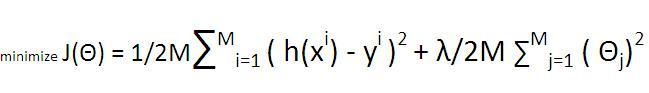(This article was originally published at The Chemical Statistician » Statistics, and syndicated at StatsBlogs.)
Overfitting occurs when a statistical model or machine learning algorithm captures the noise of the data. Intuitively, overfitting occurs when the model or the algorithm fits the data too well. Specifically, overfitting occurs if the model or algorithm shows low bias buthigh variance. Overfitting is often a result of an excessively complicated model, and it can be prevented by fitting multiple models and using validation or cross-validation to compare their predictive accuracies on test data.
Underfitting occurs when a statistical model or machine learning algorithm cannot capture the underlying trend of the data. Intuitively, underfitting occurs when the model or the algorithm does not fit the data well enough. Specifically, underfitting occurs if the model or algorithm shows low variance but high bias. Underfitting is often a result of an excessively simple model.
Both overfitting and underfitting lead to poor predictions on new data sets.
In my experience with statistics and machine learning, I don’t encounter underfitting very often. Data sets that are used for predictive modelling nowadays often come with too many predictors, not too few. Nonetheless, when building any model in machine learning for predictive modelling, use validation or cross-validation to assess predictive accuracy – whether you are trying to avoid overfitting or underfitting.
Addition(Refer from http://en.wikipedia.org/wiki/Supervised_learning):
Bias-variance tradeoff: A first issue is the tradeoff between bias and variance.[2] Imagine that we have available several different, but equally good, training data sets. A learning algorithm is biased for a particular input if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for . A learning algorithm has high variance for a particular input if it predicts different output values when trained on different training sets. The prediction error of a learned classifier is related to the sum of the bias and the variance of the learning algorithm.[3] Generally, there is a tradeoff between bias and variance. A learning algorithm with low bias must be "flexible" so that it can fit the data well. But if the learning algorithm is too flexible, it will fit each training data set differently, and hence have high variance. A key aspect of many supervised learning methods is that they are able to adjust this tradeoff between bias and variance (either automatically or by providing a bias/variance parameter that the user can adjust).
---------------------------------------------------------------------------------------------------------------------------------------
refer from http://www.analyticbridge.com/profiles/blogs/underfitting-overfitting-problem-in-m-c-learning
Underfitting : If our algorithm works badly with points in our data set, then the algorithm underfitting the data set. It can be check easily throug the cost function measures. Cost function in linear regression is half the mean squared error ex. if mean squared error is c the cost fucntion is 0.5C 2. If in an experiment cost ends up high even after many iterations, then chances are we have an underfitting problem. We can say that learning algorithm is not good for the problem. Underfitting is also known as high bias( strong bias towards its hypothesis). In an another words we can say that hypothesis space the learning algorithm explores is too small to properly represent the data.
How to avoid underfitting :
More data will not generally help. It will, in fact, likely increase the training error. Therefore we should increase more features. Because that expands the hypothesis space. This includes making new features from existing features. Same way more parameteres may also expand the hypothesis space.
Overfitting : If our algorithm works well with points in our data set, but not on new points, then the algorithm overfitting the data set. Overfitting check easily through by spliting the data set so that 90% of data in our training set and 10% in a cross-validation set. Train on the training set, then measure the cost on the cross-validation set. If the cross-validation cost is much higher than the training cost, then chances are we have an overfitting problem. In another words we can say that hypothesis space is too large, and perhaps some features are faking the learning algorithm out.
How to avoid overfitting :
To avoid overfitting add the regularization if there are many features. Regularization forces the magnitudes of the parameters to be smaller(shrinking the hypothesis space). For this add a new term to the cost function
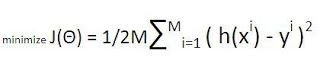
which penalizes the magnitudes of the parameters like as