第一篇 Oracle体系结构总览(整理)
第一篇 Oracle架构总览
先让我们来看一张图
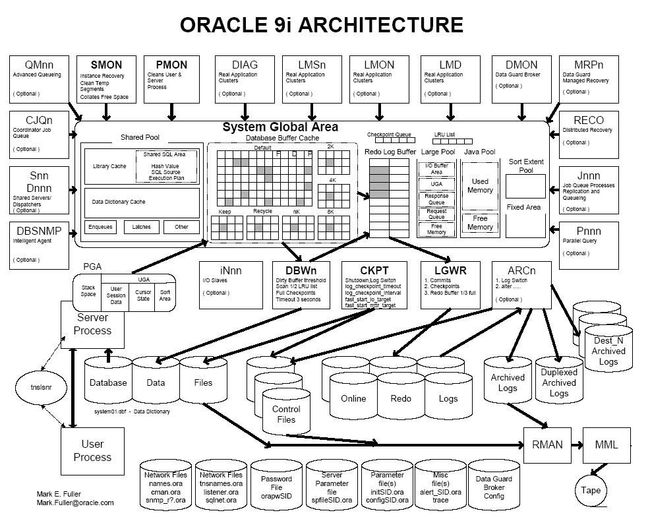
这张就是Oracle 9i的架构全图。看上去,很繁杂。是的,是这样的。现在让我们来梳理一下:
一、数据库、表空间、数据文件
1.数据库
数据库是数据集合。Oracle是一种数据库管理系统,是一种关系型的数据库管理系统。
通常情况了我们称的“数据库”,并不仅指物理的数据集合,他包含物理数据、数据库管理系统。也即物理数据、内存、操作系统进程的组合体。
数据库的数据存储在表中。数据的关系由列来定义,即通常我们讲的字段,每个列都有一个列名。数据以行(我们通常称为记录)的方式存储在表中。表之间可以相互关联。以上就是关系模型数据库的一个最简单的描述。
当然,Oracle也是提供对面象对象型的结构数据库的最强大支持,对象既可以与其它对象建立关系,也可以包含其它对象。关于OO型数据库,以后利用专门的篇幅来讨论。一般情况下我们的讨论都基于关系模型。
2.表空间、文件
无论关系结构还是OO结构,Oracle数据库都将其数据存储在文件中。数据库结构提供对数据文件的逻辑映射,允许不同类型的数据分开存储。这些逻辑划分称作表空间。
表空间(tablespace)是数据库的逻辑划分,每个数据库至少有一个表空间(称作SYSTEM表空间)。为了便于管理和提高运行效率,可以使用一些附加表空间来划分用户和应用程序。例如:USER表空间供一般用户使用,RBS表空间供回滚段使用。一个表空间只能属于一个数据库。
每个表空间由同一磁盘上的一个或多个文件组成,这些文件叫数据文件(datafile)。一个数据文件只能属于一个表空间。在Oracle7.2以后,数据文件创建可以改变大小。创建新的表空间需要创建新的数据文件。
数据文件一旦加入到表空间中,就不能从这个表空间中移走,也不能与其它表空间发生联系。
如果数据库存储在多个表空间中,可以将它们各自的数据文件存放在不同磁盘上来对其进行物理分割。在规划和协调数据库I/O请求的方法中,上述的数据分割是一种很重要的方法。数据库、表空间、文件之间的关系如下图所示:

二、数据库实例
为了访问数据库中的数据,Oracle使用一组所有用户共享的后台进程。此外,还有一些存储结构(统称为System Gloabl Area,即SGA),用来存储最近从数据库查询的数据。数据块缓存区和SQL共享池(Shared SQL Pool)是SGA的最大部分,一般占SGA内存的95%以上。通过减少对数据文件的I/O次数,这些存储区域可以改善数据库的性能。
数据库实例(instance)也称作服务器(server),是用来访问数据库文件集的存储结构及后台进程的集合。一个数据库可以被多个实例访问(这是Oracle并行服务器选项)。实例与数据库的关系如下图所示:

决定实例大小及组成的参数存储的init.ora文件中(在9i中是spfile)。实例启动时需要读这个文件,并且在运行时可以由数据库管理员修改。对该文件的任何修改都只有在下一次启动时才启作用。实例的init.ora文件件通常包含实例的名字:如果一个实例名为orcl,那么init.ora文件通常被命名为initorcl.ora。另一个配置文件config.ora用来存放在数据库创建后就不再改变的变量值(如数据库的块大小)。实例的config.ora文件通常也包含该实例的名字:如果实例的名字为orcl,则config.ora一般将被命名为configorcl.ora。为了便于使用config.ora文件的设置值,在实例的init.ora文件中,该文件必须通过IFILE参数作为包含文件列出。
-----------------------------------------
注:关于初始化参数文件,再另起篇幅详细介绍。
-----------------------------------------
