日志结构的合并树 The Log-Structured Merge-Tree
近年来,随着互联网数据的日益增长,管理分布式数据需求的日益增加,Bigtable[1]等一系列NoSQL数据库开始涌现。Bigtable是一个分布式的结构化数据存储系统,它被设计用来处理海量数据,其在提供Tablet服务时使用内存中的memtable和GFS[2]中的SSTable来相互配合着来存储数据更新,其中存储和更新的方法与日志结构的合并树[3](Log-Structured Merge-Tree,LSM-tree)类似,并以其为基础。
Log-Structured的思想最早由 Rosenblum和Ousterhout[4]于1992年在研究日志结构的文件系统时提出。他们将整个磁盘就看做是一个日志,在日志中存放永久性数据及其索引,每次都添加到日志的末尾;通过将很多小文件的存取转换为连续的大批量传输,使得对于文件系统的大多数存取都是顺序性的,从而提高磁盘带宽利用率,故障恢复速度快。 O'Neil[3]等人受到这种思想的启发,借鉴了Log不断追加(而不是修改)的特点,结合B-tree的数据结构,提出了一种延迟更新,批量写入硬盘的数据结构LSM-tree及其算法。LSM-tree努力地在读和写两方面寻找一个平衡点以最小化系统的存取性能的开销,特别适用于会产生大量插入操作的应用环境。
LSM-tree
LSM-tree是由两个或两个以上存储数据的结构组成的。最简单的LSM-tree由两个部件构成。一个部件常驻内存,称为C0树(或C0),可以为任何方便键值查找的数据结构,另一个部件常驻硬盘之中,称为C1树(或C1),其数据结构与B-tree类似。C1中经常被访问的结点也将会被缓存在内存中。如下图所示:

图1:两部件的LSM-tree
当插入一条新的数据条目时,首先会向日志文件中写入插入操作的日志,为以后的恢复做准备。然后将根据新条目的索引值将新条目插入到C0中。将新条目插入内存的C0中,不需要任何与硬盘的I/O操作,但内存的存储代价比硬盘的要高上不少,因此当C0的大小达到某一阈值时,内存存储的代价会比硬盘的I/O操作和存储代价还高。故每当C0的大小接近其阈值时,将有一部分的条目从C0滚动合并到硬盘中的C1,以减少C0的大小,降低内存存储数据的代价。
C1的结构与B-tree相似,但其结点中的条目是满的,结点的大小为一页,树根之下的所有单页结点合并到地址连续的多页块中。
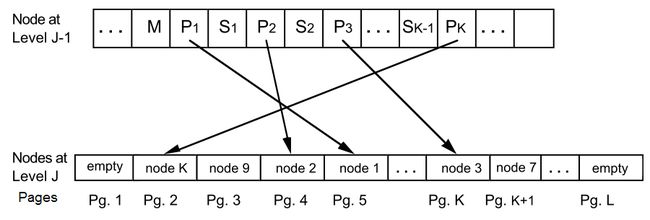
图2:多页块的结构及其结点的结构
事实上,除了在多页块中不必从左至右填充结点外,C1与SB-tree[5]几乎相同。如图所示。J-1层结点包含连续的指向J层结点(node1,node2,...nodeK)的指针(P1,P2,...,PK)和分割指针的键(S1,S2,...,SK-1)。J层结点连续存放在多页块的K页中,并且不必按照键的大小排列。如果J层的两个结点存放于同一个多页块中,那这两个结点的键值之间的所有结点也存放在多页块中。M是多页块分割的标记,表示直到下一个M标记或空结点之内的所有后续结点都存放在同一个多页块中。M中包含了多页块开始的硬盘页号和多页块中结点的数量。树根始终是以一个单页存储的。可以看出多页块可用于范围检索,而多页块中结点可用于精确的键值匹配的检索。
