提升树(BoostingTree)原理与实现

作者:金良([email protected]) csdn博客: http://blog.csdn.net/u012176591
类Classifier将多个基本分类器组合成一个强分类器
import numpy as np
class Classifier:
def __init__(self):
self.__stumps = []
self.aa = self.__stumps
self.__hasmakemodel = False
self.__posuniq = np.nan
self.__valuelist = np.nan
def add(self,pos,val1,val2):
self.__hasmakemodel = False
exceptlabel = False
try:
np.sum(np.array([pos,val1,val2])+1)
except:
exceptlabel = True
if exceptlabel == False:
stump = self.__stump(pos,val1,val2)
self.__stumps.append(stump)
else:
print 'Input parameter is INVALID.\n\t Try again please.'
def __stump(self,pos,val1,val2):
return {'pos':pos,'val':(val1,val2)}
def __makemodel(self):
self.__posuniq = list(set([stump['pos'] for stump in self.__stumps]))
self.__posuniq.sort()
self.__valuelist = np.zeros(len(self.__posuniq)+1)
for stump in stumps:
idx = self.__posuniq.index(stump['pos'])
self.__valuelist[:idx+1] += stump['val'][0]
self.__valuelist[idx+1:] += stump['val'][1]
self.__hasmakemodel = True
def predict(self,x):
if self.__hasmakemodel == False:
self.__makemodel()
for idx in range(len(self.__posuniq)+1):
try:
if x < self.__posuniq[idx]:
break
except:
pass
y = self.__valuelist[idx]
return y
if __name__ == "__main__":
classifier = Classifier()
classifier.add(6.5,6.24,8.91)
classifier.add(3.5,-0.52,0.22)
classifier.add(6.5,0.15,-0.22)
classifier.add(4.5,-0.16,0.11)
classifier.add(6.5,0.07,-0.11)
classifier.add(2.5,-0.15,0.04)
predictlist = np.array([classifier.predict(i+1) for i in range(10)])
valuelist = np.array([5.56,5.70,5.91,6.40,6.80,7.05,8.90,8.70,9.00,9.05])
loss = np.sum(np.power(predictlist - valuelist,2))
print '平方误差:',str(loss)
类BoostingTree是主体,它有一个Classifier对象成员
import numpy as np
import copy
class BoostingTree:
def __init__(self,data,iters=6):
self.__data = copy.deepcopy(data)
#将一个Classifier对象作为成员
self.__classifier = Classifier()
self.__division = [(self.__data['x'][idx]+self.__data['x'][idx+1])/2.0 for idx in range(self.__data['x'].shape[0]-1)]
self.__iters = iters
self.__hasmakemodel = False
def __makemodel(self):
residuallist = self.__data['y']
for it in range(self.__iters):
performancelist = []
predictlist = np.zeros(residuallist.shape[0])
for idx,x in enumerate(self.__division):
meanleft = np.mean(residuallist[:idx+1]) #左侧的均值
predictlist[:idx+1] = meanleft
meanright = np.mean(residuallist[idx+1:]) #右侧的均值
predictlist[idx+1:] = meanright
loss = np.sum(np.power(residuallist - predictlist,2)) #平方误差
performancelist.append([loss,x,meanleft,meanright])
#xidx是最优的分界点序号
xidx = np.argmin([performance[0] for performance in performancelist])
#下面两行求残差
residuallist[:xidx+1] -= performancelist[xidx][2]
residuallist[xidx+1:] -= performancelist[xidx][3]
#添加新的弱分类器
self.__classifier.add(performancelist[xidx][1],performancelist[xidx][2],performancelist[xidx][3])
self.__hasmakemodel = True
def predict(self,x):
if self.__hasmakemodel == False:
self.__makemodel()
try: #当x不是单个数字元素时
x[0]
size = np.shape(x)[0]
y = [0]*size
for i in range(size):
y[i] = self.__classifier.predict(x[i])
return y
except:
return self.__classifier.predict(x) 对BoostingTree进行测试:
data = {'x':np.array([1,2,3,4,5,6,7,8,9,10]),
'y':np.array([5.56,5.70,5.91,6.40,6.80,7.05,8.90,8.70,9.00,9.05])}
boostingtree = BoostingTree(data)
predictlist = boostingtree.predict(np.array([1,2,3,4,5,6,7,8,9,10]))
valuelist = np.array([5.56,5.70,5.91,6.40,6.80,7.05,8.90,8.70,9.00,9.05])
loss = np.sum(np.power(predictlist - valuelist,2))
print '平方误差:',str(loss) 平方误差: 0.1703
可视化
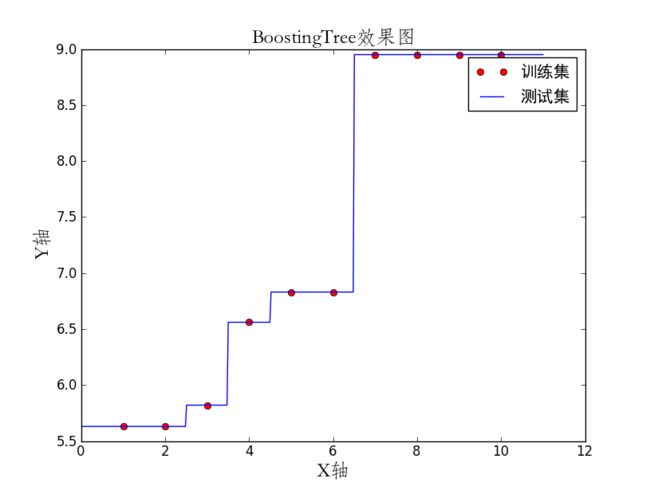
代码:
trainx = np.array([1,2,3,4,5,6,7,8,9,10])
trainy = boostingtree.predict(trainx)
testx = np.linspace(0,11,400)
testy = boostingtree.predict(x)
plt.plot(trainx,trainy,'r.',marker = u'o',label=u'训练集')
plt.plot(testx,testy,'b',label=u'测试集')
plt.legend(prop={'family':'SimHei','size':15})
plt.title(u'BoostingTree效果图',{'fontname':'STFangsong','fontsize':18})
plt.xlabel(u'X轴',{'fontname':'STFangsong','fontsize':18})
plt.ylabel(u'Y轴',{'fontname':'STFangsong','fontsize':18})