通过以上对数据库及实例的介绍,Oracle数据库结构可分为三个范畴:
数据库内部结构(如表)
存储区内部的结构(包括共享存储区和进程)
数据库的外部结构
三、数据库的内部结构
即Oracle数据的逻辑表现层,也称oracle schema,包括以下这些内容:
表、列、约束条件、数据类型(包括抽象数据类型)
分区与子分区
用户与模式
索引、簇和散列簇
视图
序列
过程、函数、软件包和触发器
同义词
权限及角色
数据库链接
段、盘区和块
回滚段
快照与显形图
各部分的具体介绍以后将在Oralce schema栏目中讨论。
四、Oracle内部存储结构
包括内存缓冲池与后台进程:
1.系统全局区(SGA),主要包括:
a. 数据块缓存区
数据块缓存区(data block buffer cache)是S G A中的一个高速缓存区域,用来存储从数据库中读取数据段的数据块(如表、索引和簇)。数据块缓存区的大小由数据库服务器i n i t . o r a文件中的DB_LOCK_BUFFERS参数决定(用数据库块的个数表示)。在调整和管理数据库时,调整数据块缓存区的大小是一个重要的部分。
因为数据块缓存区的大小固定,并且其大小通常小于数据库段所使用的空间,所以它不能一次装载下内存中所有的数据库段。通常,数据块缓存区只是数据库大小的1 %~2 %,O r a c l e使用最近最少使用( L R U,least recently used)算法来管理可用空间。当存储区需要自由空间时,最近最少使用块将被移出,新数据块将在存储区代替它的位置。通过这种方法,将最频繁使用的数据保存在存储区中。
然而,如果S G A的大小不足以容纳所有最常使用的数据,那么,不同的对象将争用数据块缓存区中的空间。当多个应用程序共享同一个S G A时,很有可能发生这种情况。此时,每个应用的最近使用段都将与其他应用的最近使用段争夺S G A中的空间。其结果是,对数据块缓存区的数据请求将出现较低的命中率,导致系统性能下降。
b. 字典缓存区
数据库对象的信息存储在数据字典表中,这些信息包括用户帐号数据、数据文件名、段名、盘区位置、表说明和权限,当数据库需要这些信息(如检查用户查询一个表的授权)时,将读取数据字典表并且将返回的数据存储在字典缓存区的S G A中。
数据字典缓存区通过最近最少使用(LRU) 算法来管理。字典缓存区的大小由数据库内部管理。字典缓存区是S Q L共享池的一部分,共享池的大小由数据库文件i n i t . o r a中的S H A R E D_PO O L_S I Z E参数来设置。
如果字典缓存区太小,数据库就不得不反复查询数据字典表以访问数据库所需的信息,这些查询称为循环调用(recuesive call),这时的查询速度相对字典缓存区独立完成查询时要低。
c. 重做日志缓冲区
重做项描述对数据库进行的修改。它们写到联机重做日志文件中,以便在数据库恢复过程中用于向前滚动操作。然而,在被写入联机重做日志文件之前,事务首先被记录在称作重做日志缓冲区(redo log buff e r )的S G A中。数据库可以周期地分批向联机重做日志文件中写重做项的内容,从而优化这个操作。
重做日志缓冲区的大小(以字节为单位)由i n i t . o r a文件中的L O G _ B U F F E R参数决定。
d. SQL共享池
S Q L共享池存储数据字典缓存区及库缓存区(library cache),即对数据库进行操作的语句信息。当数据块缓冲区和字典缓存区能够共享数据库用户间的结构及数据信息时,库缓存区允许共享常用的S Q L语句。
S Q L共享池包括执行计划及运行数据库的S Q L语句的语法分析树。在第二次运行(由任何用户)相同的S Q L语句时,可以利用S Q L共享池中可用的语法分析信息来加快执行速度。
S Q L共享池通过L R U算法来管理。当S Q L共享池填满时,将从库缓存区中删掉最近最少使用的执行路径和语法分析树,以便为新的条目腾出空间。如果S Q L共享池太小,语句将被连续不断地再装入到库缓存区,从而影响操作性能。