假设C0也是一种B-tree,设想在滚动合并时,C0和C1都有一个指向相等键值的游标,游标指向下一个将要合并的叶子结点中的条目。从根结点到达这个位置的路径将C1上所有正在进行滚动合并的多页块分成两部分。一部分是游标还未到达的结点,合并时读入清空块(emptying block),另一部分是游标已经过的结点,即滚动合并的结果,合并时写入填充块(filling block)。这样的过程如下:
- 从C1中读入未合并的叶子结点,存储于内存的清空块中;
- 从C0中读取叶子结点,并与清空块中的叶子结点进行合并排序;
- 将合并排序的结果写入填充块中,并从C0中删除用于合并排序的旧叶子结点;
- 不断地重复步骤2和3,当填充块被合并排序的结果填满时,将填充块追加到硬盘的新位置,并从C1中删除用于合并排序的旧叶子结点,当清空块被全部读取完时,再从C1中读入未合并的叶子结点;
- 当C0和C1的所有叶子节点都被读入内存进行合并,并产生新的叶子结点之后,C0和C1的一次滚动合并就结束了。
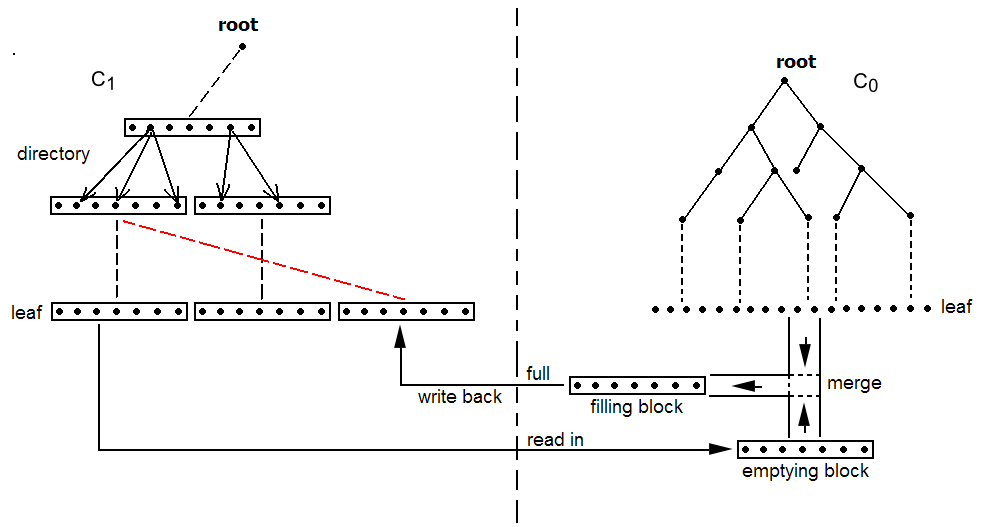
图3:C0与C1之间的滚动合并
C0并不将所有的条目都拿来滚动合并。由于C0存储在内存之中,所以C0可以保留最近插入或最常访问的那些数据,以提高访问速率并降低I/O操作的次数。C1的旧多页块可用于崩溃恢复,所以为了不覆盖旧多页块,滚动合并产生的新多页块将被写入硬盘的新空间。一般来说,每次合并之后,会剩下一些不满的没有写入硬盘的填充块,没有填入填充块的叶子结点,这些结点会和它们的目录结点一样暂时缓存在内存中,等待下次滚动合并时,再写入相应的填充块或者填满并写入硬盘。另外当设置检查点时,这些缓存的信息会被强制写入硬盘。叶子结点载入内存后,其父结点(目录结点)也会被缓存至内存中以减小滚动合并时所需的I/O操作。当滚动合并产生新的叶子结点产生后,会导致父结点(或者目录结点)发生相应的变化。当C1的父结点所属的多页块不满时,通常会停留在内存中一段时间,但其所指的叶子结点可以先写入硬盘之中。当发生下列情况时,目录结点及其多页块将被强制写入硬盘:
- 一个包含目录结点的多页块已满;只将满的多页块写入硬盘。
- 根结点分裂,C1树的深度增加;所有的多页块缓存都将被写入硬盘。
- 设置检查点。所有的多页块都将被写入硬盘。
两部件LSM-tree的代价估计
为了对LSM-tree的代价进行简单地估计。首先定义硬盘和内存的代价符号如下:
COSTd=1M字节的硬盘存储的代价
COSTm=1M字节的内存存储的代价
COSTP=随机访问时,每秒读写一页的I/O操作所需硬盘臂移动的代价
COSTπ=多页块读写时,每秒读写一页的I/O操作所需硬盘臂移动的代价
这里需要注意的是,就目前而言,硬盘存储的代价要低于内存存储的代价,即COSTd<COSTm。
LSM-tree与B-tree的插入代价比较
执行B-tree的插入操作需要首先找到条目要插入的位置,即要进行一次B-tree查找。假设插入的位置是随机的,那么之前插入所缓存的结点页面可能就无法重复使用了。由此定义:
De=使用B-tree进行随机访问时,在内存缓存中未找到的页数
为了执行一个插入操作,需要进行De次I/O操作以在B-tree叶结点中找到插入的位置,插入数据之后,再进行1次I/O操作将新数据写回。由于相关结点的分裂对开销作用不大,这里我们就不考虑结点的分裂问题了。那么B-tree的插入代价就是
LSM-tree的插入操作首先是直接作用在常驻内存的C0上的,然后是批量地从C0将条目滚动合并到C1中。滚动合并是以多页块作为单元进行合并的,合并时读取一页所需的I/O代价为COSTπ。为了评价滚动合并的延迟插入的效果,定义
M=从C0合并到C1的平均条目数
Se=条目的字节大小
Sp=硬盘页的字节大小
S0=C0的叶子层的大小(以兆字节为单位)
S1=C1的叶子层的大小(以兆字节为单位)
一个硬盘页(通常就是一个结点的大小)中所含的条目的数目约为Sp/Se,那么滚动合并时一页中来自于C0的条目约为S0/(S0 + S1)。那么M就可以估计为:
当C0相对于C1的大小越大时,参数M也就越大。对于一次插入来说,LSM-tree在插入C0之后,滚动合并时需要读进C1的叶子结点,再写回C1。由于滚动合并是批量插入C0的条目的,所以一次插入的代价是滚动合并代价的1/M。所以LSM-tree的插入代价:
将B-tree与LSM-tree的插入代价相比,即可得到:
在实际应用中说,K1接近于一个常数。所以LSM-tree与B-tree之比取决于M和COSTπ/COSTP。由于C1的多页块在硬盘中是连续存储的,COSTπ一般会比COSTP来得小,故公式的大小其实取决于M。当一页中包含的条目数较多,C0的规模与C1差距不大时,LSM-tree在数据插入上是优于B-tree的。
代价与数据温度
从另一个角度看,B-tree往往限制在硬盘或内存中,而LSM-tree则是跨越硬盘和内存实现数据存取的优化。假设有一个应用程序使用B-tree有S兆字节数据存储(假设不变),并需要每秒随机访问硬盘中的数据H次。那么应用程序使用硬盘臂的代价就是H∙COSTB-ins,使用硬盘进行存储的代价就是S∙COSTd。在应用程序刚开始运行的时候,主要是加载应用程序的数据等初始化动作,这时随机访问硬盘的次数较少,H相当小,这时应用程序的开销主要是硬盘存储数据的开销,即是S∙COSTd。随着程序的不断运行,应用程序内的业务逻辑会需要访问之前存储的数据,随机访问硬盘的次数就会越来越大,H也就越来越大,随机访问的代价就无法忽略了。具体来说,就是S∙COSTd>H∙COSTB-ins。应用程序的开销代价就变为H∙COSTP。随机访问的不断增加会使得硬盘磁盘臂的功率逐渐达到最大,但在访问硬盘的代价小于使用内存缓存(即H∙COSTB-ins<S∙COSTm)之前,依然可以直接访问硬盘。当H∙COSTB-ins>S∙COSTm时,将应用程序存储数据的B-tree全部缓存到内存中,可以使得应用程序的开销代价减小,这样应用程序的开销代价就是S∙COSTm。
综上所述,可以看出应用程序在两个地方发生的转折,一个是在随机访问的代价与存储的代价相等时,即
另一个是在随机访问的代价与缓存的代价相等时,即
由此,将H/S定义为数据的温度,将两个转折点之间的区域称温数据,两端的区域分别称为冷数据和热数据,同理可得使用LSM-tree存储S兆字节时,代价也会在两个地方发生转折,即
