论文笔记《Convolutional Neural Networks for Sentence Classification》
论文地址:http://arxiv.org/pdf/1408.5882
Abstract
摘要里面讲了如下几点:
- 在sentence classfication任务中,我们用cnn进行了一系列实验。
- 直接用word2vec得到的static vectors,超参不怎么调就能得到比较好的结果。
- 对word2vec的word vectors进行针对性的fine-tuning,会得到更好的结果。
- 另外,对cnn模型进行了小改动:将static vectors和non static vectors变成cnn模型中的两个channels,尤如图像中的rgb三通道。
- 测试了7个tasks,有4个tasks得到state of art的结果,其中包括sentiment analysis和question classification。
Model
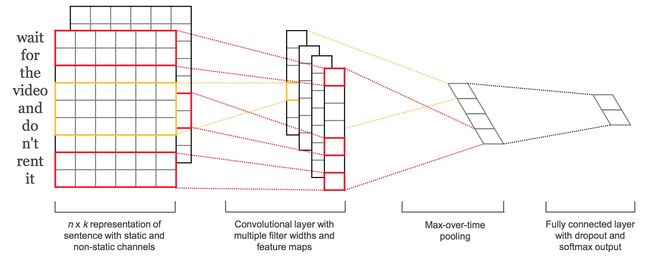
整个论文中用到的cnn模型就是这样的。
xi∈Rk xi∈Rk表示一个sentence中的第i个word,记为 xi xi,它是一个k维的词向量。上图中,一排就代表一个词向量。
一个sentence中的word个数为n。
关于convolution
filter: w∈Rhk w∈Rhk意思是作为filter的权重矩阵是h*k的。如果h=2,就是相邻的两个word做一次卷积,如果h=3,即为3个word做一次卷积,以此类推。
卷积之后的结果再经过激活函数 f f就得到了feature,记为 ci ci。它是由 xi:i+h−1 xi:i+h−1相邻的h个words卷积得到的值,再activation之后的值,也是当前层的输出。
卷积之后的值: w⋅xi:i+h−1+b w⋅xi:i+h−1+b
输出的feature值 ci=f(w⋅xi:i+h−1+b) ci=f(w⋅xi:i+h−1+b)
窗口大小: h h
这样之后,一个n长度的sentence就有[ x1:h x1:h, x2:h+1 x2:h+1, x3:h+2 x3:h+2,…, xn−h+1:n xn−h+1:n]这些word windows,卷积后的结果就是 c c = [ c1,c2,…,cn−h+1 c1,c2,…,cn−h+1],维度为(1,n-h+1)
然后进行池化max pooling,选出最重要的feature。pooling scheme可以根据句子的长度来选择。
关于feature
一个filter只能提取一种feature,论文中的model用多种filter(不同的window size)来获取多种features。
关于two channels of word vectors
one channel将word2vec得到的结果直接static的传入整个模型,另一个channel在BP训练过程中要进行fine-tune。每一个filter都要分别应用到这两个channels上。
例如上图中就能看出,系统有2 filters,对2个channels分别卷积后得到4 stacks。
Regularization
一句话总结,dropout+l2-norm。
dropout
有一点需要注意:
train time按一定概率p对每层的输入神经元进行dropout。
test time时将学到的weights rescale成 ŵ =p∗w w^=p∗w,得到的 ŵ w^应用于unseen sentences,期间不需要dropout。
L2 norm
|w|2=s |w|2=s whenever |w|2>s |w|2>s
Datasets and Experimental Setup
MR : Movie reviews. positive/negative
SST-1 : an extention of MR with train/dev/test splits and very fine-grained labels.
SST-2 : same as SST-1 but without neutral reviews.
Subj : classify a sentence as being subjective or objective.
TREC : classify a question into 6 question types.
CR : customer reviews. predict positive or negative.
MPQA : opinion polarity detection.
Hyperparameters and Training
- rectified linear units
- filter windows(h) : 3, 4, 5
- 100 feature maps for each filter window
- mini-batch size : 50
- adadelta update rule
以上参数是由grid search 在SST-2 dev set上选出来的。
所做的唯一dataset-specific fining : early stopping on dev set
Pre-trained Word Vectors
当手头上没有large supervised training dataset的时候,用word2vec(或相似的unsupervised nlp模型得到)初始化word vectors能提高performance。
word2vec vectors
- publicly available
- trained on 100 billion words from Goo
- dimension of 300
- 没出现在如word2vec这类pre-trained set中的words将随机初始化
Model Variations
- CNN-rand : 所有的word vector都是随机初始化的,在训练过程中更新
- CNN-static : word vector用word2vec得出的结果,在整个train process中所有的words保持不变,只学习其他参数
- CNN-non-static : pretrained vector在训练过程中要被fine-tuned
- CNN-multichannel : two sets of word vectors. 初始化时两个channel都直接赋值word2vec得出的结果,每个filter也会分别applied到两个channel,但是训练过程中只有一个channel会进行BP
模型中除了这些参数改变,其他参数相同。
Results and Discussion
用了pre-trained vectors(cnn-static)就有明显的提高。pretrained vector相当于“universal” feature extractors,fine-tuned后可以在很多tasks上表现出色。
Multichannel vs. Single Channel Models
一句话总结,加一个通道之后的效果是mixed。
Static vs. Non-static Representations
一句话,non-static更适应specific task
Further Observations
- Max-TDNN效果只有37.4%但是我们有45%的原因是我们的cnn有更大的capacity,多个filter width(3,4,5)和多个feature maps(100)
- dropout是很棒的regularization方法,可以使得network更大也不会过拟合,大概有2%-4%的提升。
- Adadelta和Adagrad得到的结果差不多,但是fewer epochs