S Q L共享池的大小(以字节为单位)由i n i t . o r a文件参数S H A R E D _ P O O L _ S I Z E决定。
e. 大池
大池( L a rge Pool)是一个可选内存区。如果使用线程服务器选项或频繁执行备份/恢复操作,只要创建一个大池,就可以更有效地管理这些操作。大池将致力于支持S Q L大型命令。利用大池,就可以防止这些S Q L大型命令把条目重写入S Q L共享池中,从而减少再装入到库缓存区中的语句数量。大池的大小(以字节为单位)通过init. ora文件的L A R G E _ P O O L _ S I Z E参数设置,用户可以使用i n i t . o r a文件的L A R G E _ P O O L _ M I N _ A L L O C参数设置大池中的最小位置。O r a c l e 8 i已不用这个参数。
作为使用L a rge Pool 的一种选择方案,可以用i n i t . o r a文件的S H A R E D _ P O O L _R E S E RV E D _ S I Z E参数为S Q L大型语句保留一部分S Q L共享池。
f. Java 池
由其名字可知, Java 池为J a v a命令提供语法分析。Java 池的大小(以字节为单位)通过在O r a c l e 8 i引入的i n i t . o r a文件的J AVA _ P O O L _ S I Z E参数设置。i n i t . o r a文件的J AVA _ P O O L _ S I Z E参数缺省设置为1 0 M B。
g. 多缓冲池
可以在S G A中创建多个缓冲池,能够用多个缓冲池把大数据集与其他的应用程序分开,以减少它们争夺数据块缓存区内相同资源的可能性。对于创建的每一个缓冲池,都要规定其L R U锁存器的大小和数量。缓冲区的数量必须至少比L R U锁存器的数量多5 0倍。
创建缓冲池时,需要规定保存区(keep area)的大小和再循环区(recycle area)的大小。与S Q L共享池的保留区一样,保存区保持条目,而再循环区则被频繁地再循环使用。可以通过B U F F E R _ P O O L _ K E E P参数规定来保存区的大小。例如:
保存和再循环缓冲池的容量减少了数据块缓冲存储区中的可用空间(通过D B _ B L O C K _B U F F E R S参数设置)。对于使用一个新缓冲池的表,通过表的s t o r a g e子句中的b u ff e r _ p o o l参数来规定缓冲池的名字。例如,如果需要从内存中快速删除一个表,就把它赋予R E C Y C L E池。缺省池叫作D E FA U LT,这样就能在以后用alter table命令把一个表转移到D E FA U LT池。
2.程序全局区( P G A )。
程序全局区( P G A,Program Global Area)是存储区中的一个区域,由一个O r a c l e用户进程
所使用,P G A中的内存不能共享。
3.环境区
4.后台进程
数据库拥有多个后台进程,其数量取决于数据库的配置。这些进程由数据库管理,它们只需要进行很少的管理。
每个后台进程创建一个跟踪文件。在实例操作期间保存跟踪文件。后台进程跟踪文件的命名约定和位置随操作系统和数据库版本而不同。一般来说,跟踪文件含有后台进程名或后台进程的操作系统进程ID。可以设置初始化参数文件的BACKGROUND_DUMP_DEST参数来规
定后台进程跟踪文件的位置,但是有些版本的O r a c l e忽略这种设置。排除数据库故障时,跟踪文件就显得非常重要。影响后台进程的严重问题通常记录在数据库的警告日志上。
警告日志通常位于BACKGROUND_DUMP_DEST目录下。一般来说,这个目录是
