本文由 Migrant 翻译自 The Foundation Collection Classes,转载请注明出处。
NSArray, NSSet, NSOrderedSet 和 NSDictionary
基础集合类是每一个Mac/iOS应用的基本组成部分。在本文中,我们将对”老类”(NSArray, NSSet)和”新类”(NSMapTable, NSHashTable, NSPointerArray)进行一个深入的研究,探索每一个的效率细节,并讨论其使用场景。
作者提示:本文包含一些参照结果,但它们并不意味着绝对精确,也没有进行多个、复杂的测试。这些结果的目的是给出一个快速和主要的运行时统计。所有的测试基于iPhone 5s,使用Xcode 5.1b1和iOS 7.1b1,64位的程序。编译选项设置为-Ofast的发布构建。Vectorize loops和unroll loops(默认设置)均设置为关闭。
大O符号
首先,我们需要一些理论知识。效率通常用大O符号描述。它定义了一个函数的 极限特征 ,通常被用于描绘其算法效率。O定义了函数增长率的上限。通过查看通常使用的O符号和所需要的操作数来查看差异的大小。
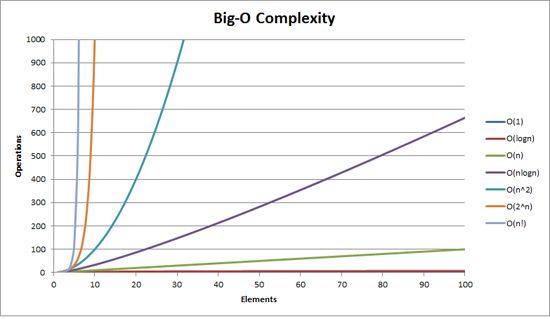
例如,如果用算法复杂度为O(n2)的算法对一个有50个元素的数组排序,需要2500步的操作。而且,还有内部的系统开销和方法调用 — 所以是2500个操作的时间常量。 O(1)是理想的复杂度,代表着恒定的时间。好的算法通常需要O(n*log n)的时间。
可变性
大多数的集合类存在两个版本:可变和不可变(默认)。这和其他大多数的框架有非常大的不同,一开始会让人觉得有一点奇怪。然而其他的框架现在也应用了这一特性:就在几个月前,.NET公布了作为官方扩展的不可变集合。
最大的好处是什么?线程安全。不可变的集合完全是线程安全的,可以同时在多个线程中迭代,避免各种突变异常的风险。你的API 绝不 应该暴露可变集合。
当然从不可变到可变再变回来会有一定的代价 — 对象必须被拷贝两次,所有集合内的对象将被retain/release。有时在内部使用一个可变的集合而在出口返回一个不可变的对象副本会更高效。
与其他框架不同,苹果没有提供一个线程安全的可变集合,NSCache是例外 — 但它真的算不上是集合类,因为它不是一个通用的容器。大多数时候,你的确想要高于集合级别的同步。想象一段代码,作用是检查字典中一个key是否存在,并根据检查结果决定设置一个新的key或者返回某些值 — 你通常需要把多个操作归类,这时线程安全的可变变体并不能帮助你。
这里有一些同步的,线程安全的可变集合有效的使用案例,只需要用几行代码,通过子类和组合的方法建立诸如NSDictionary或NSArray。
需要注意的是,一些更新式的集合类,如NSHashTable,NSMapTable和NSPointerArray默认就是可变的,它们并没有对应的不可变的类。它们用于类的内部使用,或者某个你想要不常见的可变类的场景。
NSArray
NSArray作为一个存储对象的有序集合,可能是被使用最多的集合类。这也是为什么它有自己的比原来的[NSArray arrayWithObjects:..., nil]简短得多的快速语法糖符号@[...]。
NSArray实现了objectAtIndexedSubscript:,因为我们可以使用类C的语法array[0]来代替原来的[array objectAtIndex:0]。
性能特征
关于NSArray的内容比你想象的要多的多。基于存储对象的多少,它使用各种内部的变体。最有趣的部分是苹果对于个别的对象访问并不保证O(1)的访问时间 — 正如你在CFArray.h CoreFoundation header中的关于算法复杂度的注解中可以读到的:
The access time for a value in the array is guaranteed to be at worst O(lg N) for any implementation, current and future, but will often be O(1) (constant time). Linear search operations similarly have a worst case complexity of O(Nlg N), though typically the bounds will be tighter, and so on. Insertion or deletion operations will typically be linear in the number of values in the array, but may be O(Nlg N) clearly in the worst case in some implementations. There are no favored positions within the array for performance; that is, it is not necessarily faster to access values with low indices, or to insert or delete values with high indices, or whatever.