通常来说,De+1通常大于2,M大于1,并且随着H的增加,De+1和M都会不断变大。所以LSM-tree的两个转折点均要后于B-tree的转折点,而且LSM-tree的第二个转折点要远远在B-tree第二个转折点之后。应用程序的总体代价COSTTOT随H/S变化如下图所示:
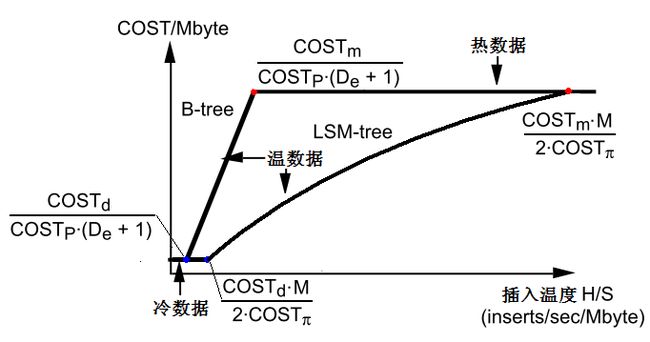
图4:存取1兆字节数据所需的代价随温度的变化
冷数据区域的代价由硬盘的存储代价决定,不大能反映数据结构和算法的好坏。但越迟走出冷数据就越能反映对硬盘的利用率。热数据区域的代价主要集中在内存存储的代价上,同样也不大能反映数据结构和算法的好坏。但越迟进入就越能反映对内存的利用率。综合来看,LSM-tree的代价曲线在B-tree之下,可见LSM-tree对硬盘和内存的利用率都比B-tree要高。这主要是因为两点:
- 滚动合并时批量写入新插入的数据,平摊单个条目插入的开销;
- C1的各层结点存储在多页块中,合并时顺序读写多页块,减小磁盘臂的移动。
在热数据区域,无论是B-tree还是LSM-tree都将数据全部读到内存中,LSM-tree主要是增大C0的规模,使之与C1相当。此时的问题内存的开销就越来越大。由于内存的空间毕竟是有限的,一味地增加C0是不可取的。若减少C0的规模,由M的估计公式,M可能会下降。其实当某些比较大的条目需要不只一页来存放的时侯,M也可能会下降。这种情况下,从C0到C1的每次滚动合并需要从C1读入和写出多个页或多页块。特别地,当
时,多页块的读写优势将荡然无存,B树的插入性能将优于LSM-tree。为了避免M小于1,就又不得不增加C0的规模。
一个解决方法就是在日益增大的C1和有空间上限的C0之间加入一个C做为C0和C1的缓冲。这时LSM-tree就由三个部分(C1、C和C0)组成。这种LSM-tree称为多部件的LSM-tree。
多部件的LSM-tree
在数据不断增加的情况下,即使在C1和C0之间增加上一个C,C的规模也会不断增长。当C像过去C1那么大时,就需要在C和C0之间再增加一个C。以此类推,硬盘中的C树将会越来越多。如下图所示:
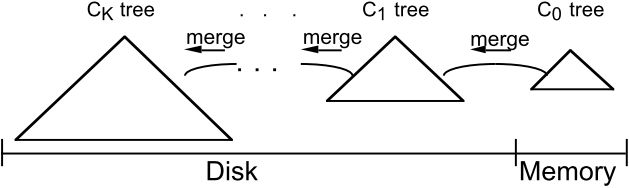
图5:多部件的LSM-tree
通常,一个多部件的LSM-tree由大小依次递增的C0,C1,C2,...,CK-1和CK组成,C0常驻内存之中,可以是键值索引的数据结构。而C1~CK则存储于硬盘之中,但其经常访问的页会被缓存于内存之中,它们的结构都是索引树。在数据不断插入的过程中,当较小的Ci-1的规模超过某一阈值时,相邻的两个部件Ci-1和Ci会进行滚动合并,从较小的Ci-1转移条目至较大的Ci中。各个相邻部件Ci-1和Ci的滚动合并是异步的。也就是说,一个条目会插入到C0中,之后经过不断的异步滚动合并过程,最终合并至CK中。