ORACLE_BASE目录下的/ADMIN/INSTANCE_NAME/BDUMP目录。
a. SMON
当启动一个数据库时, SMON(System Monitor,系统监控程序)进程执行所需的实例恢复
操作(使用联机重做日志文件),它也可以清除数据库,取消系统不再需要的事务对象。
S M O N的另一个用途是:将邻接的自由盘区组成一个较大的自由盘区。对于某些表空间,数据库管理员必须手工执行自由空间合并;S M O N只合并表空间中的自由空间,这些表空间的缺省
p c t i n c r e a s e存储值为非零。
b. PMON
P M O N (进程监控程序)后台进程清除失败用户的进程,释放用户当时正在使用的资源。当一个持有锁的进程被取消时,其效果是显而易见的, P M O N负责释放锁并使其可以被其他用户使用。同S M O N一样,P M O N周期性地唤醒检测它是否需要被使用。
c. DBWR
D B W R (数据库写入程序)后台进程负责管理数据块缓存区及字典缓存区的内容。它以批方式把修改块从S G A写到数据文件中。
尽管每一个数据库实例只有一个S M O N和一个P M O N进程在运行,但是根据平台和操作系统的不同,用户可以同时拥有多个D B W R进程。使用多个D B W R进程有助于在进行大的操作期间减少D B W R 中的冲突。所需D B W R 进程的数量由数据库的i n i t . o r a 文件中的D B _ W R I T E R _ P R O C E S S E S参数决定。如果系统支持异步I / O,可以用多个DBWR I/O 从( s l a v e )进程创建一个D B W R进程。DBWR I/O 从进程的数量由i n i t . o r a文件的D B W R _ I / O _ S L AV E S参数设置。
如果创建多个D B W R进程,这些进程就不叫做D B W R,它们将有一个数字分量。例如,如果创建5个D B W R进程,进程的操作系统名就可能是D B W 0、D B W 1、D B W 2、D B W 3和D B W 4。
d. LGWR
L G W R (日志写入程序)后台进程负责把联机重做日志缓冲区的内容写入联机重做日志文件。L G W R分批将日志条目写入联机重做日志文件。重做日志缓冲区条目总是包含着数据库的最新状态,这是因为D B W R进程可以一直等待到把数据块缓冲区中的修改数据块写入到数据文件中。
L G W R是数据库正常操作时唯一向联机重做日志文件写入内容并从重做日志缓冲区直接读取内容的进程。与D B W R对数据文件执行的完全随机访问相反,联机重做日志文件以序列形式写入。如果联机重做日志文件是镜像文件, L G W R同时向镜像日志文件中写内容。
对于O r a c l e 8,可以创建多个LGWR I/O从进程以改善向联机重做日志文件的写入性能,其个数由数据库的i n i t . o r a文件的L G W R _ I O _ S L AV E S参数决定。
在O r a c l e 8 i中,这个参数已不能用, LGWR I/O从进程由D B W R _ I O _ S L AV E S设置值派生
而来。
e. CKPT
C K P T (检查点进程)用来减少执行实例恢复所需的时间。检查点使D B W R把上一个检查点以后的全部已修改数据块写入数据文件,并更新数据文件头部和控制文件以记录该检查点。
当一个联机重做日志文件被填满时,检查点进程会自动出现。可以用数据库实例的i n i t . o r a文件中的L O G _ C H E C K P O I N T _ I N T E RVA L参数来设置一个频繁出现的检查点。
C K P T后台进程把早期数据库版本中L G W R的两个功能(向检查点发信号及复制日志内容)分成两个后台进程。当数据库实例的i n i t . o r a文件中的C H E C K P O I N T _ P R O C E S S参数被设置为T R U E时,就可以建立C K P T后台进程。