在测量的时候,NSArray产生了一些有趣的额外的性能特征。在数组的开头和结尾插入/删除元素通常是一个O(1)操作,而随机的插入/删除通常是 O(N)的。
有用的方法
NSArray的大多数方法使用isEqual:来检查对象间的关系(例如containsObject:)。有一个特别的方法indexOfObjectIdenticalTo:用来检查指针相等,如果你确保在同一个集合中搜索,那么这个方法可以很大的提升搜索速度。
在iOS 7中,我们最终得到了与lastObject对应的公开的firstObject方法,对于空数组,这两个方法都会返回nil — 而常规的访问方法会抛出一个NSRangeException异常。
关于构造(可变)数组有一个漂亮的细节可以节省代码量。如果你通过一个可能为nil的数组创建一个可变数组,通常会这么写:
- NSMutableArray *mutableObjects = [array mutableCopy];
- if (!mutableObjects) {
- mutableObjects = [NSMutableArray array];
- }
或者通过更简洁的三元运算符:
- NSMutableArray *mutableObjects = [array mutableCopy] ?: [NSMutableArray array];
更好的解决方案是使用arrayWithArray:,即使原数组为nil,该方法也会返回一个数组对象:
- NSMutableArray *mutableObjects = [NSMutableArray arrayWithArray:array];
这两个操作在效率上几乎相等。使用copy会快一点点,不过话说回来,这不太可能是你应用的瓶颈所在。提醒:不要使用[@[] mutableCopy]。经典的[NSMutableArray array]可读性更好。
翻转一个数组非常简单:array.reverseObjectEnumerator.allObjects。我们使用系统提供的reverseObjectEnumerator,每一个NSEnumerator都实现了allObjects,该方法返回一个新数组。虽然没有原生的randomObjectEnumerator方法,你可以写一个自定义的打乱数组顺序的枚举器或者使用一些出色的开源代码。
数组排序
有很多各种各样的方法来对一个数组排序。如果数组存储的是字符串对象,sortedArrayUsingSelector:是第一选择:
- NSArray *array = @[@"John Appleseed", @"Tim Cook", @"Hair Force One", @"Michael Jurewitz"];
- NSArray *sortedArray = [array sortedArrayUsingSelector:@selector(localizedCaseInsensitiveCompare:)];
下面的代码对存储数字的内容同样很好,因为NSNumber实现了compare::
- NSArray *numbers = @[@9, @5, @11, @3, @1];
- NSArray *sortedNumbers = [numbers sortedArrayUsingSelector:@selector(compare:)];
如果想更可控,可以使用基于函数指针的排序方法:
- - (NSData *)sortedArrayHint;
- - (NSArray *)sortedArrayUsingFunction:(NSInteger (*)(id, id, void *))comparator
- context:(void *)context;
- - (NSArray *)sortedArrayUsingFunction:(NSInteger (*)(id, id, void *))comparator
- context:(void *)context hint:(NSData *)hint;
苹果增加了一个方法来加速使用sortedArrayHint的排序。
The hinted sort is most efficient when you have a large array (N entries) that you sort once and then change only slightly (P additions and deletions, where P is much smaller than N). You can reuse the work you did in the original sort by conceptually doing a merge sort between the N “old” items and the P “new” items. To obtain an appropriate hint, you use sortedArrayHint when the original array has been sorted, and keep hold of it until you need it (when you want to re-sort the array after it has been modified).
因为block的引入,也出现了一些基于block的排序方法:
- - (NSArray *)sortedArrayUsingComparator:(NSComparator)cmptr;
- - (NSArray *)sortedArrayWithOptions:(NSSortOptions)opts
- usingComparator:(NSComparator)cmptr;
性能上来说,不同的方法间并没有太多的不同。有趣的是,基于selector的方式是最快的。你可以在GitHub上找到测试用的源代码:
- Sorting 1000000 elements. selector: 4947.90[ms] function: 5618.93[ms] block: 5082.98[ms].
