Apache Flink数据流的Fault Tolerance机制
简介
Apache Flink提供了一个失败恢复机制来使得数据流应用可以持续得恢复状态。这个机制可以保证即使线上环境的失败,程序的状态也将能保证数据流达到exactly once的一致性。注意这里也可以选择降级到保证at least once的一致性级别。
失败恢复机制持续地构建分布式流式数据的快照。对于那些只有少量状态的流处理应用,这些快照都是非常轻量级的并且可以以非常频繁的频率来构建快照而不需要太多地考虑性能问题。而流应用的状态被存储在一个可配置的持久化存储(比如master节点或者HDFS)。
在程序失败的情况下(比如由于机器、网络或者软件失败),Flink将停止分布式流处理。系统将重启operator并且将他们重置为最新成功了的检查点。输入流会被重置为状态快照点。任何被重启的并发数据流处理的记录,可以得到的保证是:他们不可能是检查点之前的记录。
注意:对于该机制,为了达到完整的保证,数据流source(例如message queue或者message broker)需要具备回退到最近定义的还原点的能力。Apache Kafka具备这样的能力并且Flink的Kafka连接器利用了这个能力。
因为Flink的检查点是通过分布式快照实现的,所以这里我们对快照和检查点不进行区分。
检查点
Flink的失败恢复机制最核心的部分是持续得构建分布式流处理和operator状态的快照。这些快照可以看作持续的检查点,如果发生失败的情况,系统可以从这些点进行恢复。Flink构建这些快照的机制可以被描述成分布式数据流的轻量级异步快照。它已经被实现为标准的Chandy-Lamport算法了,并用来实现分布式快照,而且几乎是为Flink的执行模型量身定做的。
屏障
Barriers:此处统一称为屏障也可称之为栅栏
在Flink的分布式快照机制中有一个核心的元素是流屏障。屏障作为数据流的一部分随着记录被注入到数据流中。屏障永远不会赶超通常的流记录,它会严格遵循顺序。屏障将数据流中的记录隔离成一系列的记录集合,并将一些集合中的数据加入到当前的快照中,而另一些数据加入到下一个快照中。每一个屏障携带着快照的ID,快照记录着ID并且将其放在快照数据的前面。屏障不会中断流处理,因此非常轻量级。来自不同快照的多个屏障可能同时出现在流中,这意味着多个快照可能并发地发生。
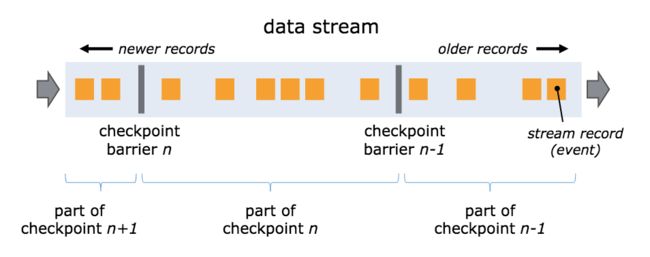
在stream source中,流屏障被注入到并发数据流中。快照n被注入屏障的点(简称为Sn),是在source stream中的数据已被纳入该快照后的位置。例如,在Apache Kafka中,该位置将会是partition中最后一条记录的offset。这个Sn的位置将被报告给检查点协调器(Flink JobManager)。
屏障接下来会流向下游。当一个中间的operator从所有它的输入流中接收到一个来自快照n的屏障,它自身发射一个针对快照n的屏障到所有它的输出流。一旦一个sink operator(流DAG的终点)从它所有的输入流中接收到屏障n,它将会像检查点协调器应答快照n。在所有的sink应答该快照后,它才被认为是完成了。
当快照n完成后,可以认为在Sn之前的记录没有必要再从source中流入,因为这些记录已经穿过了整个数据流的处理拓扑。
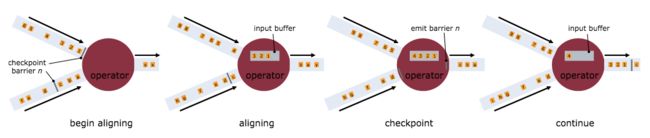
那些不止一个输入流的的operator需要在快照屏障上对齐(align)输入流。上面的插图说明了这一点:
- 一旦
operator从外来流中收到快照屏障n,它就不能处理该流中更多的记录直到它从其他输入中接收到屏障n。否则,会混合属于快照n以及快照n+1的记录 - 汇报过屏障n的流会被临时搁置到一边,从这些流中继续接收到的记录并没有被处理,而是被放进一个输入缓冲区中