f. ARCH
L G W R后台进程以循环方式向联机重做日志文件写入;当填满第一个日志文件后,就开始向第二个日志文件写入;第二个日志文件填满后,再向第三个日志文件写入。一旦最后一个重做日志文件填满, L G W R就开始重写第一个重做日志文件的内容。
当O r a c l e以A R C H I V E L O G (归档日志)模式运行时,数据库在开始重写重做日志文件之前先对其进行备份。这些归档的重做日志文件通常写入一个磁盘设备中。也可以直接写入磁带设备中,但是这往往要增加操作员的劳动强度。
这种归档功能由A R C H (归档进程)后台进程完成,利用该性能的数据库在处理大数据事务时将遇到重做日志磁盘冲突问题,这是因为当L G W R准备写入一个重做日志文件时, A R C H正准备读取另一个。如果归档日志目标磁盘写满,数据库还将遇到数据库锁定问题。此时,A R C H冻结,禁止L G W R写入;从而禁止在数据库中出现进一步的事务处理;这种情况一起延续到归档重做日志文件的空间清空为止。
对于O r a c l e 8,可以创建多个ARCH I/O从进程以改善对归档重做日志文件的写入功能。在O r a c l e 8 . 0中,ARCH I/O从进程的个数由数据库的i n i t . o r a文件中的A R C H _ I O _ S L AV E S参数决定。在O r a c l e 8 i中,这个参数已不能用, A R C H _ I O _ S L AV E S设置值由D B W R _ I O _ S L AV E S设置值派生。
g. RECO
R E C O (恢复进程)后台进程用于解决分布式数据库中的故障问题。R E C O进程试图访问存在疑问的分布式事务的数据库并解析这些事务。只有在平台支持Distributed Option(分布式选项)且i n i t . o r a文件中的D I S T R I B U T E D _ T R A N S A C T I O N S参数大于零时才创建这个进程。
h. SNPn
O r a c l e的快照刷新及内部作业队列调度依赖于它们执行的后台进程(快照进程)。这些后台进程的名字以字母S N P开头,以数字或字母结束。为一实例所创建的S N P进程的个数由数据库的i n i t . o r a文件中的J O B _ Q U E U E _ P R O C E S S E S 参数决定(在O r a c l e 7 中,该参数名为S N A P S H O T _ R E F R E S H _ P R O C E S S E S )。
i. LCKn
当采用O r a c l e并行服务器选项时,多个L C K (锁定进程)后台进程(命名为L C K 0 ~ L C K 9 )用于解决内部实例的锁定问题。L C K进程的个数由G C _ L C K _ P R O C S参数决定。
j . Dn n n
D n n n(调度程序进程)是M T S结构的一部分;这些进程有助于减少处理多重连接所需要的资源。对于数据库服务器支持的每一个协议必须至少创建一个调度程序进程,调度程序进程根据S Q L * N e t (或N e t 8 )的配置在数据库启动时创建,在数据库打开后可以创建或取消。
k. Sn n n
创建Sn n n(服务器进程)来管理需要专用服务器的数据库连接。服务器进程可以对数据文件进行I / O操作。
l. P n n n
如果启动数据库中的并行查询选项,一个查询的资源要求可以分布在多个处理器中。当实例启动由init. ora文件的PA R A L L E L _ M I N _ S E RV E R S参数确定时,指定数目的并行查询服务器进程就启动。每一个这样的进程都将出现在操作系统级。需要并行操作的进程越多,启动的并行查询服务器进程就越多。每个并行查询服务器进程在操作系统级将有一个P 0 0 0、P 0 0 1、P 0 0 2这样的名字。并行查询服务器进程的最大数量由init. ora 文件的PA R A L L E L _ M A X _S E RV E R S参数确定。