二分查找
NSArray从iOS 4/Snow Leopard开始内置了二分查找
- typedef NS_OPTIONS(NSUInteger, NSBinarySearchingOptions) {
- NSBinarySearchingFirstEqual = (1UL << 8),
- NSBinarySearchingLastEqual = (1UL << 9),
- NSBinarySearchingInsertionIndex = (1UL << 10),
- };
- - (NSUInteger)indexOfObject:(id)obj
- inSortedRange:(NSRange)r
- options:(NSBinarySearchingOptions)opts
- usingComparator:(NSComparator)cmp;
为什么要使用这个方法?类似containsObject:和indexOfObject:这样的方法从0索引开始搜索每个对象直到找到目标 — 不需要数组被排序而且是O(n)的效率特性。换句话说,二分查找需要数组事先被排序,但只需要O(log n)的时间。因此,对于1,000,000的记录,二分查找法最多只需要21次比较,而传统的线性查找则平均需要5000,000次的比较。
这是个简单的衡量二分查找有多快的数据:
- Time to search for 1000 entries within 1000000 objects. Linear: 54130.38[ms]. Binary: 7.62[ms]
作为比较,查找NSOrderedSet中的指定索引花费0.23毫秒 — 即使跟二分查找相比也快了30多倍。
记住排序的开销也是昂贵的。苹果使用复杂度为O(n*log n)的归并排序,所以如果执行过indexOfObject:一次,就没有必要使用二分查找了。
通过指定NSBinarySearchingInsertionIndex,你可以获得正确的插入索引,以确保在插入元素后仍然可以保证数组的顺序。
枚举和高阶消息
作为参照,我们来看一个普通的使用场景。从一个数组中过滤出另一个数组。测试了多个枚举方法和API特性:
- // First variant, using `indexesOfObjectsWithOptions:passingTest:`.
- NSIndexSet *indexes = [randomArray indexesOfObjectsWithOptions:NSEnumerationConcurrent
- passingTest:^BOOL(id obj, NSUInteger idx, BOOL *stop) {
- return testObj(obj);
- }];
- NSArray *filteredArray = [randomArray objectsAtIndexes:indexes];
- // Filtering using predicates (block-based or text)
- NSArray *filteredArray2 = [randomArray filteredArrayUsingPredicate:[NSPredicate predicateWithBlock:^BOOL(id obj, NSDictionary *bindings) {
- return testObj(obj);
- }]];
- // Block-based enumeration
- NSMutableArray *mutableArray = [NSMutableArray array];
- [randomArray enumerateObjectsUsingBlock:^(id obj, NSUInteger idx, BOOL *stop) {
- if (testObj(obj)) {
- [mutableArray addObject:obj];
- }
- }];
- // Classic enumeration
- NSMutableArray *mutableArray = [NSMutableArray array];
- for (id obj in randomArray) {
- if (testObj(obj)) {
- [mutableArray addObject:obj];
- }
- }
- // Using NSEnumerator, old school.
- NSMutableArray *mutableArray = [NSMutableArray array];
- NSEnumerator *enumerator = [randomArray objectEnumerator];
- id obj = nil;
- while ((obj = [enumerator nextObject]) != nil) {
- if (testObj(obj)) {
- [mutableArray addObject:obj];
- }
- }
- // Using objectAtIndex: (via subscripting)
- NSMutableArray *mutableArray = [NSMutableArray array];
- for (NSUInteger idx = 0; idx < randomArray.count; idx++) {
- id obj = randomArray[idx];
- if (testObj(obj)) {
- [mutableArray addObject:obj];
- }
- }
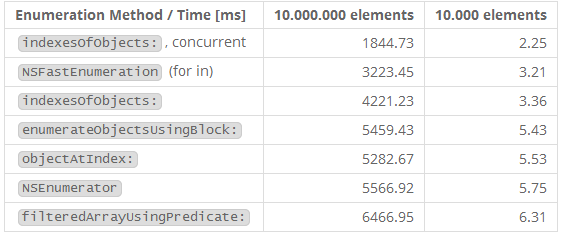
为了更好的理解这里的效率测量,我们首先看一下数组是如何迭代的。
indexesOfObjectsWithOptions:passingTest:必须每次都执行一次block因此比传统的使用NSFastEnumeration技术的基于for循环的枚举要稍微低效一些。然后如果开启了并发枚举,那么前者的速度则会大大的超过后者几乎2倍。iPhone 5s是双核的,所以这说得通。这里并没有体现出来的是NSEnumerationConcurrent只对大量的对象有意义,如果你的集合中的对象数量很少,用哪个方法就真的无关紧要。甚至NSEnumerationConcurrent上额外的线程管理实际上会使结果变得更慢。
最大的输家是filteredArrayUsingPredicate:。NSPredicate需要在这里提及是因为,人们可以写出非常复杂的表达式,尤其是用不基于block的变体。使用Core Data的用户应该会很熟悉。
为了比较的完整,我们也加入了NSEnumerator作为比较 — 虽然没有任何理由再使用它了。然而它竟出人意料的快(比基于NSPredicate的查找要快),它的运行时消耗无疑比快速枚举更多 — 现在它只用于向后兼容。甚至没有优化过的objectAtIndex:都要更快些。
NSFastEnumeration
在OSX 10.5和iOS的最初版本中,苹果增加了NSFastEnumeration。在此之前,只有每次返回一个元素的NSEnumeration,每次迭代都有运行时开销。而快速枚举,苹果通过countByEnumeratingWithState:objects:count:返回一个数据块。该数据块被解析成ids类型的C数组。这就是更快的速度的原因;迭代一个C数组更快,而且可以被编译器更深一步的优化。手动的实现快速枚举是十分难办的,所以苹果的FastEnumerationSample是一个不错的开始,还有一篇Mike Ash的文章也很不错。
应该用arrayWithCapacity:吗?
