电商搜索引擎的架构设计和性能优化
「 OneAPM 技术公开课」由应用性能管理第一品牌 OneAPM 发起,内容面向 IT 开发和运维人员。云集技术牛人、知名架构师、实践专家共同探讨技术热点。本文系「OneAPM 技术公开课」第一期演讲嘉宾前当当网高级架构师吴英昊的演讲整理:
首先,非常感谢 OneAPM 技术公开课举办的这次活动。首先,我想说的是电商搜索引擎和普通的搜索引擎有很大的差别,因为电商搜索引擎主要是解决用户要「买什么」,而通用搜索引擎主要是解决用户「搜什么」。比如同样搜索一个词「百年孤独」,电商的搜索肯定是给你推荐这本书的商家,而百度主要是告诉你:《百年孤独》是一本书。
电商搜索引擎的特点
众所周知,标准的搜索引擎主要分成三个大的部分,第一步是爬虫系统,第二步是数据分析,第三步才是检索结果。首先,电商的搜索引擎并没有爬虫系统,因为所有的数据都是结构化的,一般都是微软的数据库或者 Oracle 的数据库,所以不用像百度一样用「爬虫」去不断去别的网站找内容,当然,电商其实也有自己的「爬虫」系统,一般都是抓取友商的价格,再对自己进行调整。
第二点,就是电商搜索引擎的过滤功能其实比搜索功能要常用。甚至大于搜索本身。什么是过滤功能?一般我们网站买东西的时候,搜了一个关健词,比如尿不湿,然后所有相关品牌或者其他分类的选择就会呈现在我们面前。对百度而言,搜什么词就是什么词,如果是新闻的话,可能在时间上会有一个过滤的选项。
第三点,电商搜索引擎支持各种维度的排序,包括支持好评、销量、评论、价格等属性的排序。而且对数据的实时性的要求非常高。对一般的搜索引擎,只有非常重要的网站,比如一些重量级的门户网站,百度的收录是非常快的,但是对那些流量很小的网站,可能一个月才会爬一次。电商搜索对数据的实时性要求主要体现在价格和库存两个方面。
电商搜索引擎另一个特点就是不能丢品,比如我们在淘宝、天猫开了个店铺,然后好不容易搞了一次活动,但是却搜不到了,这是无法忍受的。除此之外,电商搜索引擎与推荐系统和广告系统是相互融合的,因为搜素引擎对流量的贡献是最大的,所以大家都希望把广告系统能跟其融合。当然,还有一点非常重要,就是要保证绝对的高可用,而且不能宕机。
电商搜索引擎的架构
因为电商搜索引跟一般的搜索引擎区别很大,所以在架构的设计上也独具特色。首先,搜索引擎的实现方式有很多种,有谷歌、百度、搜狗这种非常大的公司,也有京东、淘宝、当当这样的电商搜索引擎,很多中小型的电商可能更喜欢用一个开源的搜索引擎。所以总的来说,主要包括以下这几种方式:

第一种是「Lucene+自己封装」,只用来做检索,然后封装,后面所有的 ES,这两个是完整的解决方案,而且包括索引所有的东西,只需要部署好业务逻辑,然后查找结果就可以了。
第二种就是 Solr,这是一个高性能,采用 Java5 开发,基于 Lucene 的全文搜索服务器。同时对其进行了扩展,提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
第三种是 ElasticSearch,这是一个基于 Lucene 的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口。Elasticsearch 是用 Java 开发的,并作为 Apache 许可条款下的开放源码发布,目前使用的也非常多。
这里提一下,当当的搜索引擎是自己实现的,。现在,新兴的互联网公司大部分都是使用第一种或者第二种,数据量比较大的一般采用第三种。
电商搜索引擎标配模块

接下来我想讲一下,如果我们自己做一个搜索引擎的话需要实现哪些功能(上图是电商搜索引擎的标准模块),其实不止是电商搜索引擎,除了通搜的搜索引擎,其他的搜索引擎也是使用这样的标配。

对检索模块而言,首先是对用户的意图进行分析,根据用户的搜索词来进行纯算法的实现。比如用户的搜索词是「黑包包」,其实用户的本意就是买一个黑色的包,但是这个「包」可以跟别的词组合在一起,甚至在搜索结果中会出现「包子」。所以,这就需要 query 分析系统来做,告诉检索系统,你需要主要在服装鞋帽中的分类去找,而不是生鲜食品类。
设计到技术层面,当当网使用的是 C++。如果构建一个性能好的系统,一些老一点的公司,大家都是在使用 C++ 或者是 C 语言。不止是当当网,其实很多公司都是使用的 C 或者 C++ 实现的搜索引擎。
数据更新模块
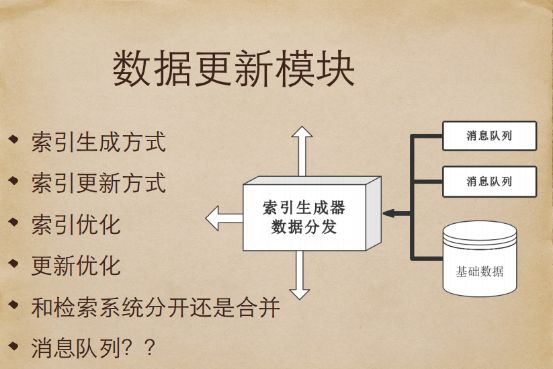
第二个模块就是数据更新模块,该模块负责生成索引。而数据中心模块主要做的事情,就是将原始的结构化数据,变成一个可供检索系统使用的搜索数据库。当然,数据更新模块和检索模块是分开还是合并呢?其实从本质上讲,都是一堆代码,完全可以写在一个进程里。当然,也可以分开,通过网络往外输入,各自都有道理。第一种是简单粗暴型的,如果是普通电商,像生鲜电商,数据量不大,实时性、季节性很强,就可以把两个系统用一个进程来完成。但是如果到了百万、千万甚至上亿级别的话,就不可能部在一台机器上了。