五、Oracle的外部结构
1. 重做日志
O r a c l e保存所有数据库事务的日志。这些事务被记录在联机重做日志文件(online redo logf i l e )中。当数据库被破坏时,这些日志文件能够以正确顺序恢复数据库事务。重做日志文件信息存储在数据库数据文件的外部。
重做日志文件也可以让O r a c l e优化向磁盘写入数据的方式。当数据库中出现一个事务时,就把该事务输入到重做日志缓冲区;同时受该事务影响的数据块不会立即写入磁盘。
每个O r a c l e数据库都有两个或更多的联机重做日志文件。O r a c l e以循环方式向联机重做日志文件写入:第一个日志文件被填满后,就向第二个日志文件写入,然后依次类推。当所有联机重做日志文件都被填满时,就又回到第一个日志文件,用新事务的数据对其进行重写。如果数据库正以A R C H I V E L O G模式运行,在重写联机重做日志文件前,数据库将先对其进行备份。任何时候都可以用这些归档重做日志文件来恢复数据库的任何部分。
重做日志文件可以被数据库镜像(复制)。镜像联机重做日志文件不依赖操作系统或操作环境的硬件性能就可以对重做日志文件进行镜像。
2. 控制文件
数据库的全局物理结构由其控制文件(control file)维护。控制文件记录数据库中所有文件的控制信息。控制文件维护内部的一致性并引导恢复操作。
由于控制文件对数据库至关重要,所以联机存储着多个拷贝。这些文件一般存储在各个不同的磁盘上,以便将因磁盘失效引起的潜在危险降至最低限度。创建数据库时,同时就提供与之对应的控制文件。
数据库控制文件的名字通过init. ora文件的C O N T R O L _ F I L E S参数规定。尽管这是一个i n i t . o r a参数,但是C O N TO R L _ F I L E S参数通常用c o n f i g . o r a文件规定,因为它很少变化。如果需要给数据库添加一个新的控制文件,可关闭实例,把已存在的一个控制文件复制到新的地址,把新的地址添加到C O N T R O L _ F I L E S参数设置值上,并重新启动这个实例。
3. 跟踪文件与警告日志
在实例中运行的每一个后台进程都有一个跟踪文件与之相连。跟踪文件记载后台进程遇到的重大事件的信息。除了跟踪文件外, O r a c l e还有一个称作警告日志(alert log)的文件,警告日志记录数据库文件运行中主要事件的命令及结果。例如,表空间的创建、重做日志的转换、操作系统的恢复、数据库的建立等信息都记录在警告日志中。警告日志是数据库每日管理的重要资源,当需要查找主要失败原因时,跟踪文件就非常有用。
应经常监控警告日志。警告日志的条目将通知你数据库操作期间遇到的任何问题,其中包括出现的任何O R A _ 0 6 0 0内部错误。为使警告日志便于使用,最好是每天能自动对其重新命名。例如,如果警告日志称作a l e r t _ o r c l . l o g,可以对它重新命名,以便其文件名包括当前日期。下次O r a c l e要写该警告日志时,将找不到具有a l e r t _ o r c l . l o g文件名的文件,因此数据库将创建一个新的文件名。这样,除了有以前的警告日志外,还有一个当前的警告日志( a l e r t _ o r c l . l o g )。用这种方式区分警告日志条目就可以使对警告日志条目的分析更有效。
----------------------------------end--------------------------------------------