初始化NSArray的时候,可以选择指定数组的预期大小。在检测的时候,结果是在效率上没有差别 — 测量的时间几乎相等,且在统计不确定性的范围内。有消息透漏说实际上苹果并没有使用这个特性。然而使用arrayWithCapacity:仍然有用,在文档不清晰的代码中,它可以帮助理解代码:
- Adding 10.000.000 elements to NSArray. no count 1067.35[ms] with count: 1083.13[ms].
子类化注意事项
很少有理由去子类化基础集合类。大多数时候,使用CoreFoundation级别的类并且自定义回调函数定制自定义行为是更好的解决方案。
创建一个大小写不敏感的字典,一种方法是子类化NSDictionary并且自定义访问方法,使其将字符串始终变为小写(或大写),并对排序也做类似的修改。更快更好的解决方案是提供一个不同的CFDictionaryKeyCallBacks集,你可以提供自定义的hash和isEqual:回调。你可以在这里找到一个例子。这种方法的优美之处(感谢toll-free bridging)在于它仍然是一个简单的字典,可以被任何使用NSDictionary作为参数的API接受。
子类作用的一个例子是有序字典的用例。.NET提供了一个SortedDictionary,Java有TreeMap,C++有std::map。虽然你 可以 使用C++的STL容器,但却无法使它自动的retain/release,这会使使用起来笨重的多。因为NSDictionary是一个类簇,所以子类化跟人们想象的相比非常不同。这已经超过了本文的讨论范畴,这里有一个真实的有序字典的例子。
NSDictionary
一个字典存储任意的对象键值对。 由于历史原因,初始化方法使用相反的对象到值的方法,[NSDictionary dictionaryWithObjectsAndKeys:object, key, nil],而新的快捷语法则从key开始,@{key : value, ...}。
NSDictionary中的键是被拷贝的并且需要是恒定的。如果在一个键在被用于在字典中放入一个值后被改变,那么这个值可能就会变得无法获取了。一个有趣的细节,在NSDictionary中键是被拷贝的,而在使用一个toll-free桥接的CFDictionary时却只被retain。CoreFoundation类没有通用对象的拷贝方法,因此这时拷贝是不可能的(*)。这只适用于使用CFDictionarySetValue()的时候。如果通过setObject:forKey使用toll-free桥接的CFDictionary,苹果增加了额外处理逻辑来使键被拷贝。反过来这个结论则不成立 — 转换为CFDictionary的NSDictionary对象,对其使用CFDictionarySetValue()方法会调用回setObject:forKey并拷贝键。
(*)有一个现成的键的回调函数kCFCopyStringDictionaryKeyCallBacks会拷贝字符串,因为CFStringCreateCopy()会调用[NSObject copy],我们可以使用这个回调来创建一个拷贝键的CFDictionary。
性能特征
苹果在定义计算复杂度时显得相当安静。关于它的唯一注释可以在CFDictionary的头文件中找到:
The access time for a value in the dictionary is guaranteed to be at worst O(N) for any implementation, current and future, but will often be O(1) (constant time). Insertion or deletion operations will typically be constant time as well, but are O(N*N) in the worst case in some implementations. Access of values through a key is faster than accessing values directly (if there are any such operations). Dictionaries will tend to use significantly more memory than a array with the same number of values.
跟数组相似的,字典根据尺寸的不同使用不同的实现,并在其中无缝切换。
枚举和高阶消息
过滤字典有几个不同的方法:
- // Using keysOfEntriesWithOptions:passingTest:,optionally concurrent
- NSSet *matchingKeys = [randomDict keysOfEntriesWithOptions:NSEnumerationConcurrent
- passingTest:^BOOL(id key, id obj, BOOL *stop)
- {
- return testObj(obj);
- }];
- NSArray *keys = matchingKeys.allObjects;
- NSArray *values = [randomDict objectsForKeys:keys notFoundMarker:NSNull.null];
- __unused NSDictionary *filteredDictionary = [NSDictionary dictionaryWithObjects:values
- forKeys:keys];
- // Block-based enumeration.
