cs231n 卷积神经网络与计算机视觉 2 SVM softmax
linear classification
上节中简单介绍了图像分类的概念,并且学习了费时费内存但是精度不高的knn法,本节我们将会进一步学习一种更好的方法,以后的章节中会慢慢引入神经网络和convolutional neural network。这种新的算法有两部分组成:
1. 评价函数score function,用于将原始数据映射到分类结果(预测值);
2. 损失函数loss function, 用于定量分析预测值与真实值的相似程度,损失函数越小,预测值越接近真实值。
我们将两者结合,损失函数中的参数也是评价函数中的参数,找到将loss function最小化的参数,就找到了最好的评价函数score function。
线性分类的参数化映射
这里首先讨论前面讲的score function, 最简单的实现使用参数将原始数据映射到输出分类的方法就是线性分类,他的方程如下:
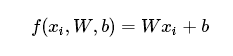
(公式的含义可以直接看后面的一节)
其中的x就是图片的中的数值,上一章节我们提到过一个rgb的图片包含三维数据,这里是将所的所有的数据都展开为1维数据,其中我们需要知道w和b的术语名称:
W:权重 weight ;b 偏差bias vector或者截距intercept
以下是我们需要知道的事情:
1. 多分类中,若有k类结果,那么w就有k行,上面的矩阵方程能很好的同时表达k类的得分;
2. 我们的目标是控制w和b使我们的分类在全局范围内得分尽可能的与真实值相同,我们希望通过最后的函数得到的结果中,真实的类别会得到更大的score;
3. 当我们通过训练数据得到w和b之后,就可以用这些参数方便快捷的对新图片进行预测;
4. 最后,上面的公式在计算大量数据时会比knn等比较的方法更加迅速
线性图像分类的解释
如何才能根据上面提到的线性分类的方程进行分类呢?
主要到其中x是三个颜色通道rgb的展开,其中是各个像素的值,如果我们想根据上面的公式判断一个物体是大海还是草地,按照经验我们希望在蓝色通道代表的值中计算海水分数的权重要大一点,计算草地时,绿色通道的权重要大一些,也就是说可以通过调整参数来使得输出值尽量的与我们想要的分类近似。
下面的例子中,我们要判断一张图片是属于cat、dog、还是ship,假设我们最后的参数如下,得到了三种分类的不同的分数:

可见计算结果更倾向于认为图片是一只狗。
几何解释
上面我们提到过需要把图片展开为一维的数据,如在32x32的数据中,我们每一张图片一共有3072个数值,换一种思路,一张图片=3072个数,那么我们可以认为这张图片是3072维中的一个点,我们要做的分类也成了对点进行分类,为了便于展现,我们在二维空间中用下图表现:

我们需要做个就是建立上面的线性矩阵方程代入之后得到的结果用于分类。
按照上图中所展现的,w控制斜率,b控制截距,如果没有b,那么所有类别分界线都会经过0点。
模板解释
另外一种理解w的方法是将w理解为每一个类别的模板template或者prototype,模板的匹配程度就是利用内积的结果来衡量。下图是通过学习cifar-10得到的template:

上图可以看出我们学到的horse仿佛有两只头,两只头的原因是在数据集中训练集包含向左和向右两种马,也就是说线性分类器将多个形状集合到了一张图片(template)中,而且上面的模板似乎每个物体的颜色都已经确定了,如果是一种白色马则可能与模板相差多一些,也就是说线性分类器不能很好的解释不同的物体的颜色信息。后面我们学习的神经网络会帮我们解决这个问题。
其他
- 我们可以将b与w合并,如下图:

- 图像预处理,上面我们一直使用的是0-255之间的原始数值计算,然而在机器学习中,我们一般会对图像进行规范化,例如可以将各个像素的值减去所有像素的平均值得到范围近似于[-127,127]的新值,更常见的是将他们映射到 [-1, 1]中去. 将数据规范为0均值是非常重要的只不过现在我们暂时不证.
损失函数
上面的论述中我们已经初步明白如何利用w和b建立一个score function,但是还是没有利用我们标定的label值,我们将通过score function得到的值与ground truth相比较,分类结果与真实值越相似越好,我们称这个相似的程度的衡量函数为loss function,预测结果越准确,损失函数值越小。下面我们将学习如何建立一个loss function。
Multiclass Support Vector Machine loss 多分类支持向量机损失函数
SVM loss 的中心思想是,如果正确分类的得分应该比错误分类的得分高,而且至少应该高 Δ .
Let’s now get more precise.上面我们用 f(xi,W)表示第i个图的得分函数,yi表示正确的类别,j表示第j类,这里我们用 sj 表示对应第j类的得分,那么svm loss的表达式如下:
上式可以看出如果正确类别的得分比其他类值大 Δ 时,损失函数就是0,这时候判断正确。如果判断错误那么得到的得分就会比其他的值小,那么得到的损失函数为正值,也就是说如果想损失函数为零那么得到的正确分类的分数必须比其他几类得到的分数大 Δ 。
代入上文中线性分类的得分函数,上式变为:
这里终于实现了我们想要结合score function的参数与loss function的愿望。
上面的 max(0,−)函数经常被称作 hinge loss(合页损失). 有时候我们也可以用 squared hinge loss SVM (or L2-SVM)来代替它,他的表达式是 max(0,−)2 , 它对于错误分类的惩罚更加严厉。到底哪种函数比较好,我们可以用上节提到的cross validation来验证。
规则化
上面的公式其实还有一个bug:按照这个公式得到的值不唯一。假设我们已经得到了一组w可以正确的份额里而且可以使损失函数为0,那么如果我们将w都扩大 λ (>1)倍,那么得到的损失函数依然为0。
但是我们往往希望得到一个确切的最好的参数来是我们快速有效的进行分类工作. 我们可以通过添加一个 regularization penalty来实现. 最常见的是添加二范数。添加惩罚项(规则化)之后的表达式为:
其中的lambda往往可以用交叉验证来选择。
规则化有很多好处,例如在svm中二范数规则化可以得到最大裕量(max margin)可以看Andrew Ng 老师的讲义 http://cs229.stanford.edu/notes/cs229-notes3.pdf。
对参数进行惩罚的一大好处就是可以避免过拟合,避免因为某一个因素或者较大的权重,因为在l2时单个大权重往往得到的惩罚比几个小的加起来都多,(上节中也提到了l1和l2 的区别 http://blog.csdn.net/bea_tree/article/details/51472839#t4)。
另外注意到的是偏差项b,不会对输入的特征的影响力产生作用,所以并没有对b进行规则惩罚。
现在我们已经有了如果评价分类结果的loss function ,那么剩下 的就是如何利用他来求解上面所有的参数了。
其他
- Δ 的选择。上文中我们一直没有讨论 Δ 的取值,实际应用中我们一般取1即可。这是因为Δ 和λ 有着同样的功能:平衡data loss 与regulation loss.试想,如果 Δ 很大,那么我们为了得到较小的loss值,就要取得较大的w值来弥补,而 λ 又可以调整w的值,反之亦然。也就是说不论 Δ 变大或者变小都以用w来弥补,也就是最终的loss function的平衡是w的平衡, λ 可以用来控制它。
- 二分类是多分类的特殊情况
- 实际应用中神经网络往往不可微,这个时候的优化依然可以使用subgradient方法
- 多分类方法One-Vs-All (OVA) (常见些)和All-vs-All (AVA),本文的方法是依据 https://www.elen.ucl.ac.be/Proceedings/esann/esannpdf/es1999-461.pdf的思路
Softmax classifier
softmax是另外一个比较常用的多分类方法,与svm类似,他是将svm的hinge loss变成了cross-entropy loss:
fj代表第j类的得分。下式称作softmax function
可见cross-entropy loss 包含softmax function。下面从两个角度来理解这个loss function
1. 信息论角度。信息论中有个重要的概念叫做交叉熵cross-entropy, 具体这篇论文中有讲解 http://eprints.eemcs.utwente.nl/7716/01/fulltext.pdf。他的公式是:
(这里顺带着写下香农熵的公式:
 )
)
为了便于发现交叉熵与cross-entropy loss的区别,这里再贴一下损失函数的公式:
2. 概率论角度。
概率论角度的理解还是使用 Stanford的UFLDL讲解比较好, 很多细节都有所涉及,概率角度是将求解损失函数看做求解最大似然函数的。
svm vs. softmax
计算过程
下图可以从计算过程的角度来比较SVN和softmax:

softmax的计算结果如果不理解可以看看下面的方程:

结果结果
另外,softmax虽然可以计算出各个类别的概率,但是单独看其概率并没有太大 的意义,因为往往计算的结果与惩罚因子密切相关,例如,未加入 规则项时得到的结果如下:
但是如果加入惩罚项之后,w变的更加均匀,得到的f(w,b)也会变得更加均匀变成下面的结果:
可以看出与svm一样,只有对他们的结果比较排序才有意义。
使用效果performance
二者的作用效果相差不大,单是svm计算的时候只要需要计算的值满足我们设定的 Δ 就会得到loss为0,不再计算他们的具体信息.,比如在第一个类别为真时得到的结果为 [10, -100, -100] 和[10, 9, 9]都满足 margin of 1 所以他们的loss都为0. 单是在softmax中[10, 9, 9] 的可信度要比 [10, -100, -100]小很多,也就是前者的loss要大. 换句话,svm只在乎支持向量附近的内容,在支持向量两侧超过margin的都被肯定或者否定了。
拓展阅读:
Deep Learning using Linear Support Vector Machines from Charlie Tang 2013 presents some results claiming that the L2SVM outperforms Softmax.
总结
- linear classification
- 线性分类的参数化映射
- 线性图像分类的解释
- 几何解释
- 模板解释
- 其他
- 损失函数
- Multiclass Support Vector Machine loss 多分类支持向量机损失函数
- 规则化
- 其他
- Softmax classifier
- svm vs softmax
- 计算过程
- 结果结果
- 使用效果performance
- 总结