大小端模式的快速判断
采用Little-endian模式的CPU对操作数的存放方式是 从低字节到高字节,而Big-endian模式对操作数的存放方式是从高字节到低字节。例如,16bit宽的数0x1234在Little-endian 模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 |
0x4000 |
0x4001 |
| 存放内容 |
0x34 |
0x12 |
而在Big-endian模式CPU内存中的存放方式则为:
| 内存地址 |
0x4000 |
0x4001 |
| 存放内容 |
0x12 |
0x34 |
我们常用的X86结构是小端模式,而KEIL C51则为大端模式。
方法一:强制类型转换,直接使用看变量的内存值
#include<stdio.h>
void main()
{
int a = 0x01;
char * p = (char*) & a;
if(*p == 1)
{
printf("little endian\n");
}
else
{
printf("big endian\n");
}
}
大小端存储问题,如果小端方式中(a 占至少两个字节的长度)则 a 所分配的内存最小地址那个字节中就存着1,其他字节是0.大端的话则1在 a 的最高地址字节处存放,char是一个字节,所以强制将char型量p指向a则p指向的一定是a的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
或者:- #include<stdio.h>
- void main()
- {
- short s=0x1234;
- char * pTest=(char*)&s;
- printf("%p %0X %X",&s,pTest[0],pTest[1]);
- }
以十六进制输出short型变量s在内存中的字节分布。
运行结果为:
0012FF7C
34 12
或者
bool IsLitte_Endian()
{
int wTest = 0x12345678;
short *pTest=(short*)&wTest;
return !(0x1234 == pTest[0]);
}
方法二:使用C中的共用体:
请写一个C函数,若处理器是Big_endian的,则返回false;若是Little_endian的,则返回true。
bool IsLitte_Endian()
{
union w{
int a;
char b;
}c;
c.a=1;
return (c.b==1);
}
或者:
union Judge
{
short s;
char ch[sizeof(short)];
};
Judge flag;
int main()
{
flag.s = 0x0102;
if ( sizeof(short) !=2 )
{
cout<<" 测得short类型有"<<sizeof(short)<<"个字节"<<endl;
}
if ( flag.ch[0] == 2 && flag.ch[1] == 1 )
{
cout<<"你用的电脑处理器是小端模式!"<<endl;
}
else if ( flag.ch[0] == 1 && flag.ch[1] == 2 )
{
cout<<"你用的电脑处理器是大端模式!"<<endl;
}
else
{
cout<<"未知模式"<<endl;
}
system("pause");
return 0;
}
方法三:
#include<stdio.h>
main()
{
int a=0x12345678; //a的值为十六进制的12345678
char * p; //p为字符型指针
p=(char *)&a; //强制类型转换
printf("%x\n",*p); //输出a中地址值最小的字节的内容
printf("%x\n",*(p+1));
printf("%x\n",*(p+2));
printf("%x\n",*(p+3)); //输出a中地址值最大的字节的内容
}
vc6.0运行结果:
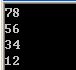
可以看出是小端
自己认为:可以加上
if((*p)>*(p+1))printf("小端\n");else printf("小端\n");
运行结果为:
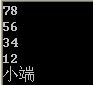
-----------------------------------------------------------------------------------------------
例1:如写入的数据为u32型,但是读取的时候却是char型的:
如:0x1234, 大端读取为12时,小端独到的是34。
例2:将buffer中的数转换为整型:
如:int src = 0x1234
memcpy(buffer, src, sizeof(int));
大端:buffer[4] = {0x01, 0x02, 0x03, 0x04};
小端:buffer[4] = {0x04, 0x03, 0x02, 0x01};