hashMap 和 hashTable 简单介绍
以hashmap 源码为例, 分析map数据结构,
今天仔细看了一下hashmap的源码,有hashmap又有了新的认识,先记录下来,不敢妄谈对hashm已经完全了解,但求能滴水穿石
无论hashtable 亦或 hashmap 存数map的基本数据结构都是 transient Entry[] table;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
......
}以前只是以为,存储的是一个 Entry 类型的数组,但是 请仔细看 Entry 的结构中有 这样 一个 Entry<K,V> next;字段,没错 这是链表结构才会有的 ,目的是为了指向 下一个节点。
可是hashmap不是一个数组吗?怎么还扯出链表结构了呢?继续看下面的代码
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}这是hashmap函数的put方法,下面我们来仔细分析一下这段代码
首先 检查 key 是否为null,如果为null ,则直接执行 putForNullKey函数
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}因为null的hashcode始终为0 ,所以 k = null v = valye的这个map一定放在 table的 第 0个 位置(entry 在table中 存放位置 稍后解释)
注意红色标记的那句代码告诉我们,table中每个索引位 存放的就是一个链表。
好了,我们回到上面的put方法,接着往下看,
通过key的hashCode()方法计算了这个key的hash值,这个hash值被用来计算存储Entry对象的数组中的位置。JDK的设计者假设会有一些人可能写出非常差的hashCode()方法,会出现一些非常大或者非常小的hash值。为了解决这个问题,他们引入了另外一个hash函数,接受对象的hashCode(),并转换到适合数组的容量大小。
接着是indexFor(hash,table,length)方法,这个方法计算了entry对象存储的准确位置。
接下来就是主要的部分,我们都知道两个不相等的对象可能拥有过相同的hashCode值,两个不同的对象是怎么存储在相同的索引位[叫做bucket]呢?
答案是LinkedList。如果你记得,Entry类有一个next变量,这个变量总是指向链中的下一个变量,这完全符合链表的特点。
所以,在发生碰撞的时候,entry对象会被以链表的形式存储起来,当一个Entry对象需要被存储的时候,hashmap检查该位置是否已近有了一个entry对象,如果没有就存在那里,如果有了就检查她的next属性,如果是空,当前的entry对象就作为已经存储的entry对象的下一个节点,依次类推。
在这种方式下HashMap就能保证key的唯一性。
又上我们可以推断出 get(key)函数 的 工作原理
先 得到 key 的 hashcode 。然后通过hash函数封装hashcode得到 int型数据 hash
indexFor 函数 通过hash 得到 entry 在 table中的索引 ,然后开始遍历 该索引位的 entry链表 (遍历条件,hash值首先要相等,当然得了, key == 或者 equal )
条件符合 则范围 entey.value
下面就是get函数(与上面的推断一致)
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
return null;
}
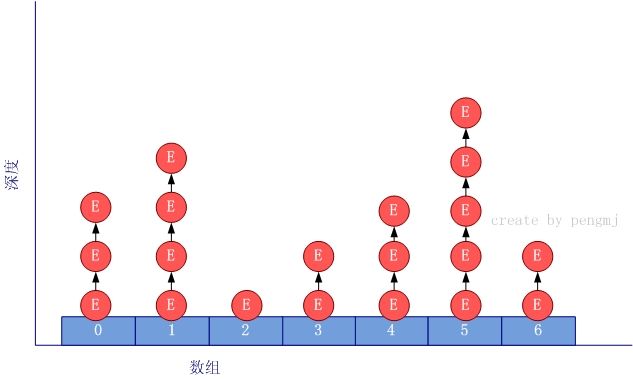
至此,OK,hashmap函数的分析先告一段落,上面的图像,完完全全的体现出 table 数组存数的entry的存数结构。