上图就是当两个系统合并在一起的时候,红色部分就是检索系统,黄色部分是上游产生数据的系统,如果是淘宝的话,对接就是淘宝的商户,当当网对接是市场部的人员,他们将数据录入系统,推到数据库,然后向下进行传送,最终建立一个索引。
上图中的蓝色部分就是业务逻辑,因为电商的搜索引擎业务需求量非常高,尤其是现在大家都喜欢用手机进行购物,像手机专享价就是一个新的业务,这也意味着需要一个专用的模块来处理这些商用的逻辑。
此外,就是用户行为的分析,我们搜集到的日志还有其他相关的数据都会存到 Hadoop 集群上去,通过离线计算,然后传给商业模块或者排序模块进行排序和打分,并提供给用户更好的使用体验。
出问题是不可避免的!如何解决?
虽然整理来看,设计的思路是非常合理的,但是还是会出现问题。一般而言,一个成熟的电商搜索系统,它的问题都很集中,要这几种情况:首先就是 Bug,当然这是所有系统都会遇到的问题;第二个就是并发,但是搜索系统是没办法进行分库分表,所以能做的就是索引切分;最后一点就是监控,包括问题追踪、日志系统和监控系统,那么为了解决这些问题,我们应该怎么做?
首先,针对 Bug 问题,只能靠自动化运维去解决(这里也推荐使用 OneAPM 工具);第二个就是高并发的问题,目前主要是靠缓存和横向扩展。而缓存和横向扩展怎么应用到系统中去,这个很关键。很多人也说可以换一种语言,比如讲 Python 换成 C++,但实际情况下,换语言并不能解决并发的问题,好的数据结构的设计比换一种语言更能提高性能,所以一般解决高并发问题的也就是缓存和横向扩展。
第三个就是使用用 FLUME 日志系统(Flume 是 Cloudera 提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume 提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力)。其实,Flume 会把集群上每一个节点的日志全都收集起来,这样做起来有两个好处,第一是现场出问题,可以先回滚出 Bug,然后进行查询。第二个就是对日志进行搜集,然后做用户行为分析,查看用户点击了多少次,从何处导入的流量等等,从而便于更好的进行排序。

然后讲一下缓存的问题。一般搜索的缓存可能分为两级缓存,据我观察,像搜狗可能是使用页面级缓存,而百度可能用的是索引级的缓存。比如在搜狗搜索一个词,开始时可能需要 40 毫秒,然后再搜的话,就可能一下子降到 1 毫秒。这就是页面级缓存。而百度可能第一次搜索用了 40 毫秒,第二次就是 25 毫秒,它并不是把页面给缓存下来,而是将索引的倒排链缓存,级别其实是不一样的。
电商搜索很多使用的是两级缓存,对于特别热门的词汇,我们可以做页面级缓存,而页面级缓存的时间只有 15 秒到 20 秒。但是像价格这样的东西不能缓存,需要前台页面去反拉价格。第二级就是索引级别的缓存,实际上也是自建的一个缓存系统。另外,排序也有缓存,因为排序的结果不太会有太大的变化。
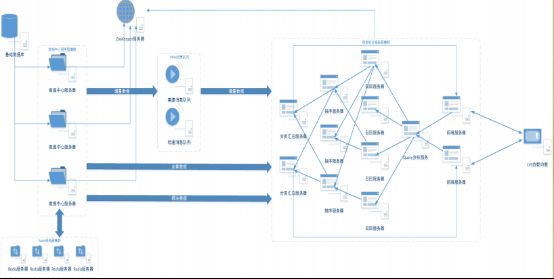
上图是当当的搜索架构,这里有一个集群是做数据分析的,上面备满了数据。
首先,集群之间采用什么样的通讯方式?我们主要使用 ZMQ(这是一个简单好用的传输层,像框架一样的一个 socket library,使得 Socket 编程更加简单、简洁和性能更高。是一个消息处理队列库,可在多个线程、内核和主机盒之间弹性伸缩)。原因其实只有一个,就是快,非常快,比较适合数据量比较大的业务。
如何避免冷启动?
最后就是冷启动的问题,这个问题是很多电商网站都很头疼的问题。尤其是随着电商网站的商品数量达到一定量级的时候,比如已经上亿了,像淘宝、天猫的话应该更多。如果重建了一次索引需要启动,或者新上线了一个业务模块,需要重启系统,是很麻烦的。
当然,当集群大了以后有很多方法,比如分开启动之类的,至于技术嘛,一般索引的加载都是使用 Lunix 标准的 MMAP(MMAP 将一个文件或者其它对象映射进内存。文件被映射到多个页上,如果文件的大小不是所有页的大小之和,最后一个页不被使用的空间将会清零。MMAP 在用户空间映射调用系统中作用很大),这样启动速度会很快,但是系统会有预热时间,前面一些时间的查询会比较慢
如果数据量不是特别大的话,而且现在内存也那么便宜,完全可以将数据一次性读入内存,因为 mmap 的操作毕竟性能没有直接内存来得快。
第三种的话,就是尽量减少做全量数据的频率,避免整个系统的重启,这需要定期做一下索引的优化,把没用的索引干掉。
如果是新上了一个业务模块需要重启集群,这样的事情最好不要发生,这就是架构有问题了,将业务模块变成外部的模块或者插件进行上线才是正确的,不然每上线一个模块需要重启集群,这谁都受不了。