- NSMutableDictionary *mutableDictionary = [NSMutableDictionary dictionary];
- [randomDict enumerateKeysAndObjectsUsingBlock:^(id key, id obj, BOOL *stop) {
- if (testObj(obj)) {
- mutableDictionary[key] = obj;
- }
- }];
- // NSFastEnumeration
- NSMutableDictionary *mutableDictionary = [NSMutableDictionary dictionary];
- for (id key in randomDict) {
- id obj = randomDict[key];
- if (testObj(obj)) {
- mutableDictionary[key] = obj;
- }
- }
- // NSEnumeration
- NSMutableDictionary *mutableDictionary = [NSMutableDictionary dictionary];
- NSEnumerator *enumerator = [randomDict keyEnumerator];
- id key = nil;
- while ((key = [enumerator nextObject]) != nil) {
- id obj = randomDict[key];
- if (testObj(obj)) {
- mutableDictionary[key] = obj;
- }
- }
- // C-based array enumeration via getObjects:andKeys:
- NSMutableDictionary *mutableDictionary = [NSMutableDictionary dictionary];
- id __unsafe_unretained objects[numberOfEntries];
- id __unsafe_unretained keys[numberOfEntries];
- [randomDict getObjects:objects andKeys:keys];
- for (int i = 0; i < numberOfEntries; i++) {
- id obj = objects[i];
- id key = keys[i];
- if (testObj(obj)) {
- mutableDictionary[key] = obj;
- }
- }

(*)使用getObjects:andKeys:时需要注意。在上面的代码例子中,我们使用了可变长度数组的C99特性(通常,数组的数量需要是一个固定值)。在栈上分配了内存,虽然有限但是更方便一点。上面的代码在有数量较大的元素的时候会崩溃掉,所以使用基于malloc/calloc的分配(和free)以确保安全。
为什么这次NSFastEnumeration这么慢?迭代字典通常需要键和值;快速枚举只能枚举键,我们必须每次都自己获取值。使用基于block的enumerateKeysAndObjectsUsingBlock:更高效,因为值可以更高效的被提前获取。
这个测试的胜利者又是并发迭代keysOfEntriesWithOptions:passingTest:和objectsForKeys:notFoundMarker:。代码稍微多了一点,但是可以用category进行漂亮的封装。
应该用dictionaryWithCapacity:吗?
到现在你应该已经知道该如何测试了,简单的回答是不,count参数没有改变任何事情:
- Adding 10000000 elements to NSDictionary. no count 10786.60[ms] with count: 10798.40[ms].
排序
关于字典排序没有太多可说的。你只能将键排序为一个新对象,因此你可以使用任何正规的NSArray的排序方法:
- - (NSArray *)keysSortedByValueUsingSelector:(SEL)comparator;
- - (NSArray *)keysSortedByValueUsingComparator:(NSComparator)cmptr;
- - (NSArray *)keysSortedByValueWithOptions:(NSSortOptions)opts
- usingComparator:(NSComparator)cmptr;
共享键
从iOS 6和OS X 10.8开始,字典可以使用一个事先生成好的键集,使用sharedKeySetForKeys:从一个数组中创建键集,用dictionaryWithSharedKeySet:创建字典。共享键集会复用对象,以节省内存。根据Foundation Release Notes,sharedKeySetForKeys:中会计算一个最小最完美的哈希值,这个哈希值丢弃了字典查找过程中探索循环的需要,因此使键的访问更快。
这在JSON解析的时候是完美的使用场景,虽然在我们有限的测试中无法看到苹果在NSJSONSerialization中使用。(使用共享键集创建的字典是NSSharedKeyDictionary的子类;标准的字典是__NSDictionaryI/__NSDictionaryM,I/M表明可变性;toll-free桥接的字典是_NSCFDictionary类,既是可变也是不可变的。)
有趣的细节:共享键字典始终是可变的,即使对它们执行了”copy”命令后。这个行为文档中并没有说明,但很容易被测试:
- id sharedKeySet = [NSDictionary sharedKeySetForKeys:@[@1, @2, @3]]; // returns NSSharedKeySet
- NSMutableDictionary *test = [NSMutableDictionary dictionaryWithSharedKeySet:sharedKeySet];
- test[@4] = @"First element (not in the shared key set, but will work as well)";
- NSDictionary *immutable = [test copy];
- NSParameterAssert(immutable == 1);
- ((NSMutableDictionary *)immutable)[@5] = @"Adding objects to an immutable collection should throw an exception.";
- NSParameterAssert(immutable == 2);
NSSet
NSSet和它的可变变体NSMutableSet是无序对象集合。检查一个对象是否存在通常是一个O(1)的操作,使得比NSArray快很多。NSSet只在被使用的哈希方法平衡的情况下能高效的工作;如果所有的对象都在同一个哈希筐内,NSSet在查找对象是否存在时并不比NSArray快多少。
NSSet还有变体NSCountedSet,non-toll-free计数变体CFBag/CFMutableBag。
NSSet会retain它其中的对象,但是根据set的规定,对象应该是不可变的。添加一个对象到set中随后改变它会导致一些奇怪的问题并破坏set的状态。
NSSet的方法比NSArray少的多。没有排序方法,但有一些方便的枚举方法。重要的方法有allObjects,将对象转化为NSArray,anyObject则返回任意的对象,如果set为空,则返回nil。
Set操作
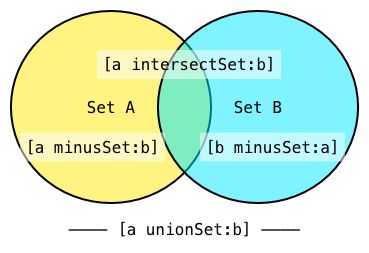
NSMutableSet有几个很强大的方法,例如intersectSet:,minusSet:和unionSet:。
应该用setWithCapacity:吗?
