries; //初始的规则数,用于模块计数
/* 记录所影响的HOOK的规则入口相对于下面的entries变量的偏移量*/ unsigned int hook_entry[NF_IP_NUMHOOKS]; /* 与hook_entry相对应的规则表上限偏移量,当无规则录入时,相应的hook_entry和underflow均为0 */ unsigned int underflow[NF_IP_NUMHOOKS]; char *entries[NR_CPUS]; }; |

我们发现ipt_register_table()函数还有一个输入参数:initial_table。根据其名称不难推断出它里面存储的就是我们用于初始化表的一些原始数据,该变量的结构虽然不复杂,但又引入了几个其他的数据结构,如下:
| static struct { struct ipt_replace repl; struct ipt_standard entries[3]; struct ipt_error term; } initial_table; |
在注册过滤表时我们只用到了该结构中的struct ipt_replace repl成员,其他成员我们暂时先不介绍,主要来看一下这个repl是个神马东东。
ipt_replace{}结构体的定义在include/linux/netfilter_ipv4/ip_tables.h文件中。其内容如下:
| struct ipt_replace { char name[IPT_TABLE_MAXNAMELEN]; //表的名字 unsigned int valid_hooks; //所影响的HOOK点 unsigned int num_entries; //表中的规则数目 unsigned int size; //新规则所占用存储空间的大小
unsigned int hook_entry[NF_IP_NUMHOOKS]; //进入HOOK的入口点 unsigned int underflow[NF_IP_NUMHOOKS]; /* Underflow points. */
/* 这个结构不同于ipt_table_info之处在于它还要保存旧的规则信息*/ /* Number of counters (must be equal to current number of entries). */ unsigned int num_counters; /* The old entries' counters. */ struct xt_counters __user *counters;
/* The entries (hang off end: not really an array). */ struct ipt_entry entries[0]; }; |
之所以要设计ipt_replace{}这个结构体,是因为在1.4.0版的iptables中有规则替换这个功能,它可以用一个新的规则替换掉指定位置上的已存在的现有规则(关于iptables命令行工具的详细用法请参见man手册或iptables指南)。最后我们来看一下initial_table.repl的长相:
| initial_table.repl= { "filter", FILTER_VALID_HOOKS, 4, sizeof(struct ipt_standard) * 3 + sizeof(struct ipt_error), { [NF_IP_LOCAL_IN] = 0, [NF_IP_FORWARD] = sizeof(struct ipt_standard), [NF_IP_LOCAL_OUT] = sizeof(struct ipt_standard) * 2 }, { [NF_IP_LOCAL_IN] = 0, [NF_IP_FORWARD] = sizeof(struct ipt_standard), [NF_IP_LOCAL_OUT] = sizeof(struct ipt_standard) * 2 }, 0, NULL, { } }; |
根据上面的初始化代码,我们就可以弄明白initial_table.repl成员的意思了:
"filter"表从"FILTER_VALID_HOOKS"这些hook点介入Netfilter框架,并且filter表初始化时有"4"条规则链,每个HOOK点(对应用户空间的“规则链”)初始化成一条链,最后以一条“错误的规则”表示结束,filter表占(sizeof(struct ipt_standard) * 3+sizeof(struct ipt_error))字节的存储空间,每个hook点的入口规则如代码所示。 因为初始化模块时不存在旧的表,因此后面两个个参数依次为0、NULL都表示“空”的意思。最后一个柔性数组struct ipt_entry entries[0]中保存了默认的那四条规则。
由此我们可以知道,filter表初始化时其规则的分布如下图所示:

我们继续往下走。什么?你说还有个ipt_error?记性真好,不过请尽情地无视吧,目前讲了也没用。那你还记得我们现在正在讨论的是什么主题吗?忘了吧,我再重申一下:我们目前正在讨论iptables内核中的filter数据包过滤模块是如何被注册到Netfilter中去的!!