由于各个相邻部件Ci-1和Ci的滚动合并是异步的,但当对其中的数据进行访问时,常常发生一些并发性问题。例如当进行精确检索或者加载多页块至内存时,Ci里的一个节点会被读入内存;当进行范围检索或滚动合并时,Ci里的多页块会被读入内存中。这些情况下,查找数据时Ci里的所有未被锁住的结点都可以被访问,并会定位被读入内存的结点。即使结点正在进行滚动合并,结点也可以被访问。显然,这时结点上的数据可能是不完整的。基于这些考虑,访问LSM-tree必须遵循下列规则:
- 当硬盘中的相邻部件进行滚动合并的时候,当前参与合并的结点不能被查找;
- 当C0和C1进行滚动合并的时候,当前参与合并的C0的结点周边不能被查找和插入;
- 在Ci-1和Ci与Ci和Ci+1同时进行滚动合并时,Ci-1与Ci滚动合并的游标有时会超过Ci和Ci+1滚动合并的游标。
为了避免对硬盘里的部件进行存取时产生的物理冲突,LSM-tree设置了以结点为单位的锁。在进行滚动合并时,正在合并的结点会在写模式下被锁住,直到有来自较大部件的结点被合并才被释放。在进行查找时,正在被读取的结点会在读模式下被锁住,读取完毕后,锁即被释放。
与C0和C1的滚动合并相比,硬盘内的相邻部件Ci-1和Ci之间的滚动合并多了一个清空块和填充块。这是因为Ci-1和Ci都存储在硬盘之中,合并时需要先将Ci-1和Ci的清空块和填充块存入内存,合并的过程与C0和C1的相同,但Ci-1不会将所有的条目都拿去合并,而是会保留一部分条目(例如新插入的那部分条目)到Ci-1的填充块。如下图所示:
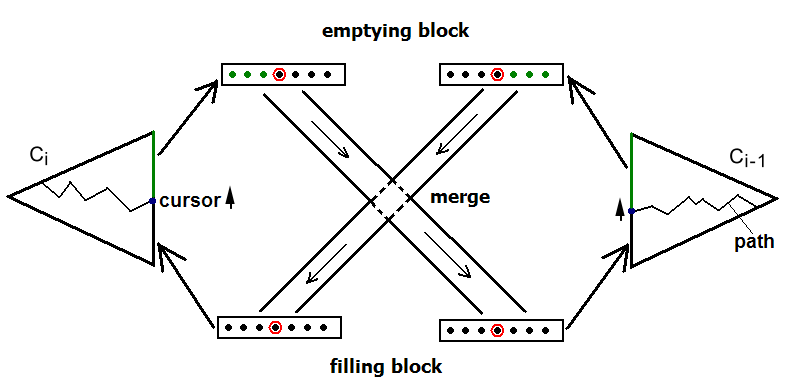
图6:硬盘中相邻两部件的滚动合并
当前正在进行滚动合并的结点被加锁(红圈圈住的点),写保护。蓝色的点表示游标,绿色的点表示游标未到达的结点,树上折线表示从树根到游标的路径
查找、删除和修改
在LSM-tree树进行查找时,为了保证LSM-tree上的所有条目都被检查。首先要搜索C0,再搜索C1,进而搜索C2,...,CK-1和CK。即使硬盘中的部件C1,C2,...,CK-1和CK的结构都是B-tree,这也将耗费一些时间。但在实际的应用中,总可以将搜索限制在前几个的部件的搜索上。
试想新条目插入时首先插入至C0中,然后通过各相邻部件Ci,和Ci+1之间的滚动合并,逐步转移到更大的部件中。在滚动合并时,如果将最近τ时间内被访问的条目保留下来,而将其它条目用于合并,那么经常被访问的那些数据就会被依次保存在C0,C1,...,CK-1和CK中。也就是说,我们可以简单的认为,C0保存的是最近τ时间内被访问的条目,C1保存的是除了C0保存的数据外,最近2τ时间内被访问的条目,C2保存的是除了C0和C1保存的数据外,最近3τ时间内被访问的条目。依此可推广到CK-1。而最后的部件CK保存的是最近Kτ之前的条目。这样凡是在最近τ时间内被执行的事务都不需要与硬盘进行I/O交换,可以直接在内存中找到数据。
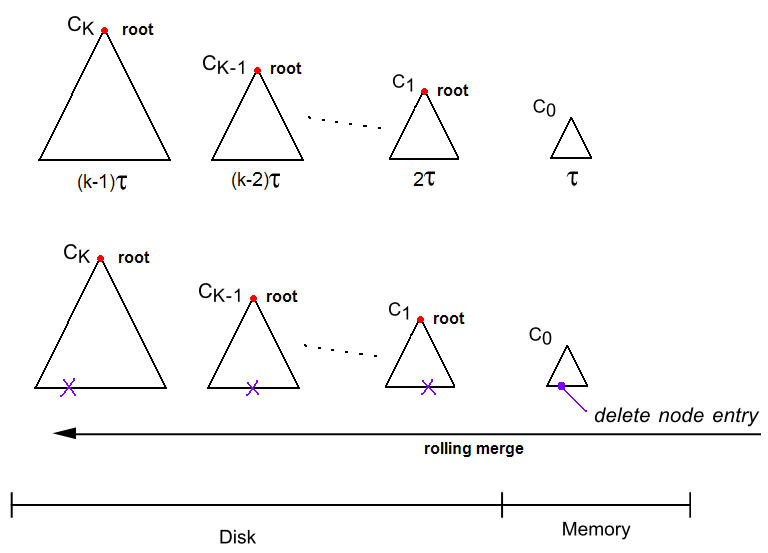
图7:查找与删除