我们再一次测试当创建set时给定容量大小是否会有显著的速度差异:
- Adding 1.000.000 elements to NSSet. no count 2928.49[ms] with count: 2947.52[ms].
在统计不确定性的前提下,结果没有显著差异。有一份证据表明至少在上一运行时版本中,有很多的性能上的影响。
NSSet性能特征
苹果在CFSet头文件中没有提供任何关于算法复杂度的注释:

这个检测非常符合我们的预期:NSSet在每一个被添加的对象上执行hash和isEqual:方法并管理一个哈希筐,所以在添加元素时耗费了更多的时间。set的随机访问比较难以测试,因为这里执行的都是anyObject。
这里没有必要包含containsObject:的测试,set要快几个数量级,毕竟这是它的特点。
NSOrderedSet
NSOrderedSet在iOS 5和Mac OS X 10.7中第一次被引入,除了CoreData,几乎没有直接使用它的API。看上去它综合了NSArray和NSSet两者的好处,对象查找,对象唯一性,和快速随机访问。
NSOrderedSet有着优秀的API方法,使得它可以很便利的与其他set或者有序set对象合作。合并,交集,差集,就像NSSet支持的那样。它有NSArray中的大多数排序方法,除了比较陈旧的基于函数的排序方法和二分查找。毕竟containsObject:非常快,所以没有必要再用二分查找了。
array和set方法分别返回一个NSArray和NSSet,但是。这些对象表面上是对象,像不可变对象那样,在有序set被更新的时候,它们会更新自己。当你打算在多个线程上迭代这些对象并发生了突变异常的时候,了解这一点是有好处的。本质上,这些类使用的是__NSOrderedSetSetProxy和__NSOrderedSetArrayProxy。
附注:如果你想知道为什么NSOrderedSet不是NSSet的子类,NSHipster上有一篇非常好的文章解释了可变/不可变类簇的缺点。
NSOrderedSet性能特征
如果你看到这份测试,你会看到NSOrderedSet代价高昂,天下没有免费的午餐:

这个测试在每一个集合类中添加自定义字符串,随后随机访问它们。
NSOrderedSet比NSSet和NSArray占用更多的内存,因为它需要一起维护哈希值和索引。
NSHashTable
NSHashTable效仿了NSSet,但在对象/内存处理时更加的灵活。可以通过自定义CFSet的回调获得NSHashTable的一些特性,哈希表可以保持对对象的弱引用并在对象被销毁之后正确的将其移除 — 一些手动添加到NSSet的时候非常恶心的事情。它是默认可变的 — 没有相应的不可变类。
NSHashTable有ObjC和原始的C API,C API可以用来存储任意对象。苹果在10.5 Leopard系统中引入了这个类,但是直到最近的iOS 6中才被加入。足够有趣的是它们只移植了 ObjC API;更多强大的C API没有包括在iOS中。
NSHashTable可以通过initWithPointerFunctions:capacity:进行大量的设置 — 我们只选取使用hashTableWithOptions:最普遍的使用场景。最有用的选项有它自己的方便的构造函数weakObjectsHashTable。
NSPointerFunctions
这些指针函数可以被用在NSHashTable,NSMapTable和NSPointerArray中,定义了对存储在这个集合中的对象的获取和保留行为。这里是最有用的选项。完整列表参见NSPointerFunctions.h。
有两组选项。内存选项决定了内存管理,个性化定义了哈希和相等。
NSPointerFunctionsStrongMemory创建了一个retain/release对象的集合,非常像常规的NSSet或NSArray。
NSPointerFunctionsWeakMemory使用等价的__weak来存储对象并自动移除被销毁的对象。
NSPointerFunctionsCopyIn在对象被加入到集合前拷贝它们。
NSPointerFunctionsObjectPersonality使用对象的hash和isEqual:(默认)。
NSPointerFunctionsObjectPointerPersonality对于isEqual:和hash使用直接的指针比较。
NSHashTable性能特征

如果你只是需要NSSet的特性,请坚持使用NSSet。NSHashTable在添加对象时花费了将近2倍的时间,但是其他方面的效率却非常相近。
NSMapTable
