《C专家编程》:C程序运行时的数据结构(六)
编程语言的经典对立之一就是代码和数据的区别。但是有些语言如LISP把两者视为一体。但是C语言却维持着两者的区别。
代码和数据的区别也可以认为是编译时和运行时的分界线。编译器的绝大部分工作更翻译代码有关,必要的数据存储管理的绝大部分都在运行时进行。
学习运行时系统,主要有三个理由:
(1)有助于优化代码,获得最佳效率;
(2)它有助于理解更高级的材料;
(3)当陷入麻烦时,它可以使分析问题容易;
1、a.out及其传说
当我们在用linux编程的时候就会遇到a.out直接运行可执行程序。
例如有file.c
#gcc -o file.c
那么该文件默认就会产生一个a.out可执行文件。当然如果所有的文件都用默认产生的a.out就会忘记它来自哪一个源文件,因为它会覆盖。
那么为什么会取a.out这个名字呢?
其实它是“assemble output(汇编程序的输出)”的缩写形式!BSD中有文档这样记载:
NAME:
a.out--汇编程序和链接编辑输出格式
但是他不是汇编程序输出,而是连接器输出。并且在PDP-7(甚至比B语言还早)上并不存在链接器。程序是这样创建的:先把所有源文件链接在一起,然后进行汇编,汇编产生的汇编程序输出保存在a.out中。所以说这个程序的产生纯属历史原因。这个名字曾被解释:“新程序准备就绪,打算执行”。缺省使用a.out这个名字是UNIX“没什么理由,但我们就是这样做的”思维的一例。看完这本书讲了很多系统变量的初始值,都是这个思维,以我的理解就是因为书中讲的这些大N都是计算机的鼻祖,是他们发明了计算机和OS,所以他们可以用自己的生日或者喜欢的词语或者数字来定义计算机系统里的一些初始值,前提是合理且对系统没有影响的。这没有原因,就是这么任性,没有办法,因为就是这么定义的。就像是桌子一样,我们不知道它为什么叫桌子,就是这么规定的,从呱呱坠地的那一刻我们就知道它就叫桌子,没有为什么。纯属历史原因!
2、UNIX中和Intel X86架构中段的概念。
在UNIX中,段表示一个 二进制文件相关的内容块;
在Intel X86中, 段表示一种设计结果。在这种设计中(基于兼容性原因),地址空间并非一个整体,而是分成一些64K大小的区域,称之为段。
当在一个可执行文件中运行 size命令时,它会告诉你这个文件中的三个段(文本段、数据段和BSS-Block Started by Symbol(有符号开始的块))
1548 + 4236 + 4004 = 9788
还可以用nm或dump工具来检查可执行文件的内容:
#nm -sx a.out
关于段的概念,比较复杂,在后续文章中会详细介绍,这里就不多做介绍,主要是区分一下他们之间的概念。
3、函数调用时的:过程活动记录
4、控制线程--setjump和longjump
setjump和longjump,因为它们是通过操作过程活动记录实现的。它是c语言多独有的。它弥补了C语言有限的转移能力。
这两个函数协同工作,如下所示:
(1)setjump(jmp_buf j)必须首先被调用。它表示“使用变量j记录现在的位置。函数返回值为0”;
(2)longjmp(jmp_buf j,int i)可以接着被调用。它表示“回到j所记录的位置,让它看上去像是从原先setjmp()函数返回一样,函数返回值为i,是代码能够知道它是实际上是通过longjmp返回的”。
注意:当使用longjmp时,j的内容被销毁。setjmp保存了一份程序的计数器和当前的栈顶指针,如果喜欢也可以保存一些初始值。longjmp恢复这些值,有效地转移控制并把状态重置回保存状态的时候。这被称作“展开堆栈unwinding stack”,因为你从堆栈中展开过程活动记录,直到取得保存在其中的值。尽管longjmp能导致转移,但它和goto又不同。
longjmp和goto的区别:
(1)goto语句不能跳出C语言当前的函数(这也是“longjmp”取名的由来),它可以跳的很远,甚至可以调到其它文件中去。
(2)用longjmp只能跳回到曾经到过的地方。在执行setjmp的地方任然留一个过程活动记录。从这个角度讲:longjmp更像是“从哪儿来,不是往哪儿去”,但是goto语句更像是“往哪儿去”。longjmp接收一个额外的整形参数并返回它的值,这可以知道是由longjmp转移到这里,还是从上一条语句自然运行到这里。
setjmp和longjmp的主要作用是错误恢复。只要还没有从函数返回,一旦发现一个不可恢复的错误,可以把控制转移到主输入循环,并从那里重新开始运行。
实例如下:
first through!
in function!
back in main!
学习运行时系统,主要有三个理由:
(1)有助于优化代码,获得最佳效率;
(2)它有助于理解更高级的材料;
(3)当陷入麻烦时,它可以使分析问题容易;
1、a.out及其传说
当我们在用linux编程的时候就会遇到a.out直接运行可执行程序。
例如有file.c
#gcc -o file.c
那么该文件默认就会产生一个a.out可执行文件。当然如果所有的文件都用默认产生的a.out就会忘记它来自哪一个源文件,因为它会覆盖。
那么为什么会取a.out这个名字呢?