LSM-tree的优势在于其能推迟写回硬盘的时间,进而达到批量地插入数据的目的。为了更高效地利用LSM-tree的插入优势,删除操作被设计为通过插入操作来执行。当C0所索引的一个条目被删除时,首先在C0上查找该条目所对应的索引是否存在,若不存在,就建立一个索引。然后在该索引键值的位置上设置删除条目(delete node entry)。删除条目的意义仅在于通知所有访问该索引的操作,“此索引键值所索引的条目已经被删除了”。在后续的滚动合并中,凡是在较大的部件中碰到的与该索引键值相同的条目都将被删除。此外,当在LSM-tree中查找删除的条目时,如果碰到这种删除条目,就会直接返回未找到。对于条目的修改,依仗LSM-tree的插入优势,可以先插入一个对应的删除条目,待删除条目经滚动合并离开C0后,再在上插入该条目的新值。
崩溃恢复
在新条目插入到C0后,当C0与C1进行滚动合并时,某些条目将从C0转移到更大的部件中。由于滚动合并发生在内存缓存的多页块中,所以只有当条目真正写入硬盘时,滚动合并的成果才会真正生效。然而滚动合并时可能就会发生系统故障,进而使得内存数据丢失。为了能有效地进行系统恢复,在LSM-tree的日常使用中,需要记录一些用以恢复数据的日志。然而与以往数据库中的日志不同的是,日志中只需要要记录数据插入的事务。简单地说,这些日志只包含了被插入数据的行的号码及插入的域和值。
LSM-tree在记日志时设置检查点(checkpoint)以恢复某一时刻的LSM-tree。当需要在时刻T0设置检查点时:
- 完成所有部件的当前合并,这样结点上的锁就会被释放;
- 将所有新条目的插入操作以及滚动合并推迟至检查点设置完成之后;
- 将C0写入硬盘中的一个已知的位置;此后对C0的插入操作可以开始,但是合并操作还要继续等待;
- 将硬盘中的所有部件(C1~CK)在内存中缓存的结点写入硬盘;
- 向日志中写入一条特殊的检查点日志。
检查点日志的内容包括:
- T0时刻最后一个插入的已索引的行的日志序列号(Log Sequence Number,LSN0);
- 硬盘中的所有部件的根在硬盘中的地址;
- 各个部件的合并游标;
- 新多页块动态分配的当前信息。在以后的恢复中,硬盘存储的动态分配算法将使用此信息判别哪些多页块是可用的。
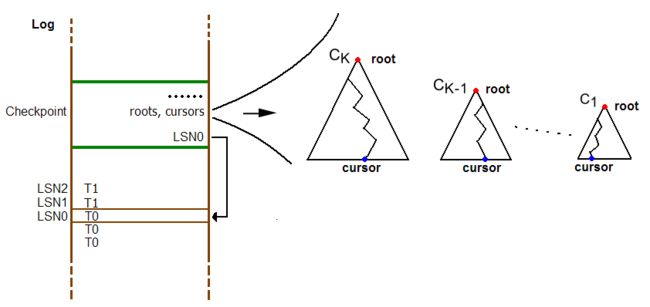
图8:Checkpoint
一旦检查点的信息设置完毕,就可以开始执行被推迟的新条目的插入操作了。由于后续合并操作中向硬盘写入多页块时,会将信息写入硬盘中的新位置,所以检查点的信息不会被消除。只有当后续检查点使得过期的多页块作废时,检查点的信息才会被废弃。
恢复
当系统崩溃后重启进行恢复时,需要进行如下操作:
- 在日志中定位一个检查点;
- 将之前写入硬盘的C0和其它部件在内存中缓存的多页块加载到内存中;
- 将日志中在LSN0之后的部分读入内存,执行其中索引条目的插入操作;
- 读取检查点日志中硬盘部件(C1~CK)的根的位置和合并游标,启动滚动合并,覆盖检查点之后的多页块;
- 当检查点之后的所有新索引条目都已插入至LSM-tree且被索引后,恢复即完成。
这一恢复措施的唯一的一个缺点就是恢复的时间可能会比较长,但通常这并不严重。因为内存中的数据可以很快地写入硬盘。当两个相邻的部件进行滚动合并时,新产生的结点将会写入到硬盘中的新位置。这样在将合并产生的结点写入硬盘时,上层结点中指向该结点的指针需要更新为结点的新位置。当正在进行滚动合并,却临时需要设置检查点时,加载进内存的多页块和目录结点都会写入到硬盘中新的位置。这样,在高层的目录结点中指向这些结点的指针同样需要立即更新为硬盘中的新地址。在恢复的过程中需要注意的是目录结点的更新。