NSMapTable和NSHashTable相似,但是效仿的是NSDictionary。因此,我们可以通过mapTableWithKeyOptions:valueOptions:分别控制键和值的对象获取/保留行为。存储弱引用是NSMapTable最有用的特性,这里有4个方便的构造函数:
strongToStrongObjectsMapTable
weakToStrongObjectsMapTable
strongToWeakObjectsMapTable
weakToWeakObjectsMapTable
注意,除了使用NSPointerFunctionsCopyIn,任何的默认行为都会retain(或弱引用)键对象而不会拷贝它,与CFDictionary的行为相同而与NSDictionary不同。当你需要一个字典,它的键没有实现NSCopying协议,比如UIView,的时候非常有用。
如果你好奇为什么苹果”忘记”为NSMapTable增加下标,你现在知道了。下标访问需要一个id<NSCopying>作为key,对NSMapTable来说这不是强制的。如果不通过一个非法的API协议或者移除NSCopying协议来削弱全局下标,是没有办法给它增加下标的。
你可以通过dictionaryRepresentation把内容转换为普通的NSDictionary。不像NSOrderedSet,这个方法返回一个常规的字典而不是一个代理。
NSMapTable性能特征
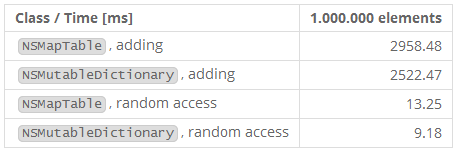
NSMapTable只比NSDictionary略微慢一点。如果你需要一个不retain键的字典,放弃CFDictionary使用它吧。
NSPointerArray
NSPointerArray类是一个稀疏数组,工作起来与NSMutableArray相似,但可以存储NULL值,并且count方法会反应这些空点。可以用NSPointerFunctions对其进行各种设置,也有应对常见的使用场景的快捷构造函数strongObjectsPointerArray和weakObjectsPointerArray。
在能使用insertPointer:atIndex:之前,我们需要通过直接设置count属性来申请空间,否则会产生一个异常。另一种选择是使用addPointer:,这个方法可以自动根据需要增加数组的大小。
你可以通过allObjects将一个NSPointerArray转换成常规的NSArray。这时所有的NULL值会被去掉,只有真正存在的对象被加入到数组 — 因此数组的对象索引很有可能会跟指针数组的不同。注意:如果向指针数组中存入任何非对象的东西,试图执行allObjects都会造成EXC_BAD_ACCESS崩溃,因为它会一个一个的retain”对象”。
从调试的角度讲,NSPointerArray没有受到太多欢迎。description方法只是简单的返回了<NSConcretePointerArray: 0x17015ac50>。为了得到所有的对象需要执行[pointerArray allObjects],当然,如果存在NULL的话会改变索引。
NSPointerArray性能特征
在性能方面,NSPointerArray真的非常非常慢,所以当你打算在一个很大的数据集合上使用它的时候一定要三思。在本测试中我们比较了使用NSNull作为空标记的NSMutableArray和使用了NSPointerFunctionsStrongMemory设置的NSPointerArray(这样对象会被适当的retain)。在一个有10,000个元素的数组中,我们每隔十个插入一个字符串”Entry %d”。此测试包括了用NSNull作为null填充的NSMutableArray。对于NSPointerArray,我们使用setCount:来代替:
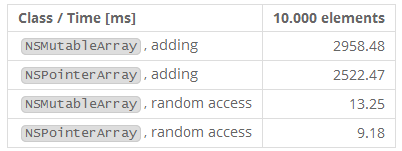
注意NSPointerArray需要的时间比NSMutableArray多了超过250x (!) 。这非常奇怪和意外。跟踪内存比较困难,似乎NSPointerArray更高效,但是因为我们使用同一个NSNull标记空对象,所以除了指针不该有更多的消耗。
NSCache
NSCache是一个非常奇怪的集合。在iOS 4/Snow Leopard中加入,默认为可变并且线程安全的。这使它很适合缓存那些创建起来代价高昂的对象。它自动对内存警告做出反应并基于可设置的”成本”清理自己。与NSDictionary相比,键是被retain而不是被拷贝的。
NSCache的回收方法是不确定的,在文档中也没有说明。向里面放一些类似图片那样比被回收更快填满内存的大对象不是个好主意。(这是在PSPDFKit中很多跟内存有关的crash的原因,在使用自定义的基于LRU的链表的缓存代码之前,我们起初使用NSCache存储事先渲染的图片。)