有了上面这些基础知识我们再分析ipt_register_table(&packet_filter, &initial_table.repl)函数就容易多了,该函数定义在net/ipv4/netfilter/ip_tables.c中:
| int ipt_register_table(struct xt_table *table, const struct ipt_replace *repl) { int ret; struct xt_table_info *newinfo; static struct xt_table_info bootstrap = { 0, 0, 0, { 0 }, { 0 }, { } }; void *loc_cpu_entry; newinfo = xt_alloc_table_info(repl->size); //为filter表申请存储空间 if (!newinfo) return -ENOMEM;
//将filter表中的规则入口地址赋值给loc_cpu_entry loc_cpu_entry = newinfo->entries[raw_smp_processor_id()]; //将repl中的所有规则,全部拷贝到newinfo->entries[]中 memcpy(loc_cpu_entry, repl->entries, repl->size); /*translate_table函数将由newinfo所表示的table的各个规则进行边界检查,然后对于newinfo所指的xt_talbe_info结构中的hook_entries和underflows赋予正确的值,最后将表项向其他cpu拷贝*/ ret = translate_table(table->name, table->valid_hooks, newinfo, loc_cpu_entry, repl->size, repl->num_entries, repl->hook_entry, repl->underflow); if (ret != 0) { xt_free_table_info(newinfo); return ret; } //这才是真正注册我们filter表的地方 ret = xt_register_table(table, &bootstrap, newinfo); if (ret != 0) { xt_free_table_info(newinfo); return ret; } return 0; } |
在该函数中我们发现点有意思的东西:还记得前面我们在定义packet_filter时是什么情况不? packet_filter中没对其private成员进行初始化,那么这个工作自然而然的就留给了xt_register_table()函数来完成,它也定义在x_tables.c文件中,它主要完成两件事:
1)、将由newinfo参数所存储的表里面关于规则的基本信息结构体xt_table_info{}变量赋给由table参数所表示的packet_filter{}的private成员变量;
2)、根据packet_filter的协议号af,将filter表挂到变量xt中tables成员变量所表示的双向链表里。
最后我们回顾一下ipt_register_table(&packet_filter, &initial_table.repl)的初始化流程:
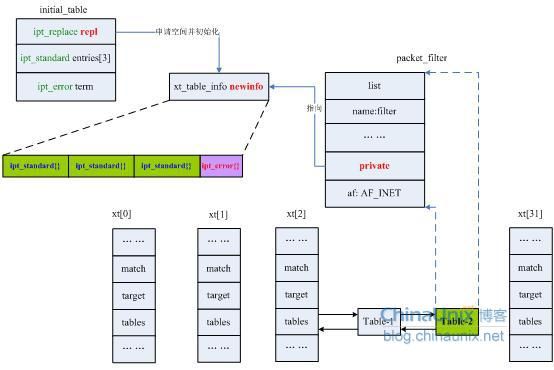
简而言之ipt_register_table()所做的事情就是从模板initial_table变量的repl成员里取出初始化数据,然后申请一块内存并用repl里的值来初始化它,之后将这块内存的首地址赋给packet_filter表的private成员,最后将packet_filter挂载到xt[2].tables的双向链表中。
注册钩子函数:nf_register_hooks(ipt_ops, ARRAY_SIZE(ipt_ops));
在第二篇博文中我们已经简单了解nf_hook_ops{}结构了,而且我们也知道该结构在整个Netfilter框架中的具有相当重要的作用。当我们要向Netfilter注册我们自己的钩子函数时,一般的思路都是去实例化一个nf_hook_ops{}对象,然后通过nf_register_hook()接口其将其注册到Netfilter中即可。当然filter模块无外乎也是用这种方式来实现自己的吧,那么接下来我们来研究一下filter模块注册钩子函数的流程。
首先,我们看到它也实例化了一个nf_hook_ops{}对象——ipt_ops,代码如下所示:
| static struct nf_hook_ops ipt_ops[] = { { .hook = ipt_hook, .owner = THIS_MODULE, .pf = PF_INET, .hooknum = NF_IP_LOCAL_IN, .priority = NF_IP_PRI_FILTER, }, { .hook = ipt_hook, .owner = THIS_MODULE, .pf = PF_INET, .hooknum = NF_IP_FORWARD, .priority = NF_IP_PRI_FILTER, }, { .hook = ipt_local_out_hook, .owner = THIS_MODULE, .pf = PF_INET, .hooknum = NF_IP_LOCAL_OUT, .priority = NF_IP_PRI_FILTER, }, }; |
对上面这种定义的代码我们现在应该已经很清楚其意义了:iptables的filter包过滤模块在Netfilter框架的NF_IP_LOCAL_IN和NF_IP_FORWARD两个hook点以NF_IP_PRI_FILTER(0)优先级注册了钩子函数ipt_hook(),同时在NF_IP_LOCAL_OUT过滤点也以同样的优先级注册了钩子函数ipt_local_out_hook()。
然后,在nf_register_hooks()函数内部通过循环调用nf_register_hook()接口来完成所有nf_hook_ops{}对象的注册任务。在nf_register_hook()函数里所执行的操作就是一个双向链表的查找和插入,没啥难度。考大家一个问题,测试一下你看博客的认真和专心程度:filter模块所定义的这些hook函数是被注册到哪里去了呢?