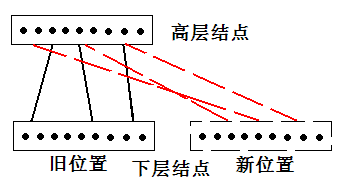
图9:高层结点引用下层结点的新位置
更进一步,当使用检查点进行恢复时,滚动合并所需的所有的多页块都会从硬盘重新读回内存,由于所有的多页块的新位置较之设置检查点时的旧位置都发生了改变,这样所有目录结点的指针都需要更新。这听起来似乎是一大笔性能开销,但这些多页块其实都已加载到内存里了,所以没有I/O开销。若要使得恢复的时间不超过几分钟,那么可以每隔几分钟的I/O操作就设置一次检查点。
小结
日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B-tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入(删除)。然而LSM-tree在某些情况下,特别是在查询需要快速响应时性能不佳。通常LSM-tree适用于索引插入比检索更频繁的应用系统。Bigtable在提供Tablet服务时,使用GFS来存储日志和SSTable,而GFS的设计初衷就是希望通过添加新数据的方式而不是通过重写旧数据的方式来修改文件。而LSM-tree通过滚动合并和多页块的方法推迟和批量进行索引更新,充分利用内存来存储近期或常用数据以降低查找代价,利用硬盘来存储不常用数据以减少存储代价。
参考文献
[1]FAY CHANG,JEFFREY DEAN,SANJAY GHEMAWAT et al.Bigtable: A Distributed Storage System for Structured Data[J].ACM Transactions on Computer Systems,2008,26(2):1-26.
[2]Sanjay Ghemawat,Howard Gobioff,Shun-Tak Leung et al.The Google File System[J].Operating systems review,2003,37(5):29-43.DOI:10.1145/1165389.945450.
[3]O'Neil P;Cheng E;Gawlick D.The log-structured merge-tree[J].Acta Informatica,1996,33(04):351-385.DOI:10.1007/s002360050048.
[4]M.Rosenblum;J.K.Osterhout.The design and implementation of a log-structured file system[J].ACM Trans on Computer Systems vol,1992,10(01):26-52.DOI:10.1145/146941.146943.
[5]O'Neil P; The SB-tree:An index-sequential structure for high-performance sequential access[J].Acta Informatica,1992,29, 241-265