NSCache可以设置撑自动回收实现了NSDiscardableContent协议的对象。实现该属性的一个比较流行的类是同时间加入的NSPurgeableData,但是在OS X 10.9之前,是非线程安全的(没有信息表明这是否也影响到iOS或者是否在iOS 7中被修复了)。
NSCache性能
那么NSCache如何承受NSMutableDictionary的考验?加入的线程安全必然会带来一些消耗。处于好奇,我也加入了一个自定义的线程安全的字典的子类(PSPDFThreadSafeMutableDictionary),它通过OSSpinLock实现同步的访问。
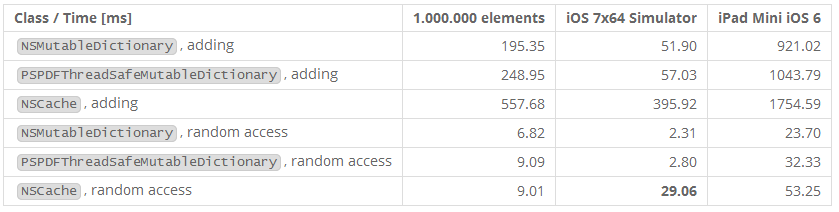
NSCache表现的相当好,随机访问跟我们自定义的线程安全字典一样快。如我们预料的,添加更慢一些,因为NSCache维持着一个可选的决定何时回收对象的成本系数。就这一点来看这不是一个非常公平的比较。有趣的是,在模拟器上运行效率要慢了几乎10倍。无论对32或64位的系统都是。而且看起来已经在iOS 7中优化过并且受益于64位运行时环境。当在老的设备上测试时,使用NSCache的性能消耗尤为明显。
iOS 6(32 bit)和iOS 7(64 bit)的区别也很明显,因为64位运行时使用标签指针,因此我们的@(idx)封装要更为高效。
NSIndexSet
有些使用场景下NSIndexSet(和它的可变变体,NSMutableIndexSet)真的非常出色,对它的使用贯穿在Foundation中。它可以用一种非常高效的方法存储一组无符号整数的集合,尤其是如果只是一个或少量范围的时候。正如set这个名字已经暗示的那样,每一个NSUInteger要么在索引set中要么不在。如果你需要存储任意唯一的整数,最好使用NSArray。
如何把一个整数数组转换伟NSIndexSet:
- NSIndexSet *PSPDFIndexSetFromArray(NSArray *array) {
- NSMutableIndexSet *indexSet = [NSMutableIndexSet indexSet];
- for (NSNumber *number in array) {
- [indexSet addIndex:[number unsignedIntegerValue]];
- }
- return [indexSet copy];
- }
如果不使用block,从索引set中拿到所有的索引有点麻烦,getIndexes:maxCount:inIndexRange:是最快的方法,其次是使用firstIndex并迭代直到indexGreaterThanIndex:返回NSNotFound。随着block的到来,使用NSIndexSet工作变得方便的多:
- NSArray *PSPDFArrayFromIndexSet(NSIndexSet *indexSet) {
- NSMutableArray *indexesArray = [NSMutableArray arrayWithCapacity:indexSet.count];
- [indexSet enumerateIndexesUsingBlock:^(NSUInteger idx, BOOL *stop) {
- [indexesArray addObject:@(idx)];
- }];
- return [indexesArray copy];
- }
NSIndexSet性能
Core Foundation中没有和NSIndexSet相当的类,苹果也没有对性能做出任何承诺。NSIndexSet和NSSet之间的比较也相对的不公平,因为常规的set需要对数字进行包装。为了缓解这个影响,这里的测试准备了实现包装好的NSUintegers,并且在两个循环中都会执行unsignedIntegerValue:
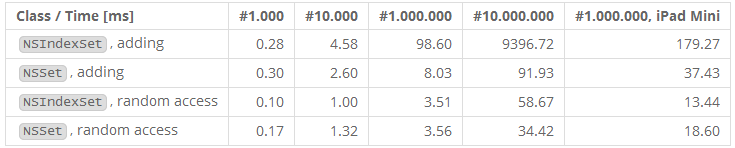
我们看到在一百万左右对象的时候,NSIndexSet开始变得比NSSet慢,但只是因为新的运行时和标签指针。在iOS 6上运行相同的测试表明,甚至在更高数量级实体的条件下,NSIndexSet更快。实际上,在大多数应用中,你不会添加太多的整数到索引set中。还有一点这里没有测试,就是NSIndexSet跟NSSet比无疑有更好的内存优化。
结论
本文提供了一些真实的测试,使你在使用基础集合类的时候做出有根据的选择。除了上面讨论的类,还有一些不常用但是有用的类,尤其是NSCountedSet,CFBag,CFTree,CFBitVector和CFBinaryHeap。