其实它是“assemble output(汇编程序的输出)”的缩写形式!BSD中有文档这样记载:
NAME:
a.out--汇编程序和链接编辑输出格式
但是他不是汇编程序输出,而是连接器输出。并且在PDP-7(甚至比B语言还早)上并不存在链接器。程序是这样创建的:先把所有源文件链接在一起,然后进行汇编,汇编产生的汇编程序输出保存在a.out中。所以说这个程序的产生纯属历史原因。这个名字曾被解释:“新程序准备就绪,打算执行”。缺省使用a.out这个名字是UNIX“没什么理由,但我们就是这样做的”思维的一例。看完这本书讲了很多系统变量的初始值,都是这个思维,以我的理解就是因为书中讲的这些大N都是计算机的鼻祖,是他们发明了计算机和OS,所以他们可以用自己的生日或者喜欢的词语或者数字来定义计算机系统里的一些初始值,前提是合理且对系统没有影响的。这没有原因,就是这么任性,没有办法,因为就是这么定义的。就像是桌子一样,我们不知道它为什么叫桌子,就是这么规定的,从呱呱坠地的那一刻我们就知道它就叫桌子,没有为什么。纯属历史原因!
2、UNIX中和Intel X86架构中段的概念。
在UNIX中,段表示一个 二进制文件相关的内容块;
在Intel X86中, 段表示一种设计结果。在这种设计中(基于兼容性原因),地址空间并非一个整体,而是分成一些64K大小的区域,称之为段。
当在一个可执行文件中运行 size命令时,它会告诉你这个文件中的三个段(文本段、数据段和BSS-Block Started by Symbol(有符号开始的块))
例如:#size a.out
结果显示:
text data bss total1548 + 4236 + 4004 = 9788
还可以用nm或dump工具来检查可执行文件的内容:
#nm -sx a.out
关于段的概念,比较复杂,在后续文章中会详细介绍,这里就不多做介绍,主要是区分一下他们之间的概念。
3、函数调用时的:过程活动记录
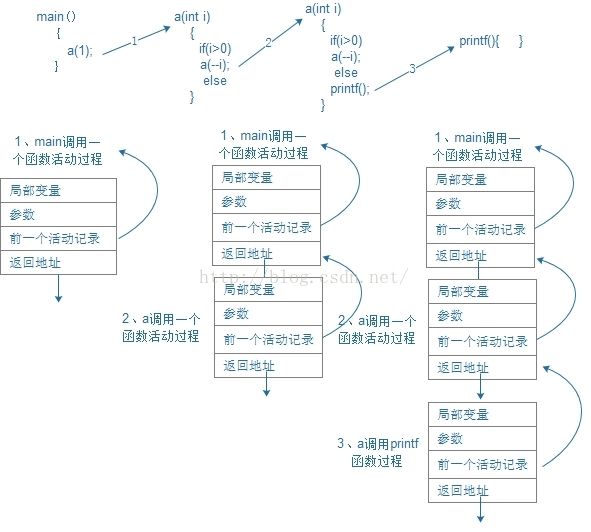
C语言自动提供的服务之一就是跟踪调用链。那些函数调用了那个函数,当return语句执行后,控制将返回何处。解决这个问题的经典机制使堆栈中的过程活动记录。当每个函数调用时,都会产生一个过程活动记录,过程活动记录是一种数据结构,用于支持过程调用。其结构图如下图所示:

4、控制线程--setjump和longjump
setjump和longjump,因为它们是通过操作过程活动记录实现的。它是c语言多独有的。它弥补了C语言有限的转移能力。
这两个函数协同工作,如下所示:
(1)setjump(jmp_buf j)必须首先被调用。它表示“使用变量j记录现在的位置。函数返回值为0”;
(2)longjmp(jmp_buf j,int i)可以接着被调用。它表示“回到j所记录的位置,让它看上去像是从原先setjmp()函数返回一样,函数返回值为i,是代码能够知道它是实际上是通过longjmp返回的”。
注意:当使用longjmp时,j的内容被销毁。setjmp保存了一份程序的计数器和当前的栈顶指针,如果喜欢也可以保存一些初始值。longjmp恢复这些值,有效地转移控制并把状态重置回保存状态的时候。这被称作“展开堆栈unwinding stack”,因为你从堆栈中展开过程活动记录,直到取得保存在其中的值。尽管longjmp能导致转移,但它和goto又不同。
longjmp和goto的区别:
(1)goto语句不能跳出C语言当前的函数(这也是“longjmp”取名的由来),它可以跳的很远,甚至可以调到其它文件中去。
(2)用longjmp只能跳回到曾经到过的地方。在执行setjmp的地方任然留一个过程活动记录。从这个角度讲:longjmp更像是“从哪儿来,不是往哪儿去”,但是goto语句更像是“往哪儿去”。longjmp接收一个额外的整形参数并返回它的值,这可以知道是由longjmp转移到这里,还是从上一条语句自然运行到这里。
setjmp和longjmp的主要作用是错误恢复。只要还没有从函数返回,一旦发现一个不可恢复的错误,可以把控制转移到主输入循环,并从那里重新开始运行。
实例如下:
#include <longjmp.h>
#include <setjmp.h>
#include <stdio.h>
void function()
{
printf("call function!");
longjmp(buf,1);
printf("this will never be show up!\n");
}
int main()
{
jmp_buf buf;
if(setjmp(buf))
printf("back in main!\n");
else
{
printf("first through!\n");
function();
}
}#运行结果:
first through!
in function!
back in main!
setjmp和longjmp在C++中变异为更普遍的异常处理机制“catch”和“throw”。