RDD实战
RDD操作:Transformation(已有RDD-》新的RDD,数据状态),Action(结果保存到hbase,driver),Controller(persist,cache,checkpoint性能)
lazy 延迟执行,步骤越多,优化的空间越大(可以有一些可以合并的操作)
collector收集所有RDD中的数组,Collect后Array中就是一个元素,只不过是这个元素是一个Tuple
driver收到所有数据的结果,然后concat方法
并行度就有多少Task,就有多少partition
collect是将各个节点上的数据合并成一个数组,这个数组中只有一个元素,这个元素是一个元组(tulpe),一个包含key value的元组
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
几个分区就有几个并行 分区了才能并行
transformation操作

统计文件中相同行的个数
package com.dt.scala.spark
import org.apache.spark.{SparkContext, SparkConf}
object Transformations {
//程序总入口函数
def main (args: Array[String]) {
val sc = sparkContext("transformations app")//这是第一个RDD的唯一入口,是Driver的灵魂
// mapTransformation(sc)//map转换操作的实例
// filterTransformation(sc)//filter转换操作的实例
// flatMapTransformation(sc)//flatMap转换操作实例
// groupbykeyTransformation(sc)//groupbykeyTransformation实例
// reducebykeyTransformation(sc)//reducebykey实例
// joinTransformation(sc)//jon实例
cogroupTransformation(sc)//cogroup实例
sc.stop()//彻底停止sparkcontext,销毁相关的driver对象,释放资源
}
def sparkContext(name:String)=
{
val conf = new SparkConf();//初始化SparkConf,
conf.setAppName(name)//初始化应用程序环境配置
conf.setMaster("local")
val sc = new SparkContext(conf)//这是第一个RDD的唯一入口,是Driver的灵魂
sc
}
def mapTransformation(sc:SparkContext){
val data = sc.parallelize(1 to 10)//根据集合创建RDD
val mapped = data.map(item => item * 2)//map作用于任何数据,且对集合中的每个元素循环遍历并调用其作为参数的函数对每一个遍历的元素进行具体化处理
mapped.collect().foreach(println)
}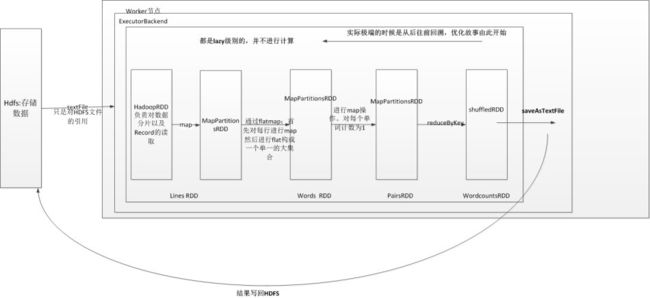
collect收集RDD
而改成SaveAstextFile,写回HDFS
def filterTransformation(sc:SparkContext)
{
val data = sc.parallelize(1 to 10)//根据集合创建RDD
val filtered = data.filter(item => item%2 == 0)
filtered.collect().foreach(println)
}
def flatMapTransformation(sc:SparkContext)
{
val bigdata = Array("hadoop java"," scala spark","python spark")//实例还字符串类型的Array
val bigdatatem = sc.parallelize(bigdata)//创建义字符串为元素类型的parallelcollectionRDD
val flatmapped = bigdatatem.flatMap(_.split(" "))//首先是通过传入的作为参数的函数来作用RDD的每一个字符的来进行单词切分
flatmapped.collect().foreach(println)
}def groupbykeyTransformation(sc:SparkContext)
{
val data = Array(Tuple2(100,"Spark"),Tuple2(90,"hadoop"),Tuple2(70,"hbase"),Tuple2(100,"Spark2"))
val dataRDD = sc.parallelize(data)//创建RDD
val group = dataRDD.groupByKey()//按照相同的key对value进行分组,分组后的value是一个集合
group.collect().foreach(println)//收集结果并通过佛reach循环打印
}def reducebykeyTransformation(sc:SparkContext)
{
val lines = sc.textFile("D://book//Scala//spark-1.4.1-bin-hadoop2.6//README.md", 1)//都区本地文件,设置1个partition
//对初始的RDD进行转换操作
val words = lines.flatMap{line =>line.split(" ")}
val pairs = words.map { word =>(word,1) }
val wordconuts = pairs.reduceByKey(_+_) // val wordconuts = words.countByValue()
wordconuts.foreach(wordnumpair => println(wordnumpair._1+":"+wordnumpair._2))
}def joinTransformation(sc:SparkContext){
val studentNames = Array(
Tuple2(1,"spark"),
Tuple2(2,"tachyon"),
Tuple2(3,"hadoop")
)
val studentScores = Array(
Tuple2(1,100),
Tuple2(2,95),
Tuple2(3,65)
)
val names = sc.parallelize(studentNames)
val scores = sc.parallelize(studentScores)
val studentnameAndscore = names.join(scores)
studentnameAndscore.collect().foreach(println)
}
def cogroupTransformation(sc:SparkContext)
{
val studentNames = Array(
Tuple2(1,"spark"),
Tuple2(2,"tachyon"),
Tuple2(3,"hadoop"),
Tuple2(1,"spark1")
)
val studentScores = Array(
Tuple2(1,100),
Tuple2(2,"tachyon"),
Tuple2(5,65)
)
val names = sc.parallelize(studentNames)
val scores = sc.parallelize(studentScores)
val studentnameAndscore = names.cogroup(scores)
studentnameAndscore.collect().foreach(println)
}
}