- 一旦最后一个流接收到屏障n,
operator发射所有待处理的需要流出的记录,然后发射快照n屏障本身 - 此后,
operator恢复从所有输入流的记录的处理,在处理来自流的记录之前先处理来自输入缓冲区的记录
状态
无论operator包含任何形式的状态,这些状态必须是快照的一部分。operator状态有不同的形式:
- 用户定义的状态:这种类型的状态通过
transformation函数(比如map()或者filter())直接创建和修改。用户定义的状态可以是一个简单的变量或者跟某个函数关联的key/value状态。 - 系统状态:这种状态通常关系到数据缓冲区,它们是
operator计算逻辑的一部分。这种状态的一个典型的例子是window buffers,在它内部,系统为其收集(以及聚合)记录直到窗口被计算。
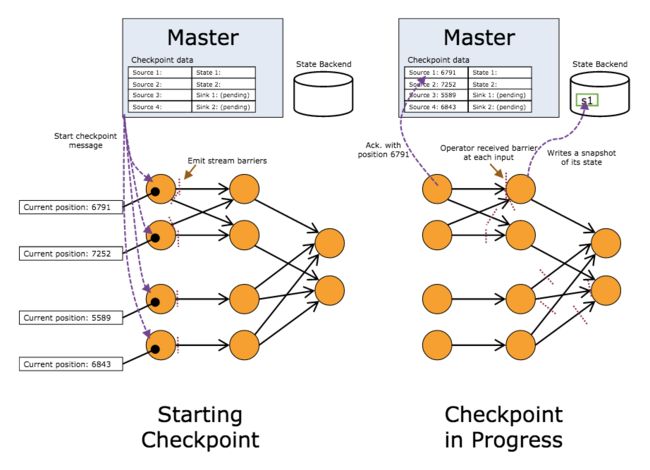
operator在从它们的所有输入流中收到所有的快照屏障时,在发射屏障到它们的输出流之前会对状态做快照。在那个点,所有在屏障之前的记录的状态更新必须完成,并且在屏障之后依赖于记录的更新不会被接收。因为快照的状态有可能会非常大,它们被存储在可配置的状态终端上。默认存储的位置是JobManager的内存,但为了严谨,应该配置一个分布式的可靠的存储层(比如HDFS)。在状态被存储之后,operator会应答检查点,发射快照屏障到输出流并继续处理流程。
现在快照的结果包含:
- 对每个并行流的数据源而言,快照开始时的偏移量或者位置
- 对每个
operator而言,一个指针指向存储在快照中的状态部分

恰好一次VS至少一次
对齐步骤可能会增加流处理的延迟。通常这个额外的延迟被控制在毫秒级,但我们也看到一些场景下,延迟显著增加。对于那些要求针对所有记录的处理始终保持低延迟的应用(比如几毫秒),Flink提供了一个开关(选项)可以在检查点中跳过流对齐。检查点快照仍然被构建,一旦operator从每个输入流收到检查点屏障。
当对齐操作被跳过,operator持续处理所有的输入,甚至在检查点n的一些检查点屏障到达之后。这种情况下,operator在对检查点n进行状态快照之前也可能同时会处理属于检查点n+1的元素。因此,在恢复时,这些记录可能会导致重复,因为它们可能会既包含在针对检查点n的快照中,又将包含在检查点n之后被重放的部分数据中。
注意:对齐仅仅发生在operator有多个前置operator(join)以及operator有多个发送者(在一个流被repartitioning/shuffle之后)。正因为如此,令人尴尬的是,在数据流中仅仅只有一个并行的流操作(map(),flatMap(),filter()…)时,即便在至少一次的模式下也能提供恰巧一次的一致性保证。
恢复
在这个机制下的恢复是很简单的:如果产生了失败,Flink选择最近完成的检查点K。然后系统重放整个分布式的数据流,然后给予每个operator他们在检查点k快照中的状态。数据源被设置为从位置Sk开始重新读取流。例如在Apache Kafka中,那意味着告诉消费者从偏移量Sk开始重新消费。
如果状态被增量地快照,operator从最新的完整快照中读取状态然后在状态上应用一系列的增量快照更新。
本文翻译自:https://ci.apache.org/projects/flink/flink-docs-master/internals/stream_checkpointing.html
微信扫码关注公众号:Apache_Flink

QQ扫码关注QQ群:Apache Flink学习交流群(123414680)