=================================华丽丽的分割线================================
想不起的话可以去复习一下第一篇博文结尾部分的内容,不过我知道大多数人都懒的翻回去了。好吧,我再强调一遍:所有的hook函数最终都被注册到一个全局的二维的链表结构体数组struct list_head nf_hooks[NPROTO][NF_MAX_HOOKS]里了。一维表示协议号,二维表示hook点。
还记得我们给过滤模块所有hook函数所划的分类图么:
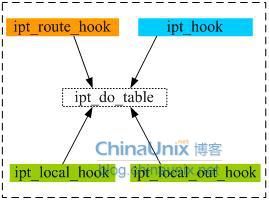
目前只出现了ipt_hook和ipt_local_out_hook,不过这四个函数本质上最后都调用了ipt_do_table()函数,而该函数也是包过滤的核心了。
数据包过滤的原理:
根据前面我们的分析可知,ipt_do_table()函数是最终完成包过滤功能的这一点现在已经非常肯定了,该函数定义在net/ipv4/netfilter/ip_tables.c文件中。实际上,90%的包过滤函数最终都调用了该接口,它可以说是iptables包过滤功能的核心部分。在分析该函数之前,我们把前几章中所有的相关数据结构再梳理一遍,目的是为了在分析该函数时达到心中有数。
我们前面提到过的核心数据结构有initial_table、ipt_replace、ipt_table、ipt_table_info、ipt_entry、ipt_standard、ipt_match、ipt_entry_match、ipt_target、ipt_entry_target,这里暂时没有涉及到对用户空间的相应的数据结构的讨论。以上这些数据结构之间的关系如下:
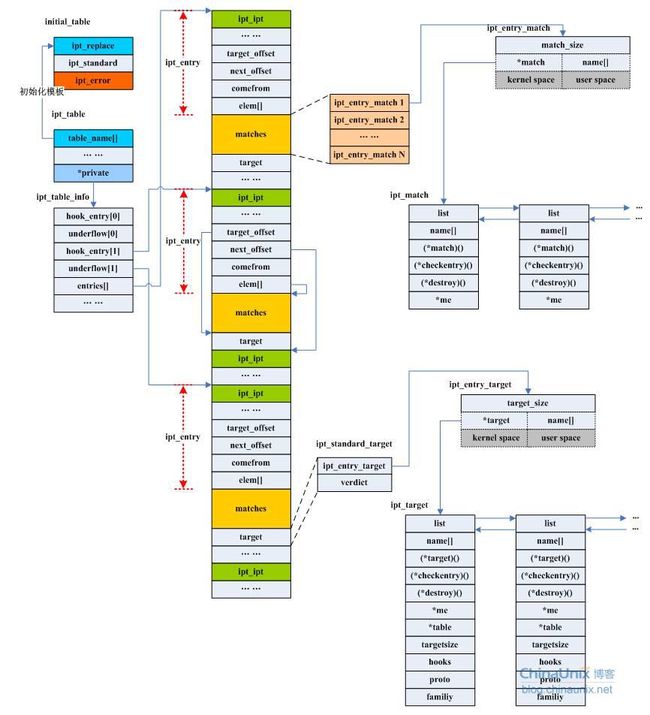
我们还是先看一下ipt_do_table()函数的整体流程图:
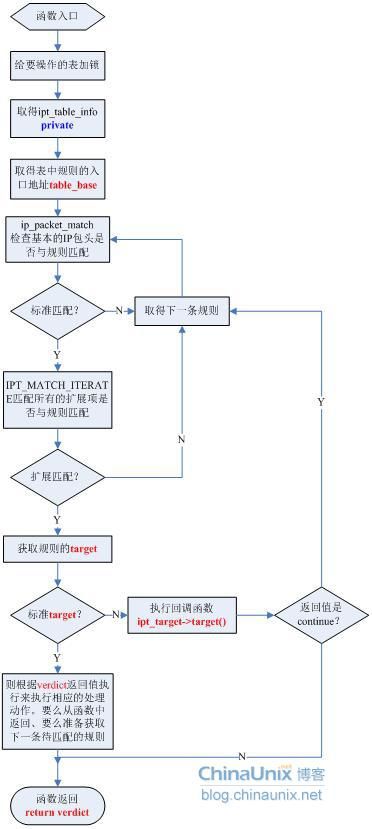
我们分析一下整个ipt_do_table()函数执行的过程:
对某个hook点注册的所有钩子函数,当数据包到达该hook点后,该钩子函数便会被激活,从而开始对数据包进行处理。我们说过:规则就是“一组匹配+一个动作”,而一组规则又组成了所谓的“表”,因此,每条规则都属于唯一的一张表。前面我们知道,每张表都对不同的几个HOOK点进行了监听,而且这些表的优先级是不相同的,我们在用户空间里去配置iptables规则的时候恰恰也是必须指定链名和表名,在用户空间HOOK点就被抽象成了“链”的概念,例如:
iptables –A INPUT –p tcp –s ! 192.168.10.0/24 –j DROP
这就表示我们在filter表的NF_IP_LOCAL_IN这个HOOK点上增加了一个过滤规则。当数据包到达LOCAL_IN这个HOOK点时,那么它就有机会被注册在这个点的所有钩子函数处理,按照注册时候的优先级来。因为表在注册时都已确定了优先级,而一个表中可能有数条规则,因此,当数据包到达某个HOOK点后。优先级最高的表(优先级的值越小表示其优先程度越高)中的所有规则被匹配完之后才能轮到下一个次高优先级的表中的所有规则开始匹配(如果数据包还在的话)。
所以,我们在ipt_do_table()中看到,首先就是要获取表名,因为表名和优先级在某种程度上来说是一致的。获取表之后,紧接着就要获取表中的规则的起始地址。然后用依次按顺序去比较当前正在处理的这个数据包是否和某条规则中的所有过滤项相匹配。如果匹配,就用那条规则里的动作target来处理包,完了之后返回;如果不匹配,当该表中所有的规则都被检查完了之后,该数据包就转入下一个次高优先级的过滤表中去继续执行此操作。依次类推,直到最后包被处理或者被返回到协议栈中继续传输